See also: IRC log
<eparsons> trackbot, start meeting
<eparsons> Morning All...
<phila> jtandy: We need to head for a vote on the BP doc at 10:45 (1:40 from now)
<phila> scribe: phila
<scribe> scribeNick: phila
jtandy: So I want to go through
the issues before then.
... Identify what needs to be done
<SimonCox> What is password for Webex please?
phila: I'll do the diff
<ByronCinNZ> present#
jtandy: /me sdw
... Use of DCAT is an issue that has been discussed
... I'd like to begin discussion on one of Clemens' issues
yesterday - how rich models in GML Application Schema can be
found into the way we're proposing.
... Where are the OGC GML community, RDF-SemWeb and Web/JSON
communities
... JSON-LD has the potential to bridge some of that
... those conversations will be helpful for our readers when
deciding what to do next.
... In 2nd session today, I want to take on the list of planned
stuff.
eparsons: The stuff before the vote, is that necessary before the vote?
jtandy: Just the first one
... People might be calling in for the vote
... So we need to go through...
jtandy: Pull request 453
-> https://github.com/w3c/sdw/pull/453 relevant PR
jtandy: Bart had put in something
to BP4...
... the spatial data indexing one
... Some proposals about how you might use R2RML to auto
generate your RDF. I deleted it because I was over
zealous
... Seeing an RDF bias in the doc. But I think it probably is a
useful tool for generting the HTMl content from the underlying
data
... But PR 453 there are also other changes.
... So I'm suggesting that we hold over to the next release for
the end of January - effectively 4 weeks away.
<SimonCox> Also see pull request #451 (which is a very small addition - link to official epsg registry
SimonCox: There's another PR from
myself but it's tiny
... But it riases the issue of making suggestions through
official channels, They can easily get left behind if not acted
on quickly
jtandy: Your PR is 451 https://github.com/w3c/sdw/pull/451
... I assumed your PR was related to SSN
SimonCox: So that's part of the prob. I should have prefixed it with 'BP'
jtandy: If I look at your commit... would you be content to hold that the next release in January?
SimonCox: My concern is that the
ref to EPSG is missing
... It's just an addition to a paragraph.
jtandy: I'm happy to take that now.
SimonCox: It's teeny
<AndreaPerego> +1
<ByronCinNZ> +1
<SimonCox> Apologies for not prefixing my pull request 'BP'
<Linda> +1
[NOTUC]
<LarsG> +1
jtandy: PR 451 is merged
kerry: Back with PR 453
... Bart's one... it's one of those tiny things I'd like to
adopt.
jtandy: Which commit is that?
<kerry> https://github.com/w3c/sdw/pull/453/commits/30ea668402f383fff035dc8ee4604ca45b1bace7
<SimonCox> Clearly pull-requests should be very granular
kerry: It's a new image
jtandy: I'm happy to accept that commit. I'll figure out how to get that commit in without the other stuff in the PR
phila: How do we avoid asking editors to unpick multi-commit pull requests
jtandy: Try and make one PR for commit
SimonCox: Clarifying... PRs
should be at the granularity of the issues to be considered.
But it means that each PR needs to be on the re-based doc
... otherwise they stack anyway.
jtandy: It depends if they're in
the same location in the doc.
... If you focus on a section, you should be able to merge them
independently.
kerry: I want to extend Jeremy's
proposal a little.
... This isn't only a BP issue. We've had the same with the SSN
doc.
... Same argument applies
... Please do things specifically in your commits and PRs
jtandy: If there are merge
conflicts, as an editor, I'm going to bounce your pull request,
unless it's my fault for leaving it for so long.
... Did you have your say about Bart's pull request,
Kerry?
... Largely we're content to wait materially 4 weeks for his
edits to come into the doc.
ClemensPortele: This is very minor, it can wait.
jtandy: I'd like to record thanks to everyone who has made pull requests and contributions
jtandy: We're talking about the
order of the BPs. the Metadata one comes first.
... We said that once we had the BPs we want, we'll probably
shuffle them into the order that we want. Expect a Post-It note
session
<Zakim> phila, you wanted to talk about Bp numbering
jtandy: Are you happy for me to update the StoD section to say that numbers may change
[NOTUC]
DWBP BP numbers changed at CR, I need to check them.
<scribe> ACTION: phila to check references to DWBP are all correct, based on PR numbering [recorded in http://www.w3.org/2016/12/16-sdw-minutes.html#action01]
<trackbot> Created ACTION-237 - Check references to dwbp are all correct, based on pr numbering [on Phil Archer - due 2016-12-23].
jtandy: No vote needed to make
those changes
... So Phil will add the diff
phila: Yes, but not the change history section that is up to the editors.
jtandy: Does anyone have any other issues that prevent us going for a release vote?
<AndreaPerego> No issues from my side.
[NOTUC]
jtandy: So we're content to release but we'll do the formal vote at the time we agreed (10:45Z)
jtandy: This relates to BP1
ByronCinNZ: I had a conversation
with ClemensPortele on this
... It just needs a little more discussion I think.
... Main thing that guides my thinking... the full 19115
metadata cf. more compact CKAN like metadata
... The issue there is, don't lose the full richness.
... SDI is presented as a monolithic thing which is not very
friendly. DCAT seems a nice way around that. Calling DCAT an
exo-skeleton.
... It's the data that you put onto the Web.
... We don't have many examples of this in the wild, which is
an issue.
... the BP says we need the full metadata; it needs to be
discoverable. DCAT would be an example, but not perhaps the
only one
ClemensPortele: We discussed the
significance of it being the first BP
... mostly what it lists is DCAT. I'm not questioning the
tech/approach. I don't have experience of DCAT.
... But it's one approach. ISO19115 has good and bad. We have
DCAT, we have the shcema.org for datasets https://www.w3.org/community/schemaorg4datasets/
... we're giving a preference for DCAT and it's currently not
the top dog. It's top in government data portals
... I'm asking for balance, not exclusion.
eparsons: +1 to Clemens
... DCAT is a valid tech but it's one of many. For now it's
wrong to say it's a BP.
byron: I'd like to get at what's
behind DCAT
... Exposing it the Web in different ways
... ISO 19115 isn't in the same category as DCAT
... DCAT can wrap around it and expose it.
... There are the folk systems, CKAN etc.
jtandy: Thanks Byron
... I think what Byron said - where you've got good metadata,
use it
Byron: yes, don't lose it
<Zakim> phila, you wanted to comment on DCAT
<AndreaPerego> +1
<eparsons> phila : Recent workshop on DCAT...
<AndreaPerego> https://www.w3.org/2016/11/sdsvoc/
<eparsons> phila: Agree with Byron use ISO if you have it, schema.org if you want to appear on web search..
phila: You need different
metadata for different purposes.
... Use schema.org for discovery, 19115 for SDIs etc.
<eparsons> phila: different metadata approaches meet different community needs
AndreaPerego: I agree with
Byron
... The use of DCAT for enabling cross-domain, cross sector
interop
... DCAT is mainly adopted by government data catalogues. But
also potential for use outside that.
... DCAT is extensible.
... The work around GeoDCAT-AP are not just used in the public
sector but people using geospatial data
... I can also report on work in one of our catalogues. We have
spatial data, bilogical, statistical data
... trying to use DCAT for providing consistent implementation
of research data as well
... The scope of the WG is important. Lots of possible
solutions
<AndreaPerego> E.g., about using DCAT for multi-disciplinary research data: https://www.w3.org/2016/11/sdsvoc/SDSVoc16_paper_27
jtandy: I think you said - the
advantage with DCAT is its extensibility. So GeoDCAT can
support spatial, other Aps can add their bits in too.
