An XML Pipeline specifies a sequence of operations to be performed on a collection of input documents. Pipelines take zero or more XML documents as their input and produce zero or more XML documents as their output. Steps in the pipeline may read or write non-XML resources as well.
A pipeline consists of components. ...
There are two kinds of components: steps and (language) constructs. Steps carry out single operations and have no substructure as far as the pipeline is concerned, whereas constructs can include components within themselves.
module xproc01
// Pipelines
sig Pipeline {
inputs: set XMLDoc,
outputs: set XMLDoc,
components: set Component
}
// Pipelines read and write mostly XML documents,
// but also nonXML
sig XMLDoc {}
sig nonXML {}
// Components are of two kinds: Steps and Constructs
abstract sig Component {}
abstract sig Step extends Component {}
abstract sig Construct extends Component {
components: set Component
}
 Figure 1: Class relations in model xproc01
Figure 1: Class relations in model xproc01
A pipeline consists of components. Like pipelines, components take zero or more XML documents as their input and produce zero or more XML documents as their output. The inputs to a component come from the web, from the pipeline document, from the inputs to the pipeline itself, or from the outputs of other components in the pipeline. The outputs from a component are consumed by other components, are outputs of the pipeline as a whole, or are discarded.
...
abstract sig Component {
ins: set (XMLDoc + nonXML),
outs: set (XMLDoc + nonXML)
}
...
Continued in <Unnamed data flows (sketch) 7>
...
sig Pipeline {
ins: set XMLDoc,
outs: set XMLDoc,
components: set Component,
descendants: set Component,
flows: (ins + descendants.@outs) ->
(descendants.@ins + outs)
}{
// The 'descendants' of a pipeline are all of the
// components in its 'components' set, or in the
// 'components' set of any descendant.
descendants = univ.^components
// Flows only involve XML documents.
// I.e. the domain of flows is XMLDoc
flows.univ in XMLDoc
// And so is the range
univ.flows in XMLDoc
}
...
sig Pipeline {
ins: set XMLDoc,
outs: set XMLDoc,
components: set Component,
descendants: set Component,
flows: (ins + descendants.@outs) ->
(descendants.@ins + outs)
}
// The 'descendants' of a pipeline are all of the
// components in its 'components' set, or in the
// 'components' set of any descendant.
fact descendants {
all p: Pipeline | p.descendants = univ.(p.^components)
}
// Flows only involve XML documents.
// I.e. the domain of flows is XMLDoc
fact flow_domain {
all p: Pipeline | p.flows.univ in XMLDoc
}
// And so is the range
fact flow_range {
all p: Pipeline | univ.(p.flows) in XMLDoc
}
This code is not used elsewhere.module xproc02 open util/relation as RThis code is used in < Pipelines and components with named ports 9 >
// Some primitive, unanalysed signatures:
// names, documents, resources
sig Name {}
sig XMLDoc {}
sig nonXML {}
This code is used in < Pipelines and components with named ports 9 >
// Any pipeline component has inputs and outputs.
abstract sig Component {
ins: Name -> lone XMLDoc,
outs: Name -> lone XMLDoc
}{
// The names of input and output ports are disjoint.
// (At least I think they are; is this true? See 2.1p6.)
no dom[ins] & dom[outs]
// No document is simultaneously an input and an output
// for the same component. See 2p1.
// (Actually this is weaker than 2p1. In fact,
// data flows are acyclic.)
no ran[ins] & ran[outs]
}
Continued in < 13>, < 14>all n: Name | n in dom[ins] => n not in dom[outs] and n in dom[outs] => n not in dom[ins]or
all n: Name | not (n in dom[ins] and n in dom[outs])The expression “no dom[ins] & dom[outs]” has the general form “no Expr”, which means ‘the set described by expression Expr has cardinality 0’. Here, that set is the intersection of dom[ins] and dom[outs].
