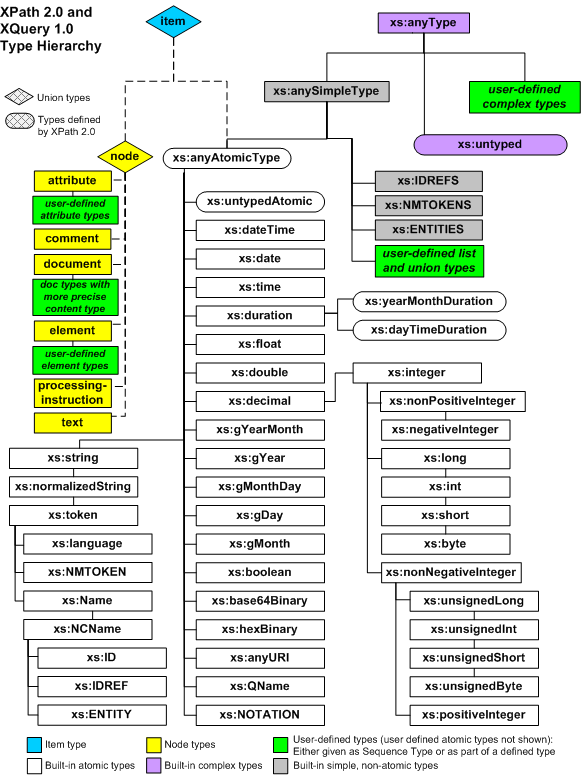
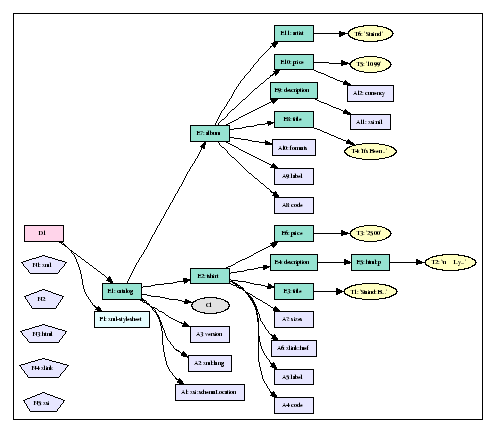
| // Document node D1 |
| dm:base-uri(D1) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(D1) |
= |
"document" |
| dm:string-value(D1) |
= |
" Staind: Been Awhile Tee Black (1-sided) \n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n 25.00
It's Been A While 10.99 Staind " |
| dm:typed-value(D1) |
= |
xdt:untypedAtomic(" Staind: Been Awhile Tee Black (1-sided) \n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n
25.00 It's Been A While 10.99 Staind ") |
| dm:children(D1) |
= |
([E1]) |
| |
| // Namespace node N1 |
| dm:node-kind(N1) |
= |
"namespace" |
| dm:node-name(N1) |
= |
xs:QName("", "xml") |
| dm:string-value(N1) |
= |
"http://www.w3.org/XML/1998/namespace" |
| dm:typed-value(N1) |
= |
"http://www.w3.org/XML/1998/namespace" |
| |
| // Namespace node N2 |
| dm:node-kind(N2) |
= |
"namespace" |
| dm:node-name(N2) |
= |
() |
| dm:string-value(N2) |
= |
"http://www.example.com/catalog" |
| dm:typed-value(N2) |
= |
"http://www.example.com/catalog" |
| |
| // Namespace node N3 |
| dm:node-kind(N3) |
= |
"namespace" |
| dm:node-name(N3) |
= |
xs:QName("", "html") |
| dm:string-value(N3) |
= |
"http://www.w3.org/1999/xhtml" |
| dm:typed-value(N3) |
= |
"http://www.w3.org/1999/xhtml" |
| |
| // Namespace node N4 |
| dm:node-kind(N4) |
= |
"namespace" |
| dm:node-name(N4) |
= |
xs:QName("", "xlink") |
| dm:string-value(N4) |
= |
"http://www.w3.org/1999/xlink" |
| dm:typed-value(N4) |
= |
"http://www.w3.org/1999/xlink" |
| |
| // Namespace node N5 |
| dm:node-kind(N5) |
= |
"namespace" |
| dm:node-name(N5) |
= |
xs:QName("", "xsi") |
| dm:string-value(N5) |
= |
"http://www.w3.org/2001/XMLSchema-instance" |
| dm:typed-value(N5) |
= |
"http://www.w3.org/2001/XMLSchema-instance" |
| |
| // Processing Instruction node P1 |
| dm:base-uri(P1) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(P1) |
= |
"processing-instruction" |
| dm:node-name(P1) |
= |
xs:QName("", "xml-stylesheet") |
| dm:string-value(P1) |
= |
"type="text/xsl" href="dm-example.xsl"" |
| dm:typed-value(P1) |
= |
"type="text/xsl" href="dm-example.xsl"" |
| dm:parent(P1) |
= |
([D1]) |
| |
| // Element node E1 |
| dm:base-uri(E1) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E1) |
= |
"element" |
| dm:node-name(E1) |
= |
xs:QName("http://www.example.com/catalog", "catalog") |
| dm:string-value(E1) |
= |
" Staind: Been Awhile Tee Black (1-sided) \n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n 25.00
It's Been A While 10.99 Staind " |
| dm:typed-value(E1) |
= |
fn:error() |
| dm:type-name(E1) |
= |
anon:TYP000001 |
| dm:is-id(E1) |
= |
false |
| dm:is-idrefs(E1) |
= |
false |
| dm:parent(E1) |
= |
([D1]) |
| dm:children(E1) |
= |
([E2], [E7]) |
