This specification defines various scoping/encapsulation mechanisms for CSS, including scoped styles and the @scope rule, Shadow DOM selectors, and page/region-based styling.
CSS is a language for describing the rendering of structured documents
(such as HTML and XML)
on screen, on paper, in speech, etc.
Status of this document
This section describes the status of this document at the time of
its publication. Other documents may supersede this document. A list of
current W3C publications and the latest revision of this technical report
can be found in the W3C technical reports
index at http://www.w3.org/TR/.
This document is a First Public Working Draft.
Publication as a First Public Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
The (archived) public
mailing list www-style@w3.org (see
instructions) is preferred
for discussion of this specification. When sending e-mail, please put the
text “css-scoping” in the subject, preferably like this:
“[css-scoping] …summary of comment…”
The cascade prioritizes scoped rules over unscoped ones, regardless of specificity.
See Cascading by Scope in [CSS3CASCADE].
2.1
Scoping Mechanisms
Style rules can be scoped using constructs defined in the document language
or using the @scope rule in CSS.
2.1.1
Document Markup for Scoping
Document languages may define a mechanism for a stylesheet to be scoped to some element in the document.
For example, in HTML,
a style element with a scoped attribute
defines a stylesheet that is scoped to the style element’s parent element.
[HTML]
This rule makes it very easy for authors to create scoped style sheets,
which could affect the optimization strategies for implementing scoped styles.
If multiple elements match the <selector>,
the <stylesheet> is effectively duplicated
and scoped independently to each one.
Authors should avoid using overly-generic selectors
as it can have confusing interactions with the cascade.
A scoped stylesheet is attached not only to the outermost scoping element,
but to all matching elements.
For example, given the style sheet below
@scope rules can be nested.
In this case, just as with the nested style rules,
the selector of an outer @scope scope-contains
the selector of the inner one.
The specificity of selectors inside the @scope rule is calculated locally:
the selector specifying the scoping element is ignored.
However, because scoped styles override non-scoped styles,
style rules inside the @scope will override rules outside of it.
In the following example, the text would be green:
@scope aside {
p { color: green; }
}
aside#sidebar p { color: red; }
If multiple @scope rules apply to an element,
should they be cascaded by specificity?
2.2
Querying the Scoping Context
2.2.1
Selecting the Scoping Root: :scope pseudo-class
However, since for scoped stylesheets you may want the ability to match complex selectors against the outside tree,
rather than a single compound selector,
we may want to instead use a more general mechanism that doesn’t syntactically invert the order of tree elements.
This functionality would replace @global, which is a poor excuse for a selector.
3
Shadow Encapsulation
The Shadow DOM spec augments the DOM with several new concepts,
several of which are relevant to CSS.
A shadow tree is a document fragment
that can be attached to any element in the DOM.
The root of the shadow tree is a shadow root,
a non-element node which is associated with a shadow host.
An element can have any number of shadow trees,
which are ordered by creation time.
The most recently-created shadow tree on an element
is the active shadow tree for that element.
An element with a shadow tree is a shadow host.
It is the host element for its shadow trees.
The descendants of a shadow host
must not generate boxes in the formatting tree.
Instead, the contents of the active shadow tree generate boxes
as if they were the contents of the element instead.
In several instances in shadow DOM,
elements don’t have element parents
(instead, they may have a shadow root as parent,
or something else).
An element without a parent,
or whose parent is not an element,
is called a top-level element.
While the children of a shadow host do not generate boxes normally,
they can be explicitly pulled into a shadow tree and forced to render normally.
This is done by assigning the elements to a distribution list.
An element with a distribution list is an insertion point.
This specification does not define how to assign elements to a distribution list,
instead leaving that to the Shadow DOM spec.
At the time this spec is written, however,
only content elements in a shadow tree can have distribution lists.
Note: The "descendants" of an element
are based on the children of the element,
which does not include the shadow trees or distribution lists of the element.
The host element is not selectable by any means
except for the :host and :host-context() pseudo-classes.
That is, in this context the shadow host
has no tagname, ID, classes, or attributes,
and the only additional information is has is that the :host pseudo-class matches it.