// Steps (atomic components) have no further internal
// structure, just inputs and outputs.
abstract sig Step extends Component {}
// Constructs (compound components), however, have
// nested components
abstract sig Construct extends Component {
components: set Component,
descendants: set Component
}{
descendants = ran[^@components]
}
sig Pipeline extends Construct {}
This code is used in < Pipelines and components with named ports 9 >
sig XInclude extends Step {}{
some document : Name
| some X : XMLDoc
| ins = ( document -> X )
some result : Name
| some X : XMLDoc
| outs = ( result -> X )
}
This code is used in < Specific component types 18 >
sig Validate extends Step {}{
some document, schema : Name
| some X1, X2 : XMLDoc
| disj[document, schema]
// N.B. the Names are disjoint, not necessarily the documents
and ins = ( document -> X1 + schema -> X2 )
some result : Name
| some X : XMLDoc
| outs = ( result -> X )
}
This code is used in < Specific component types 18 >
sig Identity extends Step {}
sig XSLT extends Step {}
{The Validate step type 17}
{The XInclude step type 16}
sig Serialize extends Step {}
sig Parse extends Step {}
sig Load extends Step {}
sig Store extends Step {}
sig ExtensionStep extends Step {
type : Name
}
This code is used in < Pipelines and components with named ports 9 >
pred show (p: Pipeline) {
some p.ins
some p.outs
Component = p + p.^components
}
run show for 3
Continued in <Sanity checks, cont'd 20>, <Sanity checks, cont'd 21>
pred cyclic (p: Pipeline) {
some p.ins
some p.outs
some c: Component | c in c.^components
}
run cyclic for 3
pred acyclic (p: Pipeline) {
some p.ins
some p.outs
no c: Component | c in c.^components
}
run acyclic for 3
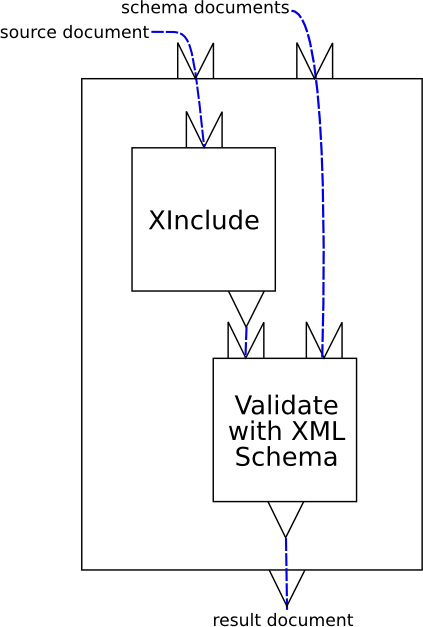 Figure 2: Figure 1 of the spec.
Figure 2: Figure 1 of the spec.
module xproc_figure01 open util/relation as RContinued in <Import xproc02 model 23>, <Define subtypes of Name 24>, <Define Figure_1 predicate 25>
open xproc02 as XP
// First, define some specific names (these aren't
// essential, but they are convenient)
one sig Document, Schema, Input, Result extends Name {}
// Now define the figure itself.
// It requires a pipeline, two components, and four names
// for specifying the data flows.
pred Figure_1 (p: Pipeline,
x: XInclude,
v: Validate,
document: Document,
schema: Schema,
input: Input,
result: Result
) {
{Constrain component structure 26}
{Describe the port wiring 27}
}
run Figure_1 for 3 but 4 XMLDoc
// The XInclude and validation components are // in the pipeline. // Nothing else is in the pipeline p.components = (x + v)This code is used in < Define Figure_1 predicate 25 >
// There are four documents needed. (I don't currently
// see whether it's better to declare these above, or here.)
// This is one way to define the data flows.
