4 Requirements
4.1 Standard Names for Component Inventory [req-standard-names]
The XML Pipeline Specification Document must have standard names for components that correspond, but not limited to, the following specifications [xml-core-wg]:
-
XML Base
-
XInclude
-
XSLT 1.0/2.0
-
XSL FO
-
XML Schema
-
XQuery
-
RelaxNG
4.3 Minimal Component Support for Interoperability [req-minimal-components]
There must be a minimal inventory of components defined by the specification that are required to be supported to facilitate interoperability of XML Pipelines.
4.5 Iteration of Documents and Elements [req-iteration]
XML Pipelines should allow iteration of a specific set of steps over a collection of documents and or elements within a document.
4.6 Conditional Processing of Inputs [req-conditional-processing]
To allow run-time selection of steps, XML Pipelines should provide mechanisms for conditional processing of documents or elements within documents based on expression evaluation. [xml-core-wg]
4.7 Error Handling and Fall-back [req-error-handling-fallback]
XML Pipelines must provide mechanisms for addressing error handling and fall-back behaviors. [xml-core-wg]
4.8 Support for the XPath 2.0 Data Model [req-xdm]
XML Pipelines must support the XPath 2.0 Data Model to allow support for XPath 2.0, XSLT 2.0, and XQuery as steps.
Note:
At this point, there is no consensus in the working group that minimal conforming implementations are required to support the XPath 2.0 Data Model.
4.9 Allow Optimization [req-allow-optimization]
An XML Pipeline should not inhibit a sophisticated implementation from performing parallel operations, lazy or greedy processing, and other optimizations. [xml-core-wg]
4.10 Streaming XML Pipelines [req-streaming-pipes]
An XML Pipeline should allow for the existence of streaming pipelines in certain instances as an optional optimization. [xml-core-wg]
5 Use cases
This section contains a set of use cases that support our requirements and will inform our design. While there is a want to address all the use cases listed in this document, in the end, the first version of those specifications may not solve all the following use cases. Those unsolved use cases may be address in future versions of those specifications.
To aid navigation, the requirements can be mapped to the use cases of this section as follows:
| Requirement |
Use Cases |
| 4.9 Allow Optimization |
5.29 Large-Document Subtree Iteration, 5.30 Adding Navigation to an Arbitrarily Large Document |
| 4.10 Streaming XML Pipelines |
5.29 Large-Document Subtree Iteration, 5.30 Adding Navigation to an Arbitrarily Large Document |
| 4.2 Allow Defining New Components and Steps |
5.9 Run a Custom Program, 5.27 Integrate Computation Components (MathML) |
| 4.7 Error Handling and Fall-back |
5.32 No Fallback for XQuery Causes Error, 5.31 Fallback to Choice of XSLT Processor |
| 4.6 Conditional Processing of Inputs |
5.21 Content-Dependent Transformations, 5.30 Adding Navigation to an Arbitrarily Large Document |
| 4.1 Standard Names for Component Inventory |
5.3 Parse/Validate/Transform, 5.2 XInclude Processing |
| 4.3 Minimal Component Support for Interoperability |
5.3 Parse/Validate/Transform, 5.2 XInclude Processing |
| 4.4 Allow Pipeline Composition |
5.23 Response to XML-RPC Request, 5.24 Database Import/Ingestion, 5.15 Parse and/or Serialize RSS descriptions |
| 4.5 Iteration of Documents and Elements |
5.15 Parse and/or Serialize RSS descriptions, 5.6 Multiple-file Command-line Document Generation, 5.11 Make Absolute URLs, 5.24 Database Import/Ingestion |
| 4.8 Support for the XPath 2.0 Data Model |
5.16 XQuery and XSLT 2.0 Collections |
Note:
The above table is known to be incomplete and will be completed in a later draft.
5.1 Apply a Sequence of Operations [use-case-apply-sequence]
Apply a sequence of operations such XInclude, validation, and transformation to a document, aborting if the result or an intermediate stage is not valid.
(source: [xml-core-wg])
5.2 XInclude Processing [use-case-xinclude]
-
Retrieve a document containing XInclude instructions.
-
Locate documents to be included.
-
Perform XInclude inclusion.
-
Return a single XML document.
(source: Erik Bruchez)
5.3 Parse/Validate/Transform [use-case-parse-validate-transform]
-
Parse the XML.
-
Perform XInclude.
-
Validate with Relax NG, possibly aborting if not valid.
-
Validate with W3C XML Schema, possibly aborting if not valid.
-
Transform.
(source: Norm Walsh)
5.4 Document Aggregation [use-case-document-aggregation]
-
Locate a collection of documents to aggregate.