... so DCAT provides a home for lots of different
metadata
... I think this is what Byron was saying. One of the
advantages of DCAT is that it allows you to bring together
metadata from different domains.
<Payam> +q
eparsons: Yes, what are the approaches for making the metadata itself more accessible on the Web without throwing anything away
Linda: What I got from the SDSVoc
workshop was that metadata serves different purposes. For
spatial, the most important is the coverage. Where is the data
about.
... If it's about your area of interest then you need more,
things like resolution. The BPs could reflect that better
... When you talk about metadata for discovery then you should
use schema.org and then DCAT or similar for judging if the data
is useful -
ClemensPortele: Evaluation
<AndreaPerego> +1 to Linda. SDW BP can help address the current gaps in DCAT and existing vocs.
Payam: I agree with this discussion. We should also give attention to dynamic data. We need to think about streams etc.
<Zakim> phila, you wanted to talk about DCAT structure
<eparsons> +1 to Payam dynamic feeds are important
jtandy: I personally don't
distinguish between a static dataset and a stream. We'd create
a landing page
... then an API etc.
<AndreaPerego> s/Whewn/When/
jtandy: We should perhaps mention that in the BP doc
phila: DCAT has been successful. Needs extension exactly as being discussed here. Main contribution os difference between dataset anda distribution
AndreaPerego: You can bring
spatial data.. you don't need to model everything
... The trade off between providing a full representation, 1-1
mapping etc.
... Don't need to move to another way of saying the same thing.
On the Web Platform, the use cases are different so provide
different metadata.
ChrisLittle: Following from Payam. ISO 19115... distinguishes between streaming and static
<Payam> +q
jtandy: I think schema.org has dataFeed as sub class of dataset
<eparsons> thanks LarsG !!
<Linda> https://schema.org/DataFeed
ClemensPortele: I think I started
that discussion. I agree with what has been said If we provide
this context, classify where schema.org and DCAT have their
uses, that will greatly benefit the BP
... and will address my issue
<AndreaPerego> +1
Payam: If I use this phone, I can
publish data from my phone, most of the data we talk about are
large, but there are lots of small bits of data.
... from IoT devices etc. Do we tell people the best way to
publish those small amounts of data.
eparsons: I don't think we
specifically address that use case. But by saying publish as
graularly as you can - it allows you to build those sorts of
applications.
... We have to recognse what the user community is trying to
do, we can't address all communities.
... We're saying if you're coming from an SDI, this is what you
need to so. And what we're saying is how to make data more
structured.
jtandy: telling people how to publish streaming data is out of scope I think for us - but it needs doings
phila: (another WG... talk to Dave Raggett)
ByronCinNZ: We have a bit of work
going on... one of the AU/ZN collaboration is around crowd
sourced data.
... The tough thing is trust
... and how do you model that and trust it
jtandy: Issues of trust and quality get rolled together. But they're two separate things
eparsons: What have you come up with?
ByronCinNZ: I have some stuff I
can throew in from different places.
... The trust element is about the person/instrument submitting
the data.
... You can qualify the trust on various axes
... On the fact of what needs to be captured. If two people
submit the same item, can you detect that?
... Mostly it's on the submitters
<Zakim> phila, you wanted to talk about DQV
ByronCinNZ: I could get some examples and input
-> https://www.w3.org/TR/vocab-dqv/ Data Quality Vocab
Payam: These are all interesting
and relevant. Fukishima was a good example
... People were reporting very different readings from the same
locations.
... Maybe we should publish info on how to publish and
calibrate their data
... Is that part of the BPs
ChrisLittle: The data might be
highly variable
... it's not wrong. Rainfall is very noisy
jtandy: Publication of radiation data after Fukishima is a good one
eparsons: Things that are close to each other are expected to be similar - that's a spatial data phenomenon.
jtandy: I ask the Wg whether we should go to crowd sourcing
Linda: I was going to say that
this BP is one of the most important ones.
... I see it as ... use cases like navigation data sharing is a
great use case
... For me it didn't have a very high priority - that's why
it's at the end.
... I'm feeling that most f us do want to include it.
... And if you do, please take charge of this BP
jtandy: The crowdsourcing one is
currently under 'other' - where else might it go?
Metadata?
... We need to give it a home. It doesn't have one yet.
... If we scope it to just publishing spatial data from the
crowd, rather than anything else that might happen further down
the stream?
... It's not the top priority.
eparsons: I don't think we should
be tallking about this at all. It's not specifically
spatial.
... It's the same as the current discussion about fake news.
It's a much broader topic than just spatial data.
... The whole issue of provenance, quality, reliability - it's
more than we can take on.
jtandy: I like strong chairing...
Payam: I agree
... It's good to keep this though. It's good to tell them that
they need to be aware of trust data.
... We should just say be aware, without trying to solve the
whole thing.
<Payam> +q
ClausStadler1: I went to a
project kick off recently. If there was a BP it would be
usefeul. The project has only just started
... we can encourage the publication of all the provenance data
for trust evaluation
... Also relevant for crowd source data is privacy
ByronCinNZ: This is a good conversation. Maybe we need to flip this on its head. Do we have anywhere else that we talk about provenance?
Payam: What Claus said reminded me... there's a BBC programme about Weather Watchers... BBC forecast has become bad thanks to people sending in crowd sourced data
ClausStadler1: Crowd sourcing platforms, Amazon Turk etc, might be mentioned
jtandy: Summarising... we
recognise that it's not the broader issue of crowd sourtcing
and trust that we're concerned about, but that when we publish
spatial data wew include metadata that indicates where it comes
from.
... We say this in BP1
... It may only be one tweet, but you need to capture where it
came from.
eparsons: That's true of all data.
jtandy: It's one line.
... I'm suggesting that we include a crowd source example in
the metadata BP
... rather than havae a BP on crowd sourcing
... That doesn't mean we're not interested in what ByronCinNZ
is talking about, just that it's stretching our scope?
<Zakim> phila, you wanted to talk about horizontal review
jtandy: What do we think about a crowd sourcing example in the BP 1 example
phila: Talked about need for horizontal reviewsa
Linda: We mention provenance in
BP2, and in the intro section 13.1
... There's a reference to DWBP where provenance was described.
So it's a more general data on the Web topic
... Having said that, we can include an example of crowd
sourcing.
eparsons: So back to Jeremy's
suggestion of using a crowd sourcing example as a way to say
we're interested. But I don't think there's anything different
about spatial data on this.
... There's a whole space that we haven't touched on. Policy
and legal issues, PII etc.
... Thayt's a scary place
<kerry> +1 there is nothing spatial about crowsdsourceing --- but we do have a use case....
eparsons: Might get into very deep problems
phila: Quotes from DWBP Intro "Not all data and metadata should be shared openly, however. Security, commercial sensitivity and, above all, individuals' privacy need to be taken into account. It is for data publishers to determine policy on which data should be shared and under what circumstances. Data sharing policies are likely to assess the exposure risk and determine the appropriate security measures to be taken to protect sensitive data, such as secure
authentication and authorization."
jtandy: We have a scope section
in our doc - section 3
... Could you write a paragraph, Ed?
action eparsons to create a paragraph for section 3 to highlight that privacy issues etc. are particularly important for crowd sourced data but it's not specifically spatial data and so we dopn't cover it in detail.