// There are others.
some Doc, Sch, Tmp, Res: XMLDoc {
// For simplicity, we specify that the four documents
// pairwise disjoint. That's not actually required
// by the figure or by the nature of the case. But
// reasoning about it would require a better definition
// of XML document identity than I want to bother
// with now.
disj[Doc, Sch, Tmp, Res]
// How the connections work
p.ins = ( document -> Doc + schema -> Sch )
and p.outs = ( result -> Res)
and x.ins = ( document -> Doc )
and x.outs = ( result -> Tmp )
and v.ins = ( document -> Tmp + schema -> Sch)
and v.outs = ( result -> Res )
}
This code is used in < Define Figure_1 predicate 25 >
// Ports on the pipeline
// N.B. ports on the components are described in xproc02
dom[p.ins] = document + schema
dom[p.outs] = result
// Data flows. Here is another way to define the flows.
x.ins[document] = p.ins[document]
v.ins[document] = x.outs[result]
v.ins[schema] = p.ins[schema]
p.outs[result] = v.outs[result]
disj[p.ins[document], p.ins[schema],
p.outs[result], x.outs[result]]
This code is not used elsewhere.Some manual repositioning of the document boxes and process ovals in an image editor can make it slightly easier to see the flow of the data.[8] (If the type is too narrow to read, a wider browser window will allow it to become larger.) Figure 3: The pipeline of figure 1, as an instantiation of the xproc02 model.
Figure 3: The pipeline of figure 1, as an instantiation of the xproc02 model.
 Figure 4: The pipeline of figure 1, as an instantiation of the xproc02 model.
Figure 4: The pipeline of figure 1, as an instantiation of the xproc02 model.
The Document input splits into two data streams; the fork has no box in the diagram and is not a component. We currently have no words or concepts to describe what is happening here. (Another apparent difference is only illusory: the outputs of the two Validate steps flow together, and the point at which they join is not a component. But this can be described using the concepts already introduced: the two data flows go into the same data sink.)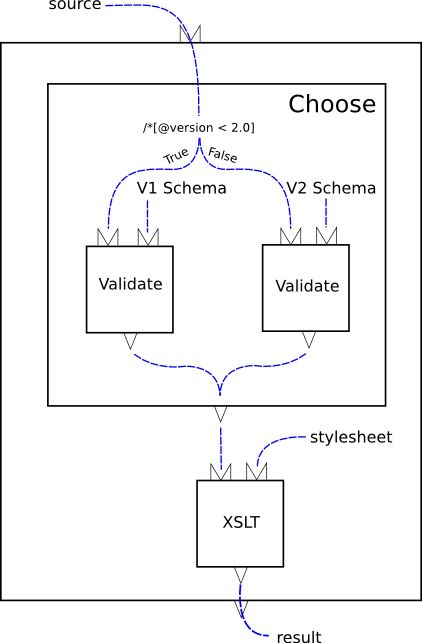 Figure 5: Figure 2 of the spec.
Figure 5: Figure 2 of the spec.
[Definition: A pipeline is a set of components connected together, with outputs flowing into inputs, without any loops (no component can read its own output, directly or indirectly).] A pipeline is itself a construct and must satisfy the constraints on constructs.
The result of evaluating a pipeline is the result of evaluating the components that it contains, in the order determined by the connections between them. A pipeline must behave as if it evaluated each component each time it occurs. Unless otherwise indicated, implementations must not assume that components are functional (that is, that their outputs depend only on their explicit inputs and parameters) or side-effect free.
Every construct contains zero or more components. [Definition: The components that occur directly inside a construct are called contained components.] [Definition: A construct which immediately contains a component is called its container.]
[Definition: The components (and the connections between them) within a container form a subpipeline.] Each construct determines how and which, if any, of its subpiplines is evaluated.
Steps and constructs have “ports” into which inputs and outputs are connected. Each component has a number of input ports and a number of output ports, all with unique names. A component can have zero input ports and/or zero output ports. (All components have an implicit standard output port for reporting errors that must not be declared.)
Components have any number of parameters, all with unique names. A component can have zero parameters.
It is a dynamic error if a non-XML resource is produced on a component output or arrives on a component input.
Each component declares its input and output ports. [Definition: The input ports declared on a component are its declared inputs.] [Definition: The output ports declared on a component are its declared outputs.]
All of the declared inputs of a component must be connected to outputs in the pipeline. It is a static error if a component has an input port which is not connected. Unconnected output ports are allowed; any documents produced on those ports are simply discarded.