-
Perform aggregation under a new document element.
-
Return a single XML document.
(source: Erik Bruchez)
5.5 Single-file Command-line Document Processing [use-case-simple-command-line]
-
Read a DocBook document.
-
Validate the document.
-
Process it with XSLT.
-
Validate the resulting XHTML.
-
Save the HTML file using HTML serialization.
(source: Erik Bruchez)
5.6 Multiple-file Command-line Document Generation [use-case-multiple-command-line]
-
Read a list of source documents.
-
For each document in the list:
-
Read the document.
-
Perform a series of XSLT transformations.
-
Serialize each result.
-
Alternatively, aggregate the resulting documents and serialize a single result.
(source: Erik Bruchez)
5.7 Extracting MathML [use-case-extract-mathml]
Extract MathML fragments from an XHTML document and render them as images. Employ an SVG renderer for SVG glyphs embedded in the MathML.
(source: [xml-core-wg])
5.8 Style an XML Document in a Browser [use-case-style-browser]
Style an XML document in a browser with one of several different stylesheets without having multiple copies of the document containing different xml-stylesheet directives.
(source: [xml-core-wg])
5.9 Run a Custom Program [use-case-run-program]
Run a program of your own, with some parameters, on an XML file and display the result in a browser.
(source: [xml-core-wg])
5.10 XInclude and Sign [use-case-xinclude-dsig]
-
Process an XML document through XInclude.
-
Transform the result with XSLT using a fixed transformation.
-
Digitally sign the result with XML Signatures.
(source: Henry Thompson)
5.11 Make Absolute URLs [use-case-make-absolute-urls]
-
Process an XML document through XInclude.
-
Remove any xml:base attributes anywhere in the resulting document.
-
Schema validate the document with a fixed schema.
-
For all elements or attributes whose type is xs:anyURI, resolve the value against the base URI to create an absolute URI. Replace the value in the document with the resulting absolute URI.
This example assumes preservation of infoset ([base URI]) and PSVI ([type definition]) properties from step to step. Also, there is no way to reorder these steps as the schema doesn't accept xml:base attributes but the expansion requires xs:anyURI typed values.
(source: Henry Thompson)
5.12 A Simple Transformation Service [use-case-simple-transform-service]
-
Extract XML document (XForms instance) from an HTTP request body
-
Execute XSLT transformation on that document.
-
Call a persistence service with resulting document
-
Return the XML document from persistence service (new XForms instance) as the HTTP response body.
(source: Erik Bruchez)
5.13 Service Request/Response Handling on a Handheld [use-case-handheld-service]
Allow an application on a handheld device to construct a pipeline, send the pipeline and some data to the server, allow the server to process the pipeline and send the result back.
(source: [xml-core-wg])
5.14 Interact with Web Service (Tide Information) [use-case-web-service]
-
Parse the incoming XML request.
-
Construct a URL to a REST-style web service at the NOAA (see website).
-
Parse the resulting invalid HTML document with by translating and fixing the HTML to make it XHTML (e.g. use TagSoup or tidy).
-
Extract the tide information from a plain-text table of data from document by applying a regular expression and creating markup from the matches.
-
Use XQuery to select the high and low tides.
-
Formulate an XML response from that tide information.
(source: Alex Milowski)
5.15 Parse and/or Serialize RSS descriptions [use-case-rss-descriptions]
Parse descriptions:
-
Iterate over the RSS description elements and do the following:
-
Gather the text children of the 'description' element.
-
Parse the contents with a simulated document element in the XHTML namespace.
-
Send the resulting children as the children of the 'description element.
-
Apply rest of pipeline steps.
Serialize descriptions
-
Iterate over the RSS description elements and do the following:
-
Serialize the children elements.
-
Generate a new child as a text children containing the contents (escaped text).
-
Apply rest of pipeline steps.
(source: Alex Milowski)
5.16 XQuery and XSLT 2.0 Collections [use-case-collections]
In XQuery and XSLT 2.0 there is the idea of an input and output collection and a pipeline must be able to consume or produce collections of documents both as inputs or outputs of steps as well as whole pipelines.
For example, for input collections:
-
Accept a collection of documents.
-
Apply a single XSLT 2.0 transformation that processes the collection and produces another collection.
-
Serialize the collection to files or URIs.
For example, for output collections:
-
Accept a single document as input.
-
Apply an XQuery that produces a sequence of documents (a collection).
-
Serialize the collection to files or URIs.
5.17 An AJAX Server [use-case-ajax-server]
-
Receive XML request with word to complete.
-
Call a sub-pipeline that retrieves list of completions for that word.
-
Format resulting document with XSLT.
-
Serialize response to XML.