<trackbot> Created ACTION-238 - Create a paragraph for section 3 to highlight that privacy issues etc. are particularly important for crowd sourced data but it's not specifically spatial data and so we dopn't cover it in detail. [on Ed Parsons - due 2016-12-23].
<kerry> ACTION: eparsons to write a bit on being warying of crowdsourced data in the scope section 3 -- can reuse from DWBP [recorded in http://www.w3.org/2016/12/16-sdw-minutes.html#action02]
<trackbot> Created ACTION-239 - Write a bit on being warying of crowdsourced data in the scope section 3 -- can reuse from dwbp [on Ed Parsons - due 2016-12-23].
jtandy: I think we're moving to strike BP17, but retain things from it that we think might be useful
close action-238
<trackbot> Closed action-238.
<scribe> ACTION: jtandy to remove BP17 from the doc, retaining pertinent info about privacy crowdsourcing etc. See also action-239 [recorded in http://www.w3.org/2016/12/16-sdw-minutes.html#action03]
<trackbot> Created ACTION-240 - Remove bp17 from the doc, retaining pertinent info about privacy crowdsourcing etc. see also action-239 [on Jeremy Tandy - due 2016-12-23].
jtandy: I propose we draw a close to the discussion on crowd sourcing. 20 mins to voting period
Byron: The issues is that there
are several sections on CRS
... It just needs a little work.
... Not sure that the tone of them agree. It looks as if they
could be consolidated.
... That was more a comment than anything else.
jtandy: Section 7 is 1.5 A4
pages...
... Our hope was to introduce the topic of CRSs and
projections
... SO non-geo people might see it's something to pay attention
to.
... One can argue that's useful info, but does it go before the
BPs
eparsons: We clearly need to deal
with the issue. Not sure that section 7 is the best wayu to do
it.
... Our community falls into making things complicated.
... For the vast majority, it's not an issue. The default
works. Publishing the location of shop,s where to meet etc.
it's not important.
... But it is important for some of the communities we deal
with
jtandy: I agree - the CRS stuff
isn't hitting the mark yet.
... Payam and I wrote much of section 7. There is a small
community where it matters.
... Maybe some of that info could be in an annexe
eparsons: I thought I saw a section was much more Q&A style
Byron: BP3 and 18 both have that style
eparsons: I think if you have that sort of approach. If you're doing this sort of data, don't worry about this, but with other data, you need to worry about that.
Byron: The issue of CRS is more
on end user than publishers
... Drawing a circle on a map, OK, but draw it on the ground it
will be different with different projections
eparsons: For most people, the fact that you can't draw a circle in a Web Mercator projection - does it matter?
Byron: Well if you're worrying
about alerting people along a coast for an oncoming Tsunami -
yes.
... A classic example I saw recently was the track of a cruise
shop through the north west passage it looked crazy. Change the
projection it made sense.
... I don't know how far we'd go, but wee do need to give some
advice to an end user.
<Zakim> phila, you wanted to talk about mapping agencies
Byron: The main one... if most of the data will be used in a local projection, publish in that projection.
ack me:
phila: +1 to Ed on most people not knowing about projections - and prob don't need to *unless* they're working with mapping agencies.
eparsons: We're seeing... no one os more knowledgeable about IGN's data than IGN, but they don't publish their data in Lat/Long so they're missing a market
Payam: What I hear is that it's important to keep this section. We can highlight who needs to read the section - you can add a hyperlink to skip it
Linda: I worry that were falling into the trap of trying to educate people more than is our remit.
<Payam> +q
Linda: We can advise people to publish in local CRS and Lat/Long
<eparsons> +1 to linda
Linda: And we can say that there
are other CRSs and explain why they exist and when they
matter
... Maybe in an annex
jtandy: Byron had the example of
publishing a map with a circle - colleagues asking for Cubic
Splines
... I asked what happens if you project that onto a UK map?
eparsons: To Linda's point -
we're not going to teach people cartography.
... That's not our job. Someone does need to do it, but it's
not our job.
jtandy: We said that we should tell people that they should also publish in Web Mercator and we should tell people that other CRS exist.
ChrisLittle: OGC deprecated Web Mercator
eparsons: Web Mercator is still the most used, whether PGC deprecates it or not.
Payam: I disagree a little. OK,
we're not educating, but we need to make people aware of the
issues.
... I think this doc is written for people who don't know about
this stuff, which it does.
eparsons: If we can point people to good resources that teach cartography
ClausStadler1: Maybe point to examples of polygons in different projections
<Zakim> phila, you wanted to support Payam
phila: Supports inclusion of the intro material - it reads well. I'd be sad to see it lost completely, and even in an annexe almost loses it.
eparsons: You talk about map projections is not about data publishing
<Payam> +q
<ByronCinNZ> +q
ClemensPortele: The German native data projection is UTM
eparsons: But you end up with
either planar coordinates or angular measurements. It's only an
issue if you want to do something different from those.
... You need to know that one set is projected, one isn't. It's
only when you come to create graphics that it matters.
Linda: This discussion
illustrates this point - we're trying to educate people. We
should tone it down. I'd prefer an annex, but we should make
clear that bit's only interesting in certain use cases.
... Lat/Long is often enough. We shouldn't try and convince
people that there is a problem.
... Talked about a website where you can drag countries and see
how their relative size changes.
SimonCox: Back on Phil and what
Linda was saying. Most of us that have some education in the
spatial sciences... know that CRSs is the biggest dragon in the
room.
... If we're writing a Spatial data on the Web BP doc, we'd be
delinquent in not giving it some prominence.
Payam: +1 to Simon.
... If I read this doc and understand it better - which I did -
that's helpful
<Payam> +1 ByronCinNZ
ByronCinNZ: Maybe it is beyond us
to educate people, but we can highlight why they might care and
point them to resources.
... Another issue - imagery - if you have vector graphics, OK,
but not so easy for raster data.
eparsons: We have to find the right balance of telling people about the issues without scaring them off as there aren't dragons for most.
ChrisLittle: I think there's a consensus that we keep it, but we're debating whether it goes in the annex or main doc. If it goes in the annex, what goes in the intro?
<Zakim> jtandy, you wanted to ask if someone can take a lead on evolving the CRS content
jtandy: Can one of the WG take a
lead in pulling together the discussion about CRSs
... Can someone take an action to sort this out?
... We'd like someone to take ownership.
eparsons: I'd be happy to take a run at the introduction which is the only bit I have a problem with. I think the intro is a bit scary.
SimonCox: Does it just need a picture?
eparsons: Maybe. For a lot of
people, no need to worry, anda then just work through to where
it does get more complicated.
... It seems really complicated when all someone wants to do is
publish the location of their summer fete.
jtandy: There are still two BPs that need work.
Byron: I can put my hand up to merge a couple of BPs.
jtandy: It's not about merging, it's about making sure that they contain actionable advice.
Byron: we'll at least determine what the differences are.
<scribe> ACTION: Byron to take the lead on BP 3 and 18 around CRSs [recorded in http://www.w3.org/2016/12/16-sdw-minutes.html#action04]
<trackbot> Created ACTION-241 - Take the lead on bp 3 and 18 around crss [on Byron Cochrane - due 2016-12-23].