[Definition: The signature of a component is the set of inputs, outputs, and parameters that it is declared to accept.] Each type of step (e.g. XSLT or XInclude) has a fixed signature, declared globally or built-in, which all its instances share, whereas each instance of a construct has its own signature declared locally.
[Definition: A component matches its signature if and only if it specifies an input for each declared input and it specifies no inputs that are not declared; it specifies a parameter for each parameter that is declared to be required; and it specifies no parameters that are not declared.] In other words, every input and required parameter must be specified and only inputs, outputs, and parameters that are declared may be specified. Outputs and optional parameters do not have to be specified.
Each input and output is declared to accept or produce either a single document or a sequence of documents. It is not a static error to connect a port that is declared to produce a sequence of documents to a port that is declared to accept only a single document. It is, however, a dynamic error if the former component actually produces more than a single document at run time.
Steps may also produce error, warning, and informative messages. These messages appear on a special “error output” that is available in the catch clause of a try/catch.
[Definition: A parameter is a QName/value pair.] The value of a parameter must be a string. If a document, node, or other value is given, its (XPath 1.0) string value is computed and that string is used.
Components are connected together by their inputs and outputs. [Definition: Components A and B are connected if they are either directly or indirectly connected. Component A is directly connected to B if an output of A is associated with an input port of B. Component A is indirectly connected to B if there is a chain of directly connected components that allows traversal from A to B.]
With respect to connected components, we can speak of one component being either before or after another. [Definition: Component A is before component B if component B is a contained component of component A, either directly or indirectly, or if any output from component A is connected to any input of component B, either directly or indirectly.] [Definition: Component A is after component B if component B is the container for component A (or an ancestor of such a container) or if any output from component B is connected to any input of component A, either directly or indirectly.]
It is a static error if a component is either before or after itself.
Every component in a pipeline has five parts: a set of inputs, a set of outputs, a set of parameters, a set of contained components, and a context inherited from its container. [Definition: The context is the the set of input ports, output ports, and parameter names that are visible.]
abstract sig Component {
ins : set Port,
outs : set Port,
parms : set Parameter,
components : set Component,
context : Context
}
abstract sig Step {}{
components = none
}
abstract sig Construct {}
This code is not used elsewhere.
sig Context {
sources : set Port,
sinks : set Port,
cparms : set Parameter
}
This code is not used elsewhere.The context of a [component] is its inherited context modified as follows:This is the context used by the pipeline and inher[i]ted by its contained components.
- All of the declared inputs of the [component] are added to the outputs in the context.
- The union of all the declared outputs of the contained components are added to the outputs in the context.
- All of the declared parameters of the [component] are added to the parameters in the context.
fun inherited_context(c0: Context,
i: set Port,
o: set Port,
p: set Parameter)
: Context {
one c : Context | c.sinks = c0.sinks
and c.sources = c0.sources + i + o
and c.cparms = c0.cparms + p
}
This code is not used elsewhere.The context of a choose is its inherited context modified as follows:This is the context used by the choose and inher[i]ted by its subpipelines.
- All of the declared inputs of the choose are added to the outputs in the context.
- The declared outputs of (any one of) the subpipelines are added to the outputs in the context.
- All of the declared parameters of the choose are added to the parameters in the context.
sig Pipeline {
}{
context = inherited_context(container.@context,
ins, components.@outs, parms)
}
This code is not used elsewhere.A pipeline encapsulates the behavior of a subpipeline.
