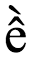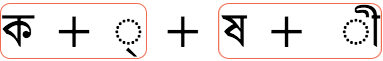Cet article initie à certains concepts de base nécessaires à la compréhension des autres articles qui traitent des caractères et de leurs encodages.
Unicode
Unicode est un jeu de caractères universel, c’est-à-dire qu’il définit en un lieu tous les caractères nécessaires à l’écriture de la majorité des langues vivantes utilisées en informatique. Il vise à devenir, et pour l’essentiel est déjà, un surensemble de tous les jeux de caractères jamais encodés.
Dans un ordinateur, mais aussi sur le Web, les textes sont composés de caractères. Ces caractères représentent les lettres de l’alphabet, la ponctuation ou autres symboles.
De nombreuses organisations ont par le passé assemblé des jeux de caractères variés et créé des encodages pour ceux-ci. Un jeu peut ne couvrir que les langues d’Europe occidentales à caractères latins (en excluant des langues de l’Union européenne, telles que le bulgare ou le grec), un autre jeu peut couvrir une langue d’Asie orientale donnée (le japonais par exemple), d’autres jeux encore ont été conçus pour représenter de manière appropriée d’autres langues utilisées ailleurs dans le monde.
Il n’est malheureusement pas possible de garantir qu’une application prendra en charge tous les encodages possibles, ou même qu’un encodage donné répondra aux besoins de représentation d’une langue donnée. Il est de plus normalement impossible de combiner des encodages différents sur une page Web donnée ou encore dans une base de données et il est ainsi extrêmement difficile de prendre en charge des pages multilingues avec des méthodes d’encodage anciennes.
Le Consortium Unicode offre un jeu de caractères unique et de grande taille qui vise à inclure tous les caractères nécessaires à tous les systèmes d’écriture du monde, y compris les écritures anciennes telles que le cunéiforme, le gothique et les hiéroglyphes égyptiens. Ce jeu de caractères est maintenant fondamental pour l’architecture du Web et les systèmes d’exploitation et est pris en charge par la majorité des navigateurs web et autres applications. Le Standard Unicode décrit par ailleurs les propriétés et algorithmes requis pour travailler avec les caractères.
Cette approche facilite considérablement la gestion des pages et systèmes multilingues et offre une bien meilleure réponse aux besoins que la plupart des anciens systèmes d’encodage.
Voici une illustration des blocs d’écriture Unicode dans sa version 5.2 :
Les 65 536 premières positions de points de code dans le jeu de caractères Unicode sont considérées comme constituant le Plan multilingue de base (Basic Multilingual Plane - BMP). Le BMP inclut la plupart des caractères les plus courants.
Le nombre 65 536 correspond à 2 à la puissance 16, en d’autres termes, c’est le nombre maximal de permutations que l’on peut obtenir avec 2 octets.
Le jeu de caractères Unicode dispose également d’espace pour approximativement un million de positions de points de code supplémentaires. Ces caractères sont appelés les caractères supplémentaires (supplementary characters).
Jeux de caractères, jeux de caractères codés, encodages.
Il est important de distinguer clairement entre le concept de jeu de caractères et celui d’encodage de caractères.
Un jeu de caractères ou répertoire comprend l’ensemble des caractères que l’on souhaite utiliser dans un but donné, que ce soit les caractères nécessaires à la prise en charge des langues d’Europe occidentale dans un ordinateur, ou ceux qu’un enfant chinois doit apprendre à l’école primaire (sans aucun rapport avec les ordinateurs).
Un jeu de caractères encodé est un jeu de caractères dans lequel un numéro unique a été associé à chaque caractère. On appelle point de code l’unité d’un tel ensemble et valeur du point de code la position du caractère dans cet ensemble. Par exemple, le point de code pour la lettre á dans le jeu de caractères encodé Unicode a pour valeur 225 en notation décimale et 0xE1 en notation hexadécimale. Remarquons que la notation hexadécimale est fréquemment utilisée pour se référer à des valeurs de points de code et sera adoptée ici. Un point de code Unicode peut avoir une valeur comprise entre 0x0000 et 0x10FFF.