ChrisLittle: I was going to suggest including a sentence that GPS isn't the only show in town. Galileo went live yesterday.
eparsons: Time to move on
<eparsons> PROPOSED: That the editors current draft of the BP doc at w3c.github.io/sdw/bp/ be published by W3C and OGC as the next iteration
<jtandy> +1
<ChrisLittle> +1
<Payam> +1
<Linda> +1
<ClemensPortele> +1
<AndreaPerego> +1
<RaulGarciaCastro> +1
<ClausStadler1> +1
<eparsons> +1
<LarsG> +1
<SimonCox> +1
<ahaller2_> +1
<ByronCinNZ> +1
<kerry> +1
RESOLUTION: That the editors current draft of the BP doc at w3c.github.io/sdw/bp/ be published by W3C and OGC as the next iteration
<laurent_oz> +1
<eparsons> Congratulations and Thanks to the Editors !!!
jtandy: We want to keep the tempo of publishing every 6 weeks or so.
[Vote of thanks to the editors]
<eparsons> Back in 15 mins - 11:10 GMT :-)
<SimonCox> B****y macs. Even boast about when they go to sleep.
<Payam> ahaller2 update from yesterday; we agreed yesterday to do some changes; ahaller2 has sent an email and also made some updates
<ahaller2> https://github.com/w3c/sdw/commits/gh-pages/ssn/index.html
<Payam> ahaller2 the links refers to the changes- mainly editorial and HTML fixes
<Payam> ahaller2 there are also some reappearing "999" issues;
<Zakim> SimonCox, you wanted to point out that there is no link to sosa.ttl included in the document
<Payam> ahaller2 one of the pull requests has been rejected due to some html errors
<Payam> SimonCox links on the top of the document refer to some of the resources but not all the resources; at the moment there are lots of RDF files in Github;
<Payam> kerry there were 5 "999" issues; two still remaining; reformatting the code section
<Payam> there seem to be some problem with the versioning and changes made to the document
<Payam> ahaller2 : has made the changes to the document based on what was agreed yesterday
<Payam> ahaller2 issues 110 and 111 are new issues;
<Payam> ahaller2 issues 108 and 109 were raised yesterday by RaulGarciaCastro and DanhLePhuoc
<Payam> changes made in the past two hours were editorial changes; typos and broken lines, etc.
<Payam> ahaller2 the content of the current documents and the updates are based on what was agreed yesterday
<Payam> jtandy suggests to follow the same process as BP sub-group
<SimonCox> higher tempo of releases would be great! feels like less risk in accepting something we know is incomplete/imperfect
<Payam> laurent_oz comment about splitting to 2 sections- he disagrees with this...
<Payam> laurent_oz the difference with (old) SSN should be highlighted better
<Payam> there seems to be several last minute changes to the ssn document which needed to be discussed and agreed within the group; especially please avoid accepting any pull requests and ask editors to do this
<Payam> kerry thinks we should accept the status of the document once all the changes are reviewed are discussed.
<ahaller2> https://github.com/w3c/sdw/commits/gh-pages/ssn/index.html
<Payam> ahaller2 the changes are mainly editorial
<Payam> +q
<Payam> SimonCox requests specifics of the problems that need to be addressed
<Payam> SimonCox SOSA has been on the table for the past 6 months
<Payam> SimonCox there are open issues in SOSA but that was intentional
Payam: This is a repeat of yesterday's discussion, I scribed that too - I think the editors need to discuss this between themselves.
<scribe> scribe: Payam
<scribe> scribeNick: Payam
<kerry> https://github.com/w3c/sdw/commit/7a9a2c45a520fe7f2cff701561042c150008f503
kerry agrees that the editorial and merge/accept should be managed better- especially the comments regarding the changes to be more specific
+q
ahaller2 explains the recent changes
jtandy recommends against last minute changes and rush-hour behaviour ; we may need a period of no change for this
jtandy maybe for different parts of the document one of the editors will own that section and will monitor all the updates for that particular part
+1 jtandy - well modularised pull requests
<Zakim> phila, you wanted to offer http://services.w3.org/htmldiff?doc1=https%3A%2F%2Fwww.w3.org%2FTR%2Fvocab-ssn%2F&doc2=http%3A%2F%2Fw3c.github.io%2Fsdw%2Fssn%2F
jtandy thinks we won't be able to support a vote today
<laurent_oz> * thanks Linda
<ahaller2> we lost you
phila diffs shown by github sometimes could look enormous but they can be editorial and minor; better to check the difference between the documents
<SimonCox> No sound from London
<Linda> looking into that
one minute
phila changes shown by github sometimes can be misleading
ahaller2 suggests to have a meeting next week to discuss any possible objections to the document
eparsons thinks this is too close to Christmas to have vote on this document
kerry likes jtandy 's suggestions
the changes should be discussed; please avoid making last minutes changes; especially before the vote process
<Zakim> phila, you wanted to talk about publishing moratorium, Christmas etc.
phila the documents won't be published before the first week of January
the publication delay in publication date won't be significant;
we probably won't be able to make the required changes in the next 2 weeks; most people will be on holiday
<kerry> +1 i
ahaller2 is asking if SSN sub-group members will be available for a meeting next week
<laurent_oz> One of my reasons for joining is that I should be able to bring in images (of points discussed) to back up the discussions (make sure everyone is on the same page). And I'm here next week.
<phila> I can join the call Tuesday evening UK time, Wednesday morning Aus time
<Zakim> kerry, you wanted to suggest it maybe can be faster
kerry is keen to get the working draft published;
phila the next publication date is the 2nd of January
jtandy would like to know when the document will be stable; so he can read/review the document
eparsons suggests the editors agree on how they are going to manage the document
ahaller2 thinks the document as it is is stable; he has incorporated the changes were raised- he won't make any changes to make sure the document will stay stable
DanhLePhuoc can do the work; he can also review the updates
<SimonCox> 'Gatekeeper in chief' ?
<Zakim> phila, you wanted to talk about language and anchors
kerry doesn't have any concerns who takes the role; but agrees we need one editor to be in charge of monitoring the changes
phila spelling should be American
<jtandy> being "editor in chief" doesn't have to be forever ... you could assign that role for a limited period
phila change log should be up-to-date; it is important
phila has found 9, 404 errors...
<SimonCox> ... also optimisation, prioritisation
<phila> Link Check on the Editors' Draft
<ClausStadler1> There are also TODOs and "..." parts in there, which I suppose should be turned into proper issues(?)
<phila> +1 to ClausStadler1
jtandy big chunks of changes probably require around 2 weeks notice and smaller changes need a couple of days perhaps
ahaller2 discusses the possible meeting for next week
ahaller2 suggests Monday morning deadline for changes and Wednesday morning meeting
<Zakim> kerry, you wanted to suggest a "coiple of days' might be ok this time
kerry is happy with the proposal
kerry suggests to go through the document today
<ahaller2> sounds good to me, 4th of Jan meeting to get a vote
<kerry> +1
phila: next plenary will be in January; we could potentially vote on the 4th of January and publish the document on the 5th (all other documents will be also published on the 5th - two days delay for other documents)
<ClausStadler1> Just a small comment on the huge diffs: A vast amount in this concrete case are differences in white spaces - so on the one hand, the editors should make sure they don't use any auto-formatting, on the other hand its about discipline that ugly looking PRs are not merged. For the auto-generated code, using an auto-formatter should be considered(I think I heard such a comment when we had just re-established audio)
eparsons suggests to have the ssn meeting next week and see how much progress we can make
<ahaller2> +1 to ClausStadler1, I tried to explain that too
DanhLePhuoc will be editor-in-chief of ssn for this release
eparsons: remainder of this session?