In particular, the host element isn’t matched by the * selector either.
Why is the shadow host so weird?
The shadow host lives outside the shadow tree,
and its markup is in control of the page author,
not the component author.
It would not be very good if a component used a particular class name
internally in a shadow tree,
and the page author using the component accidentally also
used the the same class name and put it on the host element.
Such a situation would result in accidental styling
that is impossible for the component author to predict,
and confusing for the page author to debug.
However, there are still some reasonable use-cases for letting a stylesheet in a shadow tree
style its host element.
So, to allow this situation but prevent accidental styling,
the host element appears but is completely featureless
and unselectable except through :host.
3.2
Shadow DOM Selectors
Shadow DOM defines a few new selectors
to help select elements in useful way related to Shadow DOM.
This section is still under discussion.
Feedback and advice on intuitive syntax for the following functionality
would be appreciated.
The :host pseudo-class,
when evaluated in the context of a shadow tree,
matches the shadow tree’shost element.
In any other context,
it matches nothing.
When evaluated in the context of a shadow tree,
it matches the shadow tree’shost element
if the host element,
in its normal context,
matches the selector argument.
In any other context,
it matches nothing.
For example, say you had a component with a shadow tree like the following:
Ordinary, selectors within a shadow tree
can’t see elements outside the shadow tree at all.
Sometimes, however, it’s useful to select an ancestor that lies somewhere outside the shadow tree,
above it in the document.
For example, a group of components can define a handful of color themes
they they know how to respond to.
Page authors could opt into a particular theme
by adding a specific class to the components,
or higher up in the document.
The :host-context() functional pseudo-class tests whether there is an ancestor,
outside the shadow tree,
which matches a particular selector.
Its syntax is:
Note: This means that the selector pierces through shadow boundaries on the way up,
looking for elements that match its argument,
until it reaches the document root.
3.2.2
Selecting Into the Dark: the ::shadow pseudo-element
The ::shadow pseudo-element must not generate boxes,
unless specified otherwise in another specification.
However, for the purpose of Selectors,
the ::shadow pseudo-element is considered to be the root of the shadow tree,
with the top-level elements in the shadow tree the direct children of the ::shadow pseudo-element.
For example, say you had a component with a shadow tree like the following:
For a stylesheet in the outer document,
x-foo::shadow > span matches #top,
but not #not-top,
because it’s not a top-level element in the shadow tree.
If one wanted to target #not-top,
one way to do it would be with x-foo::shadow > div > span.
However, this introduces a strong dependency on the internal structure of the component;
in most cases, it’s better to use the descendant combinator,
like x-foo::shadow span,
to select all the elements of some type in the shadow tree.
Similarly,
inside of a shadow tree,
a selector like :host::shadow div selects the div elements in all the shadow trees on the element,
not just the one containing that selector.
3.2.3
Selecting Shadow-Projected Content: the ::content pseudo-element
The ::content pseudo-element matches the distribution list itself,
on elements that have one.
::content is a confusingly general name for something that is specific
to the projected content of a shadow tree.
The ::content pseudo-element must not generate boxes,
unless specified otherwise in another specification.
However, for the purpose of Selectors,
the ::content pseudo-element is considered to be the parent of the elements in the distribution list.
For example, say you had a component with both children and a shadow tree,
like the following:
For a stylesheet within the shadow tree,
a selector like ::content div
selects #one, #three, and #four,
as they’re the elements distributed by the sole content element,
but not #two.
If only the top-level elements distributed the content element are desired,
a child combinator can be used,
like ::content > div,
which will exclude #four
as it’s not treated as a child of the ::content pseudo-element.
Note: Note that a selector like ::content div
is equivalent to *::content div,
where the * selects many more elements that just the content element.
However, since only the content element has a distribution list,
it’s the only element that has a ::content pseudo-element as well.
3.2.4
Selecting Through Shadows: the /deep/ combinator
When a /deep/ combinator is encountered in a selector,
replace every element in the selector match list
with every element reachable from the original element
by traversing any number of child lists or shadow trees.
For example, say you had a component with a shadow tree like the following:
For a stylesheet in the outer document,
the selector x-foo /deep/ span
selects all three of <span> elements:
#top, #not-top, and#nested.