| dm:attributes(E1) |
= |
([A1], [A2], [A3]) |
| dm:namespace-nodes(E1) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E1) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Attribute node A1 |
| dm:node-kind(A1) |
= |
"attribute" |
| dm:node-name(A1) |
= |
xs:QName("http://www.w3.org/2001/XMLSchema-instance", "xsi:schemaLocation") |
| dm:string-value(A1) |
= |
"http://www.example.com/catalog dm-example.xsd" |
| dm:typed-value(A1) |
= |
(xs:anyURI("http://www.example.com/catalog"), xs:anyURI("catalog.xsd")) |
| dm:type-name(A1) |
= |
anon:TYP000002 |
| dm:is-id(A1) |
= |
false |
| dm:is-idrefs(A1) |
= |
false |
| dm:parent(A1) |
= |
([E1]) |
| |
| // Attribute node A2 |
| dm:node-kind(A2) |
= |
"attribute" |
| dm:node-name(A2) |
= |
xs:QName("http://www.w3.org/XML/1998/namespace", "xml:lang") |
| dm:string-value(A2) |
= |
"en" |
| dm:typed-value(A2) |
= |
"en" |
| dm:type-name(A2) |
= |
xs:NMTOKEN |
| dm:is-id(A2) |
= |
false |
| dm:is-idrefs(A2) |
= |
false |
| dm:parent(A2) |
= |
([E1]) |
| |
| // Attribute node A3 |
| dm:node-kind(A3) |
= |
"attribute" |
| dm:node-name(A3) |
= |
xs:QName("", "version") |
| dm:string-value(A3) |
= |
"0.1" |
| dm:typed-value(A3) |
= |
"0.1" |
| dm:type-name(A3) |
= |
xs:string |
| dm:is-id(A3) |
= |
false |
| dm:is-idrefs(A3) |
= |
false |
| dm:parent(A3) |
= |
([E1]) |
| |
| |
| // Element node E2 |
| dm:base-uri(E2) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E2) |
= |
"element" |
| dm:node-name(E2) |
= |
xs:QName("http://www.example.com/catalog", "tshirt") |
| dm:string-value(E2) |
= |
" Staind: Been Awhile Tee Black (1-sided) \n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n 25.00
" |
| dm:typed-value(E2) |
= |
fn:error() |
| dm:type-name(E2) |
= |
cat:tshirtType |
| dm:is-id(E2) |
= |
false |
| dm:is-idrefs(E2) |
= |
false |
| dm:parent(E2) |
= |
([E1]) |
| dm:children(E2) |
= |
([E3], [E4], [E6]) |
| dm:attributes(E2) |
= |
([A4], [A5], [A6], [A7]) |
| dm:namespace-nodes(E2) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E2) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Attribute node A4 |
| dm:node-kind(A4) |
= |
"attribute" |
| dm:node-name(A4) |
= |
xs:QName("", "code") |
| dm:string-value(A4) |
= |
"T1534017" |
| dm:typed-value(A4) |
= |
xs:ID("T1534017") |
| dm:type-name(A4) |
= |
xs:ID |
| dm:is-id(A4) |
= |
true |
| dm:is-idrefs(A4) |
= |
false |
| dm:parent(A4) |
= |
([E2]) |
| |
| // Attribute node A5 |
| dm:node-kind(A5) |
= |
"attribute" |
| dm:node-name(A5) |
= |
xs:QName("", "label") |
| dm:string-value(A5) |
= |
"Staind : Been Awhile" |
| dm:typed-value(A5) |
= |
xs:token("Staind : Been Awhile") |
| dm:type-name(A5) |
= |
xs:token |
| dm:is-id(A5) |
= |
false |
| dm:is-idrefs(A5) |
= |
false |
| dm:parent(A5) |
= |
([E2]) |