<SimonCox> yep - it is 23:10 here!
eparsons suggest whether we should take some time offline to read the document
we can take some time offline to go through the document
kerry will take us through the document and will focus on the changes
<Linda> http://w3c.github.io/sdw/ssn/
<kerry> w3c.github.io/sdw/ssn/
introduction section hasn't changes much
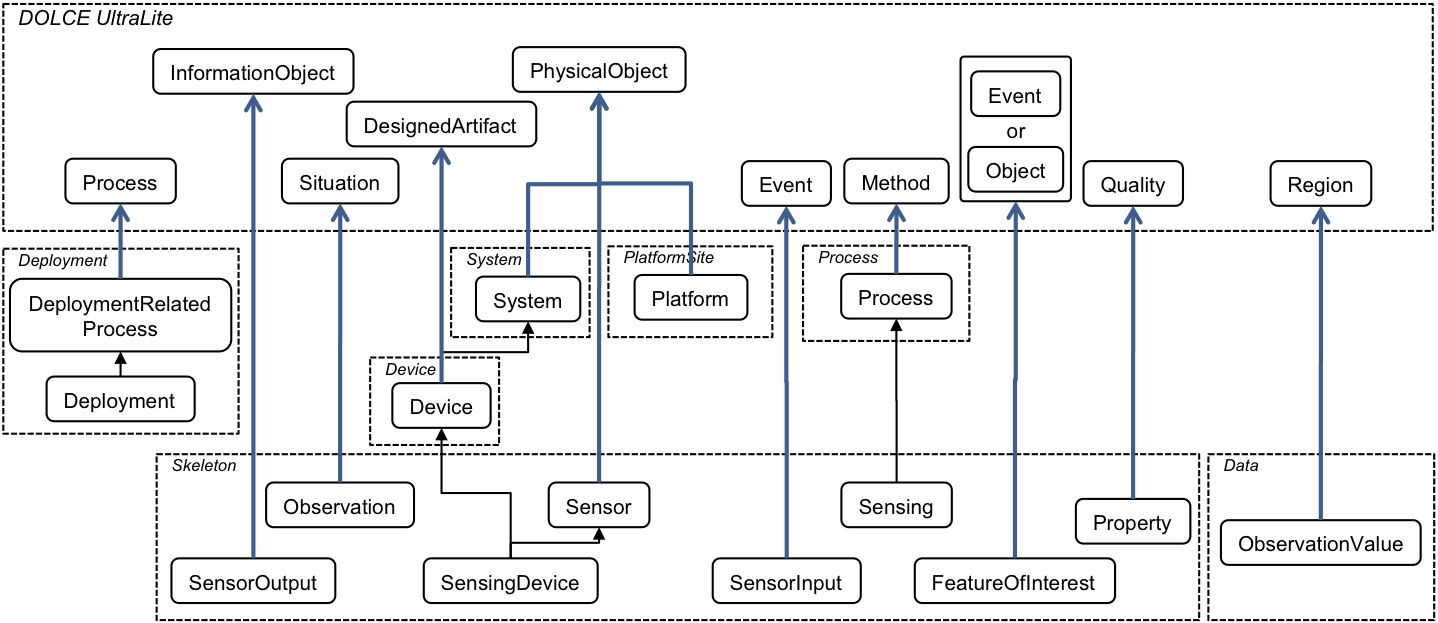
Section 3: Figure 1
the core has had little change from the (old) ssn ontology
there is a proposal to provide a non-normative alignment to O&M (on the right)
on the left we have DOLCE Ultra Light; in the new SSN this has changed
SSN can stand without dolce ultra light
horizontal modularisation has been abandoned;
ahaller2 modularisation has been removed form the document; there was no horizontal module in the document
<SimonCox> Horizontal modules might deal with refined models for Actuation, Sampling?
Section 4:
using spec gen to generate the specification in section 4 (some parts are also done manually to help the readability)
the main change is change to the namespace
there are some issues around names and relationships in the document
Section 6: Alignment
this is new
formatting will be fixed
alignment between new SSN and old SSN
the reason for this alignment is so that the implmentation of old SSN can be used with the new SSN
<laurent_oz> (just send a figure showing the alignment between the old and new SSN on the mailing list) - the kind of things I want to help with.
helping the transition from old ssn to the new
Linda asking about the chapter realted to SOSA and the order of topics in the document
SOSA should probably be discussed below SSN
<Linda> [recap] I suggested SOSA should be discussed before SSN as its the core
phila process shouldn't be deriving the design decisions;
process should not define the desin
s/design/design
kerry SOSA has several new terms and do not map directly to SSN
phila then you need to prove these new terms are used
kerry there is process to achieve this but has concerns whether this will be achieved...
SOSA has very limited relations to SSN
<laurent_oz> +1
phila you may then need a document explaining SSN and a note describing SOSA
DanhLePhuoc raised the concern about SOSA and structure
DanhLePhuoc refers to the experience at the early stages of ssn and we may use the lessons learned to better utilise the current efforts
DanhLePhuoc then the modularisation may be included in this document
+q
kerry discusses what we should do to publish SOSA
ahaller2 there many issues in the document but in essence the core of SOSA is a lightweight representation of SSN
<SimonCox> +1 ahaller2
<Zakim> RaulGarciaCastro, you wanted to say that right now we are trying to make SOSA a module of SSN but even if it is inspired by it its development is going in parallel; we need to
RaulGarciaCastro discusses SOSA
<kerry> +1 to Raul's comment
<laurent_oz> +1 also
RaulGarciaCastro we should not only discuss things differently e.g. the temporal properties in SSN or in SOSA; this way we will end up having two different implementations
kerry SSN importing the core; there are some issues that need to be resolved
<laurent_oz> For me ssn importing sosa will not work: it is too much of a jump for our user base to follow.
kerry there is only one difference between old and new SSNs (sensor class has changed + dolce has been removed)
<AndreaPerego> /me Just lurking on IRC.
Hello AndreaPerego
laurent_oz old ssn names and new ssn names and SOSA should be shown in boxes and shown how they are related; basically highlighting that the readers need to know about
phila don't use rdf/xml to show old/new...
<DanhLePhuoc> +1 removing RDF/XML, it's urgly
formal semantic statements should be written in formal semantics
<SimonCox> I did an alignment for SOSA->om-lite here https://github.com/w3c/sdw/blob/gh-pages/ssn/rdf/sosa-oml.ttl
<SimonCox> Isn't that OK?
RaulGarciaCastro would like to see a table that summarises the implementation and full implementation can be an annex
kerry the reason for not doing this is that this is based on old SSN- this means listing all the classes and properties and saying equivalent (all are equivalent except one)
alignment to DOLCE; is there and shown in trutle; maybe some explanation could be helpful (or a diagram?)
<DanhLePhuoc> https://www.w3.org/TR/2012/REC-owl2-direct-semantics-20121211/
DanhLePhuoc looks trivial when only equivalents are shown....
<RaulGarciaCastro> At least something like this is always useful (even if it does not capture the whole expressiveness: https://www.w3.org/2005/Incubator/ssn/XGR-ssn-20110628/images/OntStructure-AlignmentDUL.jpg
kerry agrees to put the semantics in an appendix
the alignment to DOLCE (Section 7): this is different; a figure will be good
s/god/good/
SimonCox agreeing with kerry
there are some sub-properties and union classes involved as well
laurent_oz also thinks a figure will be good;
kerry asks whether a figure will be good enough to describe the alignment (on its own)
ahaller2 pictures will be nice; because the ontologies change, we haven't generated the figures yet
<SimonCox> I remembered my point now. Can't add comments to mappings without reification ...
