 The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to make it possible to use Web technologies with different languages, scripts, and cultures.
The W3C Internationalization (I18n) Activity works with W3C working groups and liaises with other organizations to make it possible to use Web technologies with different languages, scripts, and cultures.
From this page you can find articles and other resources about Web internationalization, and information about the groups that make up the Activity.
Read also about opportunities to participate and fund work via the new Sponsorship Program.
What the W3C Internationalization Activity does
Selected quick links
Selected quick links
Selected quick links
First Public Working Draft Published: Requirements for Internationalization Tag Set (ITS) 2.0
Over the past five years since its release in 2007 the Internationalization Tag Set (ITS) has shown itself to be a very powerful tool for simplifying the translation of XML content, but a lot has changed since then as improved technologies to support translation have emerged and we have seen greater levels of integration between content production and translation. As a result new needs have emerged and the W3C’s MultilingualWeb-LT Working Group was formed to develop ITS version 2.0 (ITS 2.0) to respond to these needs.
Requirements for Internationalization Tag Set (ITS) 2.0 gathers metadata categories – essentially items like ways to indicate whether or not specific text should be translated, support for machine translation, and so forth – developed within the MultilingualWeb-LT Working Group. The proposed metadata targets web content (primarily HTML5) and “deep Web” content, such as content stored in a content management system (CMS) or XML files from which HTML pages are generated, that facilitates its interaction with multilingual technologies and localization processes.
In order to ensure that the proposed metadata categories reflect the needs of the organizations that produce and translate content, interested parties should review the document and send comments to public-multilingualweb-lt-comments@w3.org. (You can also join the public discussion list and view its archive). We also invite you to review the issues discussed within the Working Group.
We will discuss the draft at the upcoming MultilingualWeb workshop and plan to publish a new version of the document incorporating public feedback by the end of June 2012, followed by a first draft publication of the ITS 2.0 specification.
(If you are interested in taking a more active role in working on ITS 2.0 you may also register for the Dublin workshop, at no fee, until May 30. See the call for participation for more details.)
Editors: Dave Lewis (TCD), Arle Lommel (DFKI), Felix Sasaki (DFKI/W3C Fellow)
Program published for MultilingualWeb Workshop in Dublin!
The program has been published for the upcoming W3C MultilingualWeb workshop on Linked Open Data and the MultilingualWeb-LT Project Requirements in Dublin, 11–13 June 2012.
Divided into two portions, the first day (11 June) will focus on Linked Open Data. The keynote presentation will be given by David Orban, CEO of dotSUB, who will be followed by a full day of presentations on various aspects of Linked Open Data. The following two days will deal more specifically with development of the MultilingualWeb-LT project’s requirements document. Speakers come from organizations like Adobe Systems, the European Commission, the World Wide Web Consortium, and leading research institutions from around the world.
See the Call for Participation for details about how to register for the workshop. Participation in the workshop is free.
Important: The deadline for registration is May 30. Please be sure to register by then.
The MultilingualWeb workshops, funded by the European Commission and coordinated by the W3C, looks at best practices and standards related to all aspects of creating, localizing and deploying the multilingual Web. The workshops are successful because they attracted a wide range of participants, from fields such as localization, language technology, browser development, content authoring and tool development, etc., to create a holistic view of the interoperability needs of the multilingual Web.
We look forward to seeing you in Dublin!
WG Note published and retired: Web Services Internationalization (WS-I18N)
The Internationalization Core Working Group has reached consensus to stop working on Web Services Internationalization (WS-I18N). It was published as a Working Group Note for archival reasons and is no longer being progressed along the W3C’s Recommendation Track. The only changes to this document since the last Working Draft are the addition of the note just above, and a correction to the links pointing to what was known as the Olson timezone database, which is now hosted by IANA.
MultilingualWeb Dublin speaker deadline extended, don’t delay!
The deadline for submissions to speak at the Multilingual Web – Linked Open Data and MultilingualWeb-LT Requirements in Dublin has been extended until 9 May. We are building a strong program with expected contributions from Adobe, the Centre for Next Generation Localisation, the Italian National Research Council (CNR), the European Commission, Google, and many others, and we will be filling the remaining slots soon.
If you want to speak at the event register as soon as possible.
This MultilingualWeb workshop will be held in Dublin, Ireland, hosted by Trinity College Dublin.