This is basically a super-descendant combinator.
If the descendant combinator had a real glyph,
it would potentially be interesting to just double it.
Maybe we can give the descendant combinator a pseudonym of >>,
as it itself is a super-child combinator?
Then /deep/ could be spelled >>>
3.3
Shadow Cascading & Inheritance
3.3.1
Cascading
To address the desired cascading behavior of rules targetting elements in shadow roots,
this specification extends the cascade order
defined in the Cascade specification. [CSS3CASCADE]
An additional cascade criteria must be added,
between Origin and Scope,
called Shadow Tree.
When comparing two declarations,
if one of them is in a shadow tree
and the other is in a document that contains that shadow tree,
then for normal rules the declaration from the outer document wins,
and for important rules the declaration from the shadow tree wins.
Note: This is the opposite of how scoped styles work.
When comparing two declarations,
if both are in shadow trees with the same host element,
then for normal rules the declaration from the shadow tree that was created most recently wins,
and for important rules the declaration from the shadow tree that was created less recently wins.
When calculating Order of Appearance,
the tree of trees,
defined by the Shadow DOM specification,
is used to calculate ordering.
The elements in a distribution list inherit from the parent of the content element they are ultimately distributed to,
rather than from their normal parent.
4
Fragmented Styling
Fragmented content can be styled differently
based on which line, column, page, region, etc.
it appears in.
This is done by using an appropriate fragment pseudo-element,
which allows targetting individual fragments of an element
rather than the entire element.
In our example,
the designer wants to make
text flowing into #region1
dark blue and bold.
This design can be expressed as shown below.
#region1::region p {
color: #0C3D5F;
font-weight: bold;
}
The ::region pseudo-element
is followed by a p relative selector in this example.
The color and font-weight declarations will apply
to any fragments of paragraphs that are
displayed in #region1.
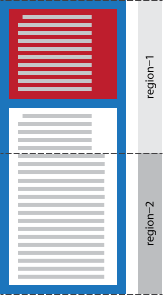
The following figure shows how
the rendering changes
if we apply this styling specific to #region1.
Note how less text fits into this box
now that the font-weight is
bold instead of normal.
Different rendering with a different region styling
Note: This feature is an extension of ::first-line styling.
4.1
Region-based Styling: the ::region pseudo-element
A ::region pseudo-element represents a relationship between
a selector that matches a CSS Region,
and a relative selector that matches some named flow content.
This allows style declarations to be applied
to fragments of named flow content flowing
into particular regions.
When the ::region pseudo-element is appended to a
selector
that matches one or more CSS Regions,
this creates a 'flow fragment' selector.
The flow fragment selector specifies
which range of elements in the flow
can be matched by the relative selector.
The relative selector can match elements
in the range(s) (see [DOM]) of the named flow
that are displayed fully or partially
in the selected region(s).
Elements that are fully or partially
in the flow fragment range may match the relative selector.
However, the style declarations only apply
to the fragment of the element
that is displayed in the corresponding region(s).
Only a limited list of properties apply to a ::region pseudo-element:
Either this list should be all functionally inheritable properties,
or all properties.
Why is it a seemingly-arbitrary subset of all properties, including box properties?
The region styling applies
to flow content that fits in region-1.
The relative selector matches p-1 and p-2
because these paragraphs
flow into region-1.
Only the fragment of p-2
that flows into region-1
is styled with the pseudo-element.
All of the selectors
in a ::region pseudo-element
contribute to its specificity.
So the specificity of the ::region pseudo-element
in the example above would combine
the id selector’s specificity
with the specificity of the type selector,
resulting in a specificity of 101.
Selectors that match a given element or element fragment (as described above),
participate in the CSS Cascading
order as defined in [CSS21].
Region styling does not apply to nested regions. For example, if a region
A receives content from a flow that contains region B, the content that
flows into B does not receive the region styling specified for region A.
We’ll need some way to query the styles of a fragment in a particular region.
getComputedStyle() isn’t enough,
because an element can exist in multiple regions, for example,
with each fragment receiving different styles.