SimonCox adding some comments and narrative to the changes...
SimonCox: talking about Section 8 (which currently is a placeholder)
will be OGC input to this work...
there are some OWL implementations to be used...
<Zakim> phila, you wanted to ask Simon and Chris about Time before we call lunch please?
phila asks for an update
ChrisLittle has sent emails and has proposed doing the note and has also looked into the issues
ChrisLittle and the team are working on it
ChrisLittle will try to annotate some video feeds (in near future)
phila we need implementation of the new stuff
SimonCox explains an implementation which is done at CSIRO
phila this is good; we need another one
ChrisLittle will annotate the videos and climate...
phila you need those independent implementations by March
phila a CSIRO service using the ontology will be acceptable as an implementation
phila or gathering old implementation and providing a non-normative descriptions... (this doesn't seem to be required)
DanhLePhuoc explains the RDF Stream Processing work...
<SimonCox> Intention is to redo this: http://resource.geosciml.org/classifier/ics/ischart/ to use OWL-Time
<eparsons> close the queue
DanhLePhuoc the question is that if the engine that they have implemented can be also considered here...
<SimonCox> (crappy UI, but the content is good)
<phila> DWBP Implementation report
phila gives an example of a good implementation
link above
<SimonCox> Can I go to bed now?
Thank you all...
<phila> [Lunch]
<LarsG> I won't be back after lunch, thanks all!
<SimonCox> bye
<laurent_oz> Bye
we will be back at 14:00 GMT
<kerry> +1 me
<eparsons> Lunchtime !!
<phila> scribe: Clemens
<phila> scribeNick: ClemensPortele
jtandy: This afternoon we want to
spend time about the choices to make (vocabularies, formats,
etc)
... ClemensPortele, you wanted to talk about how to express
rich data from ISO/GML application schemas in JSON, RDF
jtandy: plus document structure
and other items from Payam
... Move the document summary right after the
introduction
... kind of a quick start guide
eparsons: in terms of the current structure, chapter 11 would move close to the top?
jtandy: yes
... There BP template does not seem to add much value, it is
self-explanatory
phila: agrees
jtandy: we could reference the DWBP template
eparsons: not even necessary
Action on Linda to restructure the document to move the summary to the top and remove the template
<trackbot> Error finding 'on'. You can review and register nicknames at <http://www.w3.org/2015/spatial/track/users>.
Action oLinda to restructure the document to move the summary to the top and remove the template
<trackbot> Error finding 'oLinda'. You can review and register nicknames at <http://www.w3.org/2015/spatial/track/users>.
Action Linda to restructure the document to move the summary to the top and remove the template
<trackbot> Created ACTION-242 - Restructure the document to move the summary to the top and remove the template [on Linda van den Brink - due 2016-12-23].
jtandy: do not want to be too
ambitious, but want to keep up the pace
... so far we have: BP4 (Clemens), Chapter 7 CRS (Ed) plus BPs
3 and 18 (Byron), BPs 7 and 14 (Jeremy), Document structure
(Linda)
<AndreaPerego> I can take care of BP8.
jtandy: BP8 (Andrea)
<ChrisLittle> Nick ChrisLittle Ayatollah
jtandy: more may be a result of the afternoon discussion, if we can fit it into the next release
eparsons: How many sprints do we need to complete the work?
<Zakim> PhilA, you wanted to ask about implementations
jtandy: Let's work this out as part of the next sprint
PhilA: a note, not a rec, but we want to have implementation evidence
<PhilA> Implementation report for DWBP
PhilA: they started with an
overly long form, but in the end a Google spreadsheet was just
fine
... the group is not required to do this, but may want to
provide it to back the content
... it took them 3 months
<AndreaPerego> Just to note that DWBP implementation report does not report about GeoNetwork, which is a widely used geospatial catalogue platform (at least in Europe).
<kerry> +1 examples in used doc is good enough
jtandy: we should only reference
live examples
... badge collecting not required
eparsons: Don't think we need a separate document
<Zakim> AndreaPerego, you wanted to ask about the most efficient way of collecting implementation evidence
AndreaPerego: in DWBP separate by BP that later needed to be merged
jtandy: Link to the examples where we can, otherwise it is enough if we are convinced there is evidence
<Linda> https://www.w3.org/2015/spatial/wiki/BP_Examples_in_the_Wild
Linda: Recently became aware of some examples, now on a wiki page - that is a resource that we can build on
jtandy: so could work until the end of June, but want to finish by the end of May
PhilA: The recs need to finish
end of March and the BP document is not done in isolation
... regular calls should end in March
eparsons: How about end of April?
jtandy: this sprint - end of
January; next sprint - mid March; final sprint - end of
April
... kind of worried that this is not sufficient
... We will try end of April, but if we need another sprint we
could do it after April
<Payam> +q
jtandy: and continue the calls with those interested
eparsons: reordering of the BPs should be done with as many as possible
Linda: Maybe during the f2f in Delft?
PhilA: yes, forgot about this, this is where the recs should be close to final
eparsons: f2f in Delft will be
Monday 20 March
... this is just for BP, we need a separate meeting for the rec
votes, so Tuesday for that
Payam: We should a cut-off date for new comments, e.g. 20 March
jtandy: fair comment, no new concepts to be added after mid March sprint
Payam: Also not removing elements that others may think are important
joshlieberman: Plans for
Geosemantics session in Delft - what can the DWG from the
W3C/OGC work?
... so the other direction
jtandy: So, the more stable it is the better for the Geosemantics discussion
eparsons: Will work on the outreach task; based on when we have a stable enough document for this
jtandy: Probably after the next spring
PhilA: do not forget the
horizontal review
... should be the January version to leave enough time
Linda: We should publish the sprint plan
Action Linda to publish the sprint plan on the wiki
<trackbot> Created ACTION-243 - Publish the sprint plan on the wiki [on Linda van den Brink - due 2016-12-23].
<Payam> if you are starting from scratch , are there any building blocks that you can use; and if yes, how do you use them?
<Payam> if I have something in one format and one to publish it in a different format how to do this.
<Payam> how do we publish a data that we have in RDf or in geo-json
<Payam> do we have a mechanisms to express different views at the same time
<joshlieberman> 1) Reuse 2) reinvent 3) follow a modeling process
<Payam> jtandy best practices should be able to express how different approaches can converge
<Payam> eparsons different communities will take different approaches; there won't be one solution.... we have to recognise the fact that there will differences in approaches... some of these can be captured in use-cases
<Payam> eparsons if you were a coffeeshop chain your approach will be different and probably your requirements will be simpler compared to some others that may have more complex requirements....
<Payam> jtandy think of your user first
<Payam> joshlieberman there are two ends of the spectrum; easy one: take something and publish it (shares/re-use); the other: using more complex models and schemas
<Payam> depends on the resources that you have
<joshlieberman> One suggestion is that this is what modular vocabularies help with.
<Payam> we want people to escalate but not reinvent if there are already best practices to do something in a certain way
<Payam> ClemensPortele we need to provide more conceptual level advice to publishers
<Payam> ClemensPortele we need to look at what is already there and make recommendations
<Payam> ClemensPortele you can look at the existing solutions/practices and see if they satisfy your needs
<joshlieberman> Again -- modularization and pointing at the simplest approach for adding a capability, e.g. starting with PROV-O for lineage, starting with DCAT for search metadata.