The purpose of this workshop is two-fold: first, to discuss the intersection between Linked Open Data and Multilingual Technologies (11 June), and second, to discuss Requirements of the W3C MultilingualWeb-LT Working Group (12 – 13 June). We expect that both topics will attract an overlapping set of participants, and we hope to increase the overlap by this workshop.
Participation is free. We welcome participation from both speakers and non-speaking attendees. For more information and to register, see the Call for Participation.
Updated Working Draft: Character Model for the World Wide Web 1.0: Normalization
A new version of the Character Model for the World Wide Web 1.0: Normalization was published. The only significant change was a note to clarify that content of the Working Draft is currently out of date, and the Internationalization Core Working Group intends to substantially alter or replace the recommendations found in this document with very different recommendations in the near future.
Just Published! New Version of Working Group Note, Requirements for Japanese Text Layout (日本語組版処理の要件)
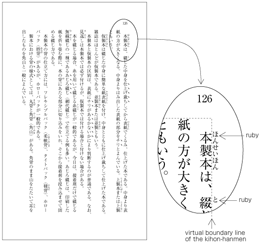
Requirements for Japanese Text Layout describes requirements for Japanese layout realized with technologies like CSS, SVG and XSL-FO. For non-Japanese speakers it provides access to a wealth of detailed and authoritative information about Japanese typesetting. The document is mainly based on a standard for Japanese layout, JIS X 4051 and its authors include key contributors to that standard. However, it also addresses areas which are not covered by JIS X 4051.
This second version of the document contains a significant amount of additional information related to hanmen design, such as handling headings, placement of illustrations and tables, handling of notes and reference marks, etc.
The document was created by the Japanese Layout Task Force (with participation from four W3C Working Groups, CSS, Internationalization Core, SVG and XSL)
A Japanese version is also available.
W3C Workshop, Call for Participation: The Multilingual Web – Linked Open Data and MultilingualWeb-LT Requirements
11 – 13 June 2012, Dublin, Ireland, hosted by Trinity College Dublin.
Organized by the MultilingualWeb-LT Working Group, the purpose of this workshop is two-fold: first, to discuss the intersection between Linked Open Data and Multilingual Technologies (11 June), and second, to discuss Requirements of the W3C MultilingualWeb-LT Working Group (12 – 13 June). For more information, see the Call for Participation.
Participation is free. We welcome participation from both speakers and non-speaking attendees. However, whereas future MultilingualWeb workshops will continue the wide-ranging format of previous MultilingualWeb events, and will aim again at a larger audience, attendees for this workshop are required to participate actively in discussions and will need to submit a position statement for the workshop registration. There are limited spaces available.
The MultilingualWeb Working Group aims to define meta-data for web content (mainly HTML5) and “deep Web” content (for example a CMS or XML files from which HTML pages are generated) that facilitates its interaction with multilingual technologies and localization processes.
New translations into Chinese
Simplified Chinese:
介绍字符集与编码 (Introducing Character Sets and Encodings)
Traditional Chinese:
介紹字符集與編碼 (Introducing Character Sets and Encodings)
These articles were translated thanks to Sun Yuanfu.
Slides and IRC logs for Luxembourg workshop available
The MultilingualWeb Workshop in Luxembourg was another success, thanks once again to the efforts of the excellent speakers and the local organizers. The program included another Open Space discussion organized by TAUS, and a new feature was a number of poster presentations. We had over 130 attendees.
The program page has now been updated to point to speakers’ slides and to the relevant parts of the IRC logs. Links to video recordings will follow shortly.
There are also some links pointing to social media reports, such as blog posts, tweets and photos, related to the workshop. If you have any blog posts, photos, etc. online, please let Richard Ishida know (ishida@w3.org) so that we can link to them from this page.
A summary report of the workshop will follow a little later.
Unicode Consortium CLDR announcements
The Unicode Consortium announced today that the CLDR Survey Tool is open for beta testing. CLDR provides key building blocks for software to support the world’s languages, with the largest and most extensive standard repository of locale data available. The survey tool is an online tool used by organizations and individuals to contribute data to this repository, and to vote on alternative contributions.
The survey tool has undergone substantial revision, with dramatic improvements in performance and usability. The Unicode Consortium would appreciate people trying out the tool so that they can identify any remaining problems before we start data submission (currently scheduled for April 4). More information.
The Unicode CLDR 21.0.1 maintenance release is also now available. See details.
The next major release is CLDR 22, scheduled for late August. The CLDR 22 release does involve general data submission, which will begin soon. See the latest schedule.