On appelle également pages de code les jeux de caractères encodés.
Un encodage de caractères est une méthode pour associer les jeux de caractères encodés à des octets pour manipulation dans un ordinateur. L’image ci-dessous illustre la manière dont les caractères et les points de code en écriture tifinagh (berbère) sont associés à des séquences d’octets en mémoire à l’aide de l’encodage UTF-8. Les valeurs de point de code pour chaque caractère sont données directement sous le glyphe du caractère (c.-à-d sa représentation graphique) au sommet du diagramme. Les flèches montrent comment les valeurs de point de code sont associées à des séquences d’octets représentés par un nombre hexadécimal à deux chiffres. On remarque que les points de code du tifinagh sont associés à trois octets, mais que le point d’exclamation est associé à un seul octet.
Ces explications ne font que survoler une partie de la terminologie en rapport avec les encodages. Vous pouvez trouver plus d’informations dans le Unicode Technical Report #17.
Un jeu de caractères, plusieurs encodages. De nombreux standards d’encodage de caractères, tels que ceux de la série ISO 8859, utilisent un seul octet pour chaque caractère. L’encodage est alors une association simple avec la position scalaire du caractère dans le jeu de caractères encodé. Par exemple, dans le jeu de caractères encodé ISO 8859-1 la lettre A est en 65e position (à partir de zéro) et pour sa représentation dans l’ordinateur est encodée à l’aide d’un octet dont la valeur est 65. Pour le jeu de caractères encodé ISO 8859-1, cette valeur ne change jamais.
Pour Unicode, cependant, les choses ne sont pas aussi simples. Bien que le point de code pour la lettre á dans le jeu de caractères encodé Unicode est 225 (en notation décimale), en UTF-8 et dans l’ordinateur elle est représentée par deux octets. En d’autres termes, pour un caractère donné il n’existe pas d’association simple biunivoque entre sa valeur dans le jeu de caractères encodé et sa valeur encodée.
De plus, en Unicode, il existe plusieurs méthodes d’encodage pour un même caractère. Par exemple, la lettre á peut être représentée par deux octets dans un encodage et par quatre dans un autre. Les formes d’encodage utilisable avec Unicode sont appelées UTF-8, UTF-16 et UTF-32.
UTF-8 utilise 1 octet pour représenter les caractères du jeu ASCII, deux octets pour les caractères de certains autres blocs alphabétiques et trois octets pour le reste du BMP. Les caractères supplémentaires utilisent 4 octets.
UTF-16 utilise 2 octets pour tous les caractères du BMP et 4 pour les caractères supplémentaires.
UTF-32 utilise 4 octets pour tous les caractères.
Dans la table suivante, la première ligne représente la position du caractère dans le jeu de caractères encodé Unicode. Les autres lignes donnent la valeur des octets utilisés pour représenter le caractère dans l’encodage de caractères indiqué.
Pour XML et HTML (à partir de la version 4.0) le jeu de caractères du document est défini comme étant le « Jeu de caractères universel » (Universal Character Set - UCS) défini par ISO/EIC 10646 et par le standard Unicode (par souci de simplicité, et en accord avec la pratique courante, UCS est tout simplement appelé Unicode).
Ceci veut dire que le modèle logique qui décrit la manière dont XML et HTML sont traités est défini sur la base du jeu de caractères défini par Unicode (en d’autres termes, les navigateurs convertissent en interne tout le texte en Unicode).
Ceci ne veut pas dire que tous les documents HTML ou XML doivent utiliser un encodage Unicode, mais que ces documents ne peuvent contenir que des caractères définis par Unicode. N’importe quel encodage peut être utilisé pour ces documents tant que celui-ci est déclaré de manière appropriée et qu’il représente un sous-groupe du répertoire Unicode.
Bien que dans cet article nous ayons utilisé le terme « caractère » sans le définir vraiment, ce dernier est utilisé ici de manière abstraite et relativement vague pour faire référence au plus petit élément d’une langue écrite à valeur sémantique. Cependant, le terme est souvent utilisé avec des significations différentes dans d’autres contextes et peut faire ainsi référence à la représentation visuelle, logique ou octale d’une partie donnée de texte. Sans définir de manière explicite ce qu’il représente, le terme est ainsi trop imprécis pour l’utiliser lors de la spécification d’algorithmes, de protocoles ou de formats de documents. Dans ces contextes et dans un sens technique, il est recommandé d’utiliser le terme « caractère » comme synonyme de point de code (voir ci-dessus).