Conformance
Document conventions
Conformance requirements are expressed with a combination of
descriptive assertions and RFC 2119 terminology. The key words "MUST",
"MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT",
"RECOMMENDED", "MAY", and "OPTIONAL" in the normative parts of this
document are to be interpreted as described in RFC 2119.
However, for readability, these words do not appear in all uppercase
letters in this specification.
All of the text of this specification is normative except sections
explicitly marked as non-normative, examples, and notes. [RFC2119]
Examples in this specification are introduced with the words "for example"
or are set apart from the normative text with class="example",
like this:
This is an example of an informative example.
Informative notes begin with the word "Note" and are set apart from the
normative text with class="note", like this:
Note, this is an informative note.
Conformance classes
Conformance to this specification
is defined for three conformance classes:
A style sheet is conformant to this specification
if all of its statements that use syntax defined in this module are valid
according to the generic CSS grammar and the individual grammars of each
feature defined in this module.
A renderer is conformant to this specification
if, in addition to interpreting the style sheet as defined by the
appropriate specifications, it supports all the features defined
by this specification by parsing them correctly
and rendering the document accordingly. However, the inability of a
UA to correctly render a document due to limitations of the device
does not make the UA non-conformant. (For example, a UA is not
required to render color on a monochrome monitor.)
An authoring tool is conformant to this specification
if it writes style sheets that are syntactically correct according to the
generic CSS grammar and the individual grammars of each feature in
this module, and meet all other conformance requirements of style sheets
as described in this module.
Partial implementations
So that authors can exploit the forward-compatible parsing rules to
assign fallback values, CSS renderers must
treat as invalid (and ignore
as appropriate) any at-rules, properties, property values, keywords,
and other syntactic constructs for which they have no usable level of
support. In particular, user agents must not selectively
ignore unsupported component values and honor supported values in a single
multi-value property declaration: if any value is considered invalid
(as unsupported values must be), CSS requires that the entire declaration
be ignored.
Experimental implementations
To avoid clashes with future CSS features, the CSS2.1 specification
reserves a prefixed
syntax for proprietary and experimental extensions to CSS.
Prior to a specification reaching the Candidate Recommendation stage
in the W3C process, all implementations of a CSS feature are considered
experimental. The CSS Working Group recommends that implementations
use a vendor-prefixed syntax for such features, including those in
W3C Working Drafts. This avoids incompatibilities with future changes
in the draft.
Non-experimental implementations
Once a specification reaches the Candidate Recommendation stage,
non-experimental implementations are possible, and implementors should
release an unprefixed implementation of any CR-level feature they
can demonstrate to be correctly implemented according to spec.
To establish and maintain the interoperability of CSS across
implementations, the CSS Working Group requests that non-experimental
CSS renderers submit an implementation report (and, if necessary, the
testcases used for that implementation report) to the W3C before
releasing an unprefixed implementation of any CSS features. Testcases
submitted to W3C are subject to review and correction by the CSS
Working Group.
This rule makes it very easy for authors to create scoped style sheets,
which could affect the optimization strategies for implementing scoped styles.
↵
If multiple @scope rules apply to an element,
should they be cascaded by specificity?
↵
However, since for scoped stylesheets you may want the ability to match complex selectors against the outside tree,
rather than a single compound selector,
we may want to instead use a more general mechanism that doesn’t syntactically invert the order of tree elements.
This section is still under discussion.
Feedback and advice on intuitive syntax for the following functionality
would be appreciated.
↵
::content is a confusingly general name for something that is specific
to the projected content of a shadow tree.
↵
This is basically a super-descendant combinator.
If the descendant combinator had a real glyph,
it would potentially be interesting to just double it.
Maybe we can give the descendant combinator a pseudonym of >>,
as it itself is a super-child combinator?
Then /deep/ could be spelled >>> ↵
Either this list should be all functionally inheritable properties,
or all properties.
Why is it a seemingly-arbitrary subset of all properties, including box properties?
↵
We’ll need some way to query the styles of a fragment in a particular region.
getComputedStyle() isn’t enough,
because an element can exist in multiple regions, for example,
with each fragment receiving different styles.
↵