There is one additional constraint imposed on pipelines: a pipeline must not itself be a contained component.
abstract sig Component {
ins : set Port,
outs : set Port,
parms : set Parameter,
container : lone Component,
components : set Component,
context : Context
}
This code is not used elsewhere.
sig OuterPipeline extends Pipeline {
}{
context.sources = ins,
context.sinks = outs,
context.cparms = parms,
container = none
}
This code is not used elsewhere.
sig Subpipeline extends Pipeline {
}{
context = inherited_context(container.@context,
ins, components.@outs, parms)
#container = 1 // or: some container
}
This code is not used elsewhere.
abstract sig Pipeline extends Construct {
}{
all c : components | c.@container = this
}
This code is not used elsewhere.
sig ForEach extends Construct {
}{
context = inherited_context(container.@context,
ins, components.@outs, parms)
#container = 1 // or: some container
{Signature constraints for For-each with subpipeline 38}
}
This code is not used elsewhere.#components = 1 components in SubpipelineContinued in <Signature constraints for For-each with subpipeline 39>
components.ins = none
components.outs = none
components.parms = none
{Additional signature constraints for For-each 40}
#ins = 1 // or: one insThis code is used in < Signature constraints for For-each with subpipeline 39 > < For-each (without subpipeline) 41 >
sig ForEach extends Subpipeline {
}{
{Additional signature constraints for For-each 40}
}
This code is not used elsewhere.
sig XPathExpression{}
sig Viewport extends Construct {
selection : XPathExpression
}{
context = inherited_context(container.@context,
ins, components.@outs, parms)
#container = 1 // or: some container
#components = 1
components in Subpipeline
components.ins = none
components.outs = none
components.parms = none
#ins = 1 // or: one ins
#outs = 1 // or: one outs
}
This code is not used elsewhere.
sig Viewport extends Subpipeline {
selection : XPathExpression
}{
#ins = 1
#outs = 1
}
This code is not used elsewhere.
sig Choose extends Construct {
XPath_context : lone Port
}{
{Signature constraints on Choose 45}
}
This code is not used elsewhere.XPath_context = insContinued in <Signature constraints on Choose 46>, <Subpipeline outputs constraint on Choose 47>, <Output constraint on Choose (first cut) 50>, <Signature constraints on Choose 52>, <Context calculation for Choose 53>
components in When + Otherwise #(Otherwise & components) = 1
All of the p:when branches and the p:otherwise must declare the same number of output ports with the same names. It is a static error if they do not.
all c1, c2 : Component |
if c1 + c2 in components
then c1.@outs = c2.@outs
outs = components.@outs
The context of a choose is its inherited context modified as follows:
- All of the declared inputs of the choose are added to the outputs in the context.
- The declared outputs of (any one of) the subpipelines are added to the outputs in the context.
- All of the declared parameters of the choose are added to the parameters in the context.
context = inherited_context(container.@context,
ins, components.@outs, parms)
context = inherited_context(container.@context,
ins, outs, none)
This code is not used elsewhere.
context = inherited_context(container.@context,
ins, none, none)
This code is not used elsewhere.If no context is specified on the p:when, the context specified on the p:choose is used. It is a static error if no context is specified in either place.
sig When extends Subpipeline {
XPath_context : one Port
test : XpathExpression
}{
lone ins
if #ins = 0
then XPath_context = container.XPath_context
else XPath_context = ins
}
This code is not used elsewhere.
sig Otherwise extends Subpipeline {
}{
ins = none
}
This code is not used elsewhere.Jackson, Daniel. Software abstractions: Logic, language, and analysis. Cambridge: MIT Press, 2006.
McMorran, Mike, and Steve Powell. Z guide for beginners. Oxford: Blackwell Scientific, 1993.
Potter, Ben, Jane Sinclair, and David Till. An introduction to formal specification and Z. New York: Prentice Hall, 1991.
Sperberg-McQueen, C. M. “SWEB: an SGML Tag Set for Literate Programming”. Unpublished paper. Available on the Web at <URL:http://www.w3.org/People/cmsmcq/1993/sweb.html>
Walsh, Norman, and Alex Milowski, ed. XProc: an XML Pipeline Language. W3C Working Draft 17 November 2006. [Cambridge, Sophia-Antipolis, Tokyo]: World Wide Web Consortium, 2006. On the Web at: <URL:http://www.w3.org/TR/2006/WD-xproc-20061117/>. Latest version: <URL:http://www.w3.org/TR/xproc/>.
Wordsworth, J. B. Software development with Z: A practical approach to formal method in software engineering.. Wokingham: Addison-Wesley, 1992.