Comme nous l’avons montré dans les exemples précédents, il est très important de ne pas oublier qu’en Unicode les octets ne sont équivalents à des caractères que dans de très rares cas.
Cependant, et en particulier dans les systèmes d’écriture complexes, ce qu’un utilisateur perçoit comme étant le plus petit élément de son alphabet (ce que nous appellerons caractère perçu par l’utilisateur) peut en fait être une séquence de points de code. Par exemple, la lettre vietnamienne ề sera perçue comme étant une seule lettre même si la séquence sous-jacente de points de code est U+0065 LATIN SMALL LETTER E + U+0302 COMBINING CIRCUMFLEX ACCENT + U+0300 COMBINING GRAVE ACCENT. De manière similaire, un locuteur bengali peut considérer comme une seule lettre la séquence ksha (ক্ষ), composée de U+0995 BENGALI LETTER KA + U+09CD BENGALI SIGN VIRAMA + U+09B7 BENGALI LETTER SS.
Il est souvent important de tenir compte de ces caractères perçus par l’utilisateur. Pour différentes modifications telles que les sauts à la ligne, le mouvement du curseur, la sélection, l’effacement, etc., il est par exemple fréquent de considérer comme une seule unité certaines combinaisons de points de code. Cela poserait des problèmes si une sélection effectuée par l’utilisateur omettait accidentellement certaines parties des lettres susmentionnées ou si un saut à la ligne séparait un caractère de base des caractères combinés qui le suivent.
Afin d’approximer les unités de caractères perçus par l’utilisateur pour de telles opérations, Unicode définit des ensembles de graphèmes, séquences adjacentes de points de code qui peuvent être considérés comme une unité par les applications traitantes, à l’aide d’un ensemble de règles généralisées. Un caractère alphabétique simple comme e est un ensemble de graphèmes au même titre que toute combinaison d’un caractère de base et des caractères combinés qui le suivent, tel que ề présenté plus haut.
Deux types d’ensembles de graphèmes sont en fait définis par le Unicode Standard Annex #29: Text Segmentation : les ensembles de graphèmes étendus et les ensembles de graphèmes anciens. Nous utilisons ici le terme « ensemble de graphèmes » dans sa première acceptation et il n’est pas recommandé d’utiliser la seconde.
Caractère perçu par l’utilisateur
Décomposition (possible) et frontières de l’ensemble de graphèmes
Les règles relatives aux ensembles de graphèmes sont cependant limitées. Par exemple, ces règles séparent en deux ensembles de graphèmes adjacents le caractère bengali kshī (ক্ষী) perçu par l’utilisateur, au lieu d’envelopper la syllabe orthographique dans son ensemble. Les applications qui doivent travailler en bengali sur des caractères perçus par l’utilisateur devront donc appliquer des règles spécifiques à ce système d’écriture.
Caractère perçu par l’utilisateur
Décomposition et frontières de l’ensemble de graphèmes
L’unité appropriée pour une opération de modification de texte dépend parfois de l’opération. Par exemple, si vous utilisez la touche Retour en arrière sur le mot hindi हूँ (U+0939 DEVANAGARI LETTER HA + U+0942 DEVANAGARI VOWEL SIGN UU + U+0901 DEVANAGARI SIGN CANDRABINDU) l’application va en général effacer en premier les deux caractères combinés, puis la base. Cependant, si vous effacez vers l’avant quand le curseur est à gauche du mot, la plupart des applications effaceront la totalité de l’ensemble de graphèmes en une fois.