<Payam> ClemensPortele if somewhere there is no solutions, we can say there is no (common) solution there; and that still will be helpful
<joshlieberman> Working right now to modularize GeoSPARQL, for example. Core looks like GeoRSS, then adds relations, simple features, topology, etc.
<Payam> ClemensPortele would like to focus on UML models (in contrast to GML) here; conceptual level...
<Payam> making it easier to publishers to what they should look at....
<Payam> ClemensPortele UML, GML, RDF JSON
<joshlieberman> UML provides the conceptual glue, but mechanical relations seem to get us in trouble (e.g. GOM).
<Payam> it will be good if we have a document somewhere that we can update it beyond the editorial lifetime of the current document
<Payam> ClemensPortele it shouldn't only be about purely mechanical solutions; it should also consider the needs...
<Payam> not the domain modelling but the building blocks
<Payam> joshlieberman we want to support different tools; what is the best mechanism to establish the link to UML(---scribe: missed this part ---?)
<Payam> ClemensPortele wants to make it clear for human readers - do we have a formal way to represent that
<Payam> jtandy discussing a road traffic incident reporting example; if you want to apply what we are discussing here; where do you start?
<PhilA> scribeNick: Payam
<PhilA> scribe: Payam
eparsons let's say: if I have my portal now; what do I need to do differently?
ClemensPortele we have discussed how to create the indexable html pages for the datasets but we haven't discussed other forms of publishing the data...
if you want to publish your dataset in both DCAT and RDF; how do you that? do we provide enough help to make sure people don't go in different directions....
ClemensPortele we may use some tables to summarise and describe these...\
eparsons do the current best practices cover these?
<joshlieberman> Usual escalation: 1) Copy existing road feature schema; 2) Add geometry to existing road schema; 3) Use / extend modeling vocabulary (gml, ogeo) to create new road schema
ClemensPortele we have the best practices but they are not clear enough
ClemensPortele we use existing common vocabularies... we should provide more information about these...
+q
ClausStadler1 discusses using different formats
<Zakim> PhilA, you wanted to talk about http://w3c.github.io/sdw/bp/#applicability-formatVbp
jtandy first focusing on user needs
for simple data, geo-json can be sufficient
for more complex datasets, GML or other formats;
other applications/use-cases, may need rdf or json-ld
<PhilA> acl l
joshlieberman we should discuss pros/cons
jtandy discusses how we should capture this in the report
jtandy are we going to discuss KML?
probably not
use GEO-JSON
this is type of advice that we can give to people
e.g. if you want to do map rendering, publish it in shape file and/or geo-json
kerry what do you propose instead geo-tif?
jtandy you can't work with geo-tiff using web browsers
<eparsons> action kerry to check reference to geotiff in eo doc
<trackbot> Created ACTION-244 - Check reference to geotiff in eo doc [on Kerry Taylor - due 2016-12-23].
eparsons we should say what people should use (in contrast to focusing on telling people what they shouldn't use)
shape files are proprietary - not open
<joshlieberman> Assumption is that recommendations are for "use on the Web" and likely "use in a browser application"
jtandy SesnorThings is an OGC specification and uses some building blocks from GEO-JSON
what are the other options in SensorThings
joshlieberman you can use GML, Geo-JSON...
the current expressions are in Geo-JSON
jtandy if we consider SensorThings as a practice: it considers using building blocks (geo-json...)
joshlieberman SensorThing standard describes its own encoding
eparsons there are lots of practices that use GEO-JSON; because it is a format that is favoured by developers
<joshlieberman> There is work (e.g. Testbed 12) on an OGC-JSON in JSON-LD, but doesn't have a succinct set of requirements yet, I would say
ClemensPortele the next step is if you have your feature; and you pass time; time ontology can express it in RDF but it is not clear how to express that in GEO-JSON...
GEo-JSON doesn't express the complexity of the properties...
joshlieberman this is an escalation problem; there is no formalism to describe the (complex) properties of the features...
<joshlieberman> Problem: GeoJSON can be extended with additional terms, but GeoJSON interpreters that read those terms are "non-conformant"
+q
GEO-JSON doesn't do: has one CRS, no time, 2 D geometry, simple geometry object
there is no ID concept
you can use concepts and common vocabularies and inject them into your JSON and/or Geo-JSON documents
eparsons GEo-JSON is used to express the geometry
joshlieberman what is the way to extend geo-json...
joshlieberman considers an OGC JSON to extend the capabilities
ClemensPortele geo-json does a bit more than geometry.... there is a feature concept...
jtandy we can use json-ld...
ClemensPortele nested arrays don't work in json-ld
<joshlieberman_> One version of OGC-JSON actually includes both GeoJSON geometry "and" WKT
<PhilA> Payam: What would change the world? If we encourage people to do X, what is that?
<PhilA> eparsons: All the other BPs are probably more important than this one for us.
<PhilA> ... Giving things IDs, making data crawlable that's the important thing.
<PhilA> Payam: Do people need geometries for putting stuff on a Google map?
<PhilA> eparsons: If you want to put extra layer on top, we recommend you use GeoJSON - which works for most things.
<PhilA> Payam: City planners etc. want to lay things out, The scale isn't that important?
<PhilA> eparsons: From a Web POV, there are very few things where GeoJSON isn't enough
<PhilA> jtandy: Looks at schema.org which doesn't use GeoJSON because they want to use JSON-LD and RDFa
<PhilA> eparsons: The benefit is that its even easier than GeoJSON
<PhilA> eparsons: Web developers love GeoJSON becauase it just does what it has to do
<PhilA> jtandy: If you're trying to do the data integration piece
<PhilA> eparsons: Then you're not a Web developer
<PhilA> Payam: Geometric stuff is probably not on the Web.
<PhilA> eparsons: People aren't building GISs in the browser.
<PhilA> ... The simplest thing always wins
<PhilA> jtandy: The protocol buffer used by MapBox is useful
<PhilA> jtandy: What I'm hearing - we have 3 types of usage
+q
<PhilA> ... Web dev - keep it simple.
<PhilA> jtandy: SDIs at the other end
<PhilA> jtandy: And we have data integration in the middle
<PhilA> Payam: I see lost of things using GeoHashing, like Mongo DB, is that relevant?
<PhilA> ... MSFT has a solution around GeoHash
<PhilA> jtandy: That's just a way to express a coordinate position
<PhilA> eparsons: It's a way of tesselating
<PhilA> eparsons: It's a back office decision.
joshlieberman_ agrees that the web usage of the data is overlaying the data...
joshlieberman_ data integration won't be possible with geo-json
joshlieberman_ we need to specify best practices to describe how integration can be handled - not only the simple data publication
jtandy you can use geo-json with IDs that in practice we can refer to objects and then use more expressive descriptions
ChrisLittle discusses web development and SDI communities; we need to recommend best practices to encourage taking the data out silos
<Zakim> PhilA, you wanted to say the browser isn't the Web
PhilA developers building solutions for the browser is not the entire web applications/requirement
<Linda> bye all have to catch my flight
ClemensPortele this working group should go beyond saying how to use geo-json
<joshlieberman_> We have a path to support for mediation and integration that vocabularies in RDF/OWL refer to common concepts in UML, then have encodings, e.g. in JSON-LD that refer to the expressiveness of the RDF/OWL.