(source: Erik Bruchez)
5.18 Dynamic XQuery [use-case-dynamic-xquery]
-
Dynamically create an XQuery query using XSLT, based on input XML document.
-
Execute the XQuery against a database.
-
Construct an XHTML result page using XSLT from the result of the query.
-
Serialize response to HTML.
(source: Erik Bruchez)
5.19 Read/Write Non-XML File [use-case-rw-non-xml]
-
Read a CSV file and convert it to XML.
-
Process the document with XSLT.
-
Convert the result to a CSV format using text serialization.
(source: Erik Bruchez)
5.20 Update/Insert Document in Database [use-case-update-insert-db]
-
Receive an XML document to save.
-
Check the database to see if the document exists.
-
If the document exists, update the document.
-
If the document does not exists, add the document.
(source: Erik Bruchez)
5.21 Content-Dependent Transformations [use-case-content-depend]
-
Receive an XML document to format.
-
If the document is XHTML, apply a theme via XSLT and serialize as HTML.
-
If the document is XSL-FO, apply an XSL FO processor to produce PDF.
-
Otherwise, serialize the document as XML.
(source: Erik Bruchez)
5.22 Configuration-Dependent Transformations [use-case-config-depend]
Mobile example:
-
Receive an XML document to format.
-
If the configuration is "desktop browser", apply desktop XSLT and serialize as HTML.
-
If the configuration is "mobile browser", apply mobile XSLT and serialize as XHTML.
News feed example:
-
Receive an XML document in Atom format.
-
If the configuration is "RSS 1.0", apply "Atom to RSS 1.0" XSLT.
-
If the configuration is "RSS 2.0", apply "Atom to RSS 2.0" XSLT.
-
Serialize the document as XML.
(source: Erik Bruchez)
5.23 Response to XML-RPC Request [use-case-xml-rpc]
-
Receive an XML-RPC request.
-
Validate the XML-RPC request with a RelaxNG schema.
-
Dispatch to different sub-pipelines depending on the content of /methodCall/methodName.
-
Format the sub-pipeline response to XML-RPC format via XSLT.
-
Validate the XML-RPC response with an W3C XML Schema.
-
Return the XML-RPC response.
(source: Erik Bruchez)
5.24 Database Import/Ingestion [use-case-import-ingestion]
Import example:
-
Read a list of source documents.
-
For each document in the list:
-
Validate the document.
-
Call a sub-pipeline to insert content into a relational or XML database.
Ingestion example:
-
Receive a directory name.
-
Produce a list of files in the directory as an XML document.
-
For each element representing a file:
-
Create an iTQL query using XSLT.
-
Query the repository to check if the file has been uploaded.
-
Upload if necessary.
-
Inspect the file to check the metadata type.
-
Transform the document with XSLT.
-
Make a SOAP call to ingest the document.
(source: Erik Bruchez)
5.25 Metadata Retrieval [use-case-metadata]
-
Call a SOAP service with metadata format as a parameter.
-
Create an iTQL query with XSLT.
-
Query a repository for the XML document.
-
Load a list of XSLT transformations from a configuration.
-
Iteratively execute the XSLT transformations.
-
Serialize the result to XML.
(source: Erik Bruchez)
5.26 Non-XML Document Production [use-case-non-xml-production]
-
An non-XML document is fed into the process.
-
That input is converted into a well-formed XML document.
-
A table of contents is extracted.
-
Pagination is performed.
-
Each page is transformed into some output language.
(source: Rui Lopes)
-
Read a non-XML document.
-
Transform.
(source: Norm Walsh)
5.27 Integrate Computation Components (MathML) [use-case-computations]
-
Select a MathML content element.
-
For that element, apply a computation (e.g. compute the kernel of a matrix).
-
Replace the input MathML with the output of the computation.
(source: Alex Milowski)
5.28 Document Schema Definition Languages (DSDL) - Part 10: Validation Management [use-case-dsdl-validation]
This document provides a test scenario that will be used to create validation management scripts using a range of existing techniques, including those used for program compilation, etc.
The steps required to validate our sample document are:
-
Use ISO 19757-4 Namespace-based Validation Dispatching Language (NVDL) to split out the parts of the document that are encoded using HTML, SVG and MathML from the bulk of the document, whose tags are defined using a user-defined set of markup tags.
-
Validate the HTML elements and attributes using the HTML 4.0 DTD (W3C XML DTD).
-
Use a set of Schematron rules stored in check-metadata.xml to ensure that the metadata of the HTML elements defined using Dublin Core semantics conform to the information in the document about the document's title and subtitle, author, encoding type, etc.
-
Validate the SVG components of the file using the standard W3C schema provided in the SVG 1.2 specification.