Pour faire référence à une unité de texte indivisible dans un contexte donné, CSS utilise le terme unité de caractère typographique. La définition de cet objet dépend de l’opération à réaliser. Avec l’exemple du ề ci-dessus, nous aurions une unité de caractère typographique en effaçant vers l’avant, mais trois en effaçant vers l’arrière. Les unités de caractères typographiques fonctionnent même dans le cas du ksha bengali, ce que les ensembles de caractères ne peuvent actuellement pas faire. C’est l’application et non pas des règles définies au préalable qui détermine non seulement ce que constitue une unité de caractères typographique dans une langue donnée, mais également le contexte de modification.
Caractères et glyphes
Une police de caractères est une collection de glyphes. Dans les cas simples, un glyphe est la représentation visuelle d’un point de code. Le glyphe utilisé pour représenter un point de code dépendra de la police utilisée et de ses caractéristiques : gras, italique, etc. Dans le cas d’émoji, le glyphe utilisé dépendra de la plateforme.
Un point de code unique peut être représenté par plus d’un glyphe et un glyphe unique peut représenter plusieurs points de code,
Les émojis sont un exemple de la relation complexe entre les points de code et les glyphes.
Le caractère émoji pour « famille » a le point de code suivant en Unicode : 👪 [U+1F46A FAMILY]. Il peut également est formé à l’aide de la séquence de points de code : 👨👩👦 [U+1F468 U+200D U+1F469 U+200D U+1F466]. La modification ou l’addition d’autres caractères émoji peut modifier la composition de la famille. Par exemple, la séquence 👨👩👧👧 [U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F466] a pour résultat le glyphe émoji composé « famille : homme, femme, fille, garçon » sur les systèmes qui acceptent ce genre de composition. Un grand nombre d’émojis peuvent être formés exclusivement à l’aide de séquences de points de code tout en devant être considérés comme étant perçus par l’utilisateur en tant que caractère unique lors de l’affichage ou du traitement du texte.
Séquences d’échappement
Une séquence d’échappement est une manière de représenter un caractère sans utiliser le caractère lui-même.
Par exemple, il est impossible de représenter directement le caractère hébreu א dans votre document si vous utilisez un encodage ISO 8859-1, qui ne couvre que les langues d’Europe occidentale. Pour inclure ce caractère dans un fichier HTML, il est possible d’utiliser la séquence d’échappement א. Comme le jeu de caractères du document est Unicode, l’agent utilisateur devrait être capable de reconnaître cette chaîne comme représentant le caractère hébreu aleph.
Quand un serveur vous envoie un document, celui-ci envoie généralement des informations supplémentaires. Ces informations sont les en-têtes HTTP. Voici un exemple du type d’informations relatives au document transmis par l’en-tête HTTP avec le document dans son voyage du serveur vers le client.
La deuxième ligne à partir du bas dans cet exemple inclut l’information sur l’encodage de caractères pour le document.
HTTP/1.1 200 OK
Date: Wed, 05 Nov 2003 10:46:04 GMT
Server: Apache/1.3.28 (Unix) PHP/4.2.3
Content-Location: CSS2-REC.en.html
Vary: negotiate,accept-language,accept-charset
TCN: choice
P3P: policyref=http://www.w3.org/2001/05/P3P/p3p.xml
Cache-Control: max-age=21600
Expires: Wed, 05 Nov 2003 16:46:04 GMT
Last-Modified: Tue, 12 May 1998 22:18:49 GMT
ETag: "3558cac9;36f99e2b"
Accept-Ranges: bytes
Content-Length: 10734
Connection: close
Content-Type: text/html; charset=UTF-8
Content-Language: en
Si votre document est créé de manière dynamique à l’aide de scripts, il vous est peut-être possible d’ajouter vous-même et de manière explicite ces informations aux en-têtes HTTP. Si vous servez des fichiers statiques, le serveur pourra associer cette information à ceux-ci. La méthode de paramétrage d’un serveur pour qu’il transmette les informations relatives à l’encodage de cette manière dépend du serveur. Vérifiez auprès de votre administrateur.
Par exemple, les serveurs Apache fournissent en général un encodage par défaut qui peut être normalement ignoré par des paramétrages par dossier. Un webmestre peut ajouter la ligne suivante au fichier .htaccess pour servir tous les fichiers avec une extension .html en tant que UTF-8 dans le dossier courant et tous ses dossiers enfants.