+1 joshlieberman_
+q
<joshlieberman_> So the advice would be use GeoJSON, and escalate using JSON-LD encodings and the higher level references to solve integration or complexity problems
ClemensPortele suggests the businesses should be also done on the web
<PhilA> Payam: Can we capture what OGC has in this space
joshlieberman_ explains combining and integration of data
<PhilA> Industry 4.0
+q
<joshlieberman_> E.g. we are trying to "ground" RDBMS hydro data in a hydro ontology that in term is grounded in the HY_Features UML model.
jtandy given there are lots of vocabularies to describe spatial data if we recommend one model.... would that be good guidance
joshlieberman_ we don't way use one solution all the time... we provide a pathway should you need
it
PhilA discusses the list of vocabularies that exist... and says how many of them we can actually referecne
<joshlieberman> Practice is not to insist on RDF, but use something that is grounded in an RDF/OWL vocabulary to add integration potential
<PhilA> Payam: We have to think about data that people that actually use. There's lots of RDF that's published but not used.
ClausStadler1 people publishing data talking about the same thing, this should be interoperable; interoperability: is it in the scope?
jtandy asks if we can provide some statistics about the vocabularies' use
jtandy if you want to use a scheme does geosparql have the right building blocks to do that?
<PhilA> ClemensPortele: I don't see GeoSPARL as the middle ground
<PhilA> ... We should be trying to make things more comparable
<PhilA> ... If I want to integrate stuff from an SDI and from an RDF store, it helps if I understand the concepts
<PhilA> ... If I have to publish the integrated data in both formats, then I can see how to do it.
<PhilA> eparsons: I think that's right
<joshlieberman> So - that would benefit from the UML grounding, but RDF/OWL is more machine processable as a grounding.
<PhilA> ClemensPortele: It's about consistency
<PhilA> eparsons: If we just pick one, we can't say it's best practice... it would be bizarre if the SDW WG didn't come up with a solution for publishing RDF data.
<PhilA> ClemensPortele: We should be honest if theere is no definite answer.
<PhilA> jtandy: You said that maybe using vocab X partially solves the problem
<PhilA> ... Is GeoSPARQL enough to describe geometries
<PhilA> ClemensPortele: Not for 3D
<PhilA> joshlieberman: GeoSPARQL needs to be updated, Version 1 was about querying a SPARQL endpoint. Not intended to be about integration.
<PhilA> ... No place to add on the 3D, that's an important part of the update.
<PhilA> ... The idea that there are 2 levels of grounding is important
<PhilA> ... The grounding in UML is a common ground but iut;s hard to process as an integration tool
<PhilA> ... It may become a BP but it's our best hope for facilitating some integration on the Web.
jtandy there are two levels of grounding...
joshlieberman 1st: we have an owl/rdf vocab
scribe: GeoSPARQL core vocab
2nd level: reference to ISO/... model
jtandy both types of grounding should be using in an application? or these are two different choices?
joshlieberman: the latter case; different ways of finding common ground....
jtandy summarises: you can start with json (which doesn't say much); one can use JSON-LD which allows to find common ground; further to this up to UML but this will be too abstract
ClemensPortele if you are using the same RDF grounding, then you can do the integration at that level
ClemensPortele or if you use conceptual level, that's where/the level you should do your intrgration
+q
<joshlieberman> For example, GeoSPARQL and IGN ground in 19107. NeoGeo did not and so is less useful for integration.
<eparsons> Congrats Linda safe travels
jtandy will summarise this discussion to describe the decision flow for best practices
joshlieberman would like to get feedback related to their spatial ontology
<PhilA> Payam: This is very sketchy at the moment. It needs more content
<PhilA> https://github.com/w3c/sdw/issues/121 asks if we need this as a BP at all?
<PhilA> jtandy: I think we said that it's just a special case of a CRS
<PhilA> Payam: If Josh has an ontology to describe next to, near etc.
<PhilA> eparsons: If the ontology manages those relationships, then it's solved.
<PhilA> Josh: I did update the action about relative positioning. I have some material from Christine Perey
<PhilA> ... In theory they are different CRS, but in practice the formalism doesn't work
+q
<PhilA> Josh: There is a concept of ego-centric, what you can see, and OWL centric, which is relative to an object.
<PhilA> josh: We can state that those are important perspectives but there is not currently a formalism for describing those.
<PhilA> jtandy: We have struggled to find vocabs for in front of/behind etc.
<PhilA> eparsons: It's a real problem
<PhilA> jtandy: We're saying 'make something up'
<PhilA> PhilA: IS this what Josh is doing or does it need to be done by someone sometime.
<PhilA> josh: We can say that this is needed.
<ChrisLittle> AQ+
<PhilA> ACTION: PhilA to add vocab for relative positioning to wish list [recorded in http://www.w3.org/2016/12/16-sdw-minutes.html#action05]
<trackbot> Created ACTION-245 - Add vocab for relative positioning to wish list [on Phil Archer - due 2016-12-23].
<PhilA> PhilA: Talks about possible future joint IG
<PhilA> Payam: Some of the things at the geometry level might be too complicated
<PhilA> ... Can Josh send us that para and we'll add it to the BP doc
<PhilA> jtandy: I think we said there isn't a BP.
<PhilA> jtandy: It might go in a Note block saying 'make it up' as there isn't a Bo for this
<PhilA> ... So BP 9 will be converted to a gap in practice.
<PhilA> jtandy: I think this is wrapped up in the discussion we just had about choices of vocab
<PhilA> Issue 39
<PhilA> Payam: Issue 38 https://github.com/w3c/sdw/issues/38 should we publish a complementary Note with some mappings
<PhilA> ... I guess we won't
<PhilA> jtandy: I think that's what Clemens was suggesting
<PhilA> ... That's what those mappings are.
<PhilA> eparsons: Where there are vocabs, let's talk about correspondence between them. And then given that, how do you choose one.
<PhilA> Payam: I don't think it will be a Note, it will be table in the document.
<PhilA> jtandy: So issue 38 will prob be dealt with in the next iteration.
<PhilA> Payam: Exposing data through convenience APIs
<PhilA> Payam: It's done, forget it
<PhilA> jtandy: There's a lot of work to do about the convenience API piece.
<PhilA> ... I'd also like to tie that back to DWBP more tightly
<PhilA> PhilA: They sweated over that
<PhilA> jtandy: And it's much much better for it.
<PhilA> jtandy: One of the things that helps is a search function in your API because that helps find stuff.
<PhilA> ... You want to be able to search on a specific hospital. It's not a spatial issue
<PhilA> Payam: Are you saying that the API is discoverable?
<PhilA> ... Say I have an API about floods...
<PhilA> jtandy: I think finding the API is dealt with in DWBP
<PhilA> ... You might have a web service endpoint for finding info about a place but that applies to all data.
<PhilA> ClausStadler1: There might a function that returns stuff based on a geometry
<PhilA> jtandy: I think it can be integrated nto another BP
<PhilA> eparsons: I think we may need to save this issue for another time.
<ClausStadler1> So if hydra was mentioned in order to describe APIs themselves, then SPARQL service description should be mentioned as well
<PhilA> josh: I would argue that there is some place for setting out what functionality to include in an API
<PhilA> eparsons: Draws a line
<PhilA> [Meeting Adjourned]
<kerry> kerry claps too
<PhilA> Thanks to everyone for a marathon session
<PhilA> Sleep well Kerry
<kerry> sort-of
<AndreaPerego> Thanks, and bye!
Thank you all
<PhilA> Thanks to everyone on the call.
{kind=link}