-
Use the Schematron rules defined in SVG-subset.xml to ensure that the SVG file only uses those features of SVG that are valid for the particular SVG viewer available to the system.
-
Validate the MathML components using the latest version of the MathML schema (defined in RELAX-NG) to ensure that all maths fragments are valid. The schema will make use the datatype definitions in check-maths.xml to validate the contents of specific elements.
-
Use MathML-SVG.xslt to transform the MathML segments to displayable SVG and replace each MathML fragment with its SVG equivalent.
-
Use the ISO 19757-8 Document Schema Renaming Language (DSRL) definitions in convert-mynames.xml to convert the tags in the local nameset to the form that can be used to validate the remaining part of the document using docbook.dtd.
-
Use the IS0 19757-7 Character Repertoire Definition Language (CRDL) rules defined in mycharacter-checks.xml to validate that the correct character sets have been used for text identified as being Greek and Cyrillic.
-
Convert the Docbook tags to HTML so that they can be displayed in a web browser using the docbook-html.xslt transformation rules.
Each validation script should allow the four streams produced by step 1 to be run in parallel without requiring the other validations to be carried out if there is an error in another stream. This means that steps 2 and 3 should be carried out in parallel to steps 4 and 5, and/or steps 6 and 7 and/or steps 8 and 9. After completion of step 10 the HTML (both streams), and SVG (both streams) should be recombined to produce a single stream that can fed to a web browser. The flow is illustrated in the
following diagram:
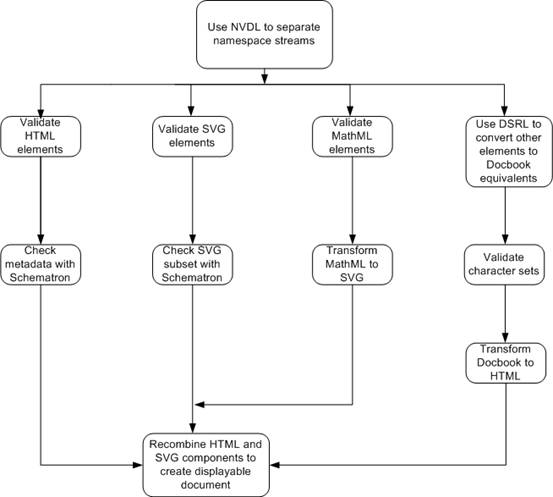
(source: Martin Bryan)
5.29 Large-Document Subtree Iteration [use-case-large-document-transform]
Running XSLT on a very large document isn't typically practical. In these cases, it is often the case that a particular element, that may be repeated over-and-over again, needs to be transformed. Conceptually, a pipeline could limit the transformation to a subtree by:
-
Limiting the transform to a subtree of the document identified by an XPath.
-
For each subtree, cache the subtree and build a whole document with the identified element as the document element and then run a transform to replace that subtree in the original document.
-
For any non-matches, the document remains the same and "streams" around the transform.
This allows the transform and the tree building to be limited to a small subtree and the rest of the process to stream. As such, an arbitrarily large document can be processed in a bounded amount of memory.
(source: Alex Milowski)
5.30 Adding Navigation to an Arbitrarily Large Document [use-case-add-nav]
For a particular website, every XHTML document needs to have navigation elements added to the document. The navigation is static text that surrounds the body of the document. This navigation is added by:
-
Matching the head and body elements using a XPath expression that can be streamed.
-
Inserting a stub for a transformation for including the style and surrounding navigation of the site.
-
For each of the stubs, transformations insert the markup using a subtree expansion that allows the rest of the document to stream.
In the end, the pipeline allows arbitrarily large XHTML document to be processed with a near-constant cost.
(source: Alex Milowski)
5.31 Fallback to Choice of XSLT Processor [use-case-fallback-choice]
A step in a pipeline produces multiple output documents. In XSLT 2.0, this is a standard feature of all XSLT 2.0 processors. In XSLT 1.0, this is not standard.
A pipeline author wants to write a pipeline that, at compile-time, the implementation chooses XSLT 2.0 when possible and degrades to XSLT 1.0 when XSLT 2.0 is not supported. In the case of XSLT 1.0, the step will use XSLT extensions to support the multiple output documents--which again may fail. Fortunately, the XSLT 1.0 transformation can be written to test for this.
(source: Alex Milowski)
5.32 No Fallback for XQuery Causes Error [use-case-no-fallback-error]
As the final step in a pipeline, XQuery is required to be run. If the XQuery step is not available, the compilation of the pipeline needs to fail. Here the pipeline author has chosen that the pipeline must not run if XQuery is not available.
(source: Alex Milowski)