| |
| // Attribute node A6 |
| dm:node-kind(A6) |
= |
"attribute" |
| dm:node-name(A6) |
= |
xs:QName("http://www.w3.org/1999/xlink", "xlink:href") |
| dm:string-value(A6) |
= |
"http://example.com/0,,1655091,00.html" |
| dm:typed-value(A6) |
= |
xs:anyURI("http://example.com/0,,1655091,00.html") |
| dm:type-name(A6) |
= |
xs:anyURI |
| dm:is-id(A6) |
= |
false |
| dm:is-idrefs(A6) |
= |
false |
| dm:parent(A6) |
= |
([E2]) |
| |
| // Attribute node A7 |
| dm:node-kind(A7) |
= |
"attribute" |
| dm:node-name(A7) |
= |
xs:QName("", "sizes") |
| dm:string-value(A7) |
= |
"M L XL" |
| dm:typed-value(A7) |
= |
(xs:token("M"), xs:token("L"), xs:token("XL")) |
| dm:type-name(A7) |
= |
cat:sizeList |
| dm:is-id(A7) |
= |
false |
| dm:is-idrefs(A7) |
= |
false |
| dm:parent(A7) |
= |
([E2]) |
| |
| // Element node E3 |
| dm:base-uri(E3) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E3) |
= |
"element" |
| dm:node-name(E3) |
= |
xs:QName("http://www.example.com/catalog", "title") |
| dm:string-value(E3) |
= |
"Staind: Been Awhile Tee Black (1-sided)" |
| dm:typed-value(E3) |
= |
xs:token("Staind: Been Awhile Tee Black (1-sided)") |
| dm:type-name(E3) |
= |
xs:token |
| dm:is-id(E3) |
= |
false |
| dm:is-idrefs(E3) |
= |
false |
| dm:parent(E3) |
= |
([E2]) |
| dm:children(E3) |
= |
() |
| dm:attributes(E3) |
= |
() |
| dm:namespace-nodes(E3) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E3) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Text node T1 |
| dm:base-uri(T1) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T1) |
= |
"text" |
| dm:string-value(T1) |
= |
"Staind: Been Awhile Tee Black (1-sided)" |
| dm:typed-value(T1) |
= |
xdt:untypedAtomic("Staind: Been Awhile Tee Black (1-sided)") |
| dm:type-name(T1) |
= |
xdt:untypedAtomic |
| dm:parent(T1) |
= |
([E3]) |
| |
| // Element node E4 |
| dm:base-uri(E4) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E4) |
= |
"element" |
| dm:node-name(E4) |
= |
xs:QName("http://www.example.com/catalog", "description") |
| dm:string-value(E4) |
= |
"\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n " |
| dm:typed-value(E4) |
= |
xdt:untypedAtomic("\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n ") |
| dm:type-name(E4) |
= |
cat:description |
| dm:is-id(E4) |
= |
false |
| dm:is-idrefs(E4) |
= |
false |
| dm:parent(E4) |
= |
([E2]) |
| dm:children(E4) |
= |
([E5]) |
| dm:attributes(E4) |
= |
() |
| dm:namespace-nodes(E4) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E4) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Element node E5 |
| dm:base-uri(E5) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E5) |
= |
"element" |
| dm:node-name(E5) |
= |
xs:QName("http://www.w3.org/1999/xhtml", "html:p") |
| dm:string-value(E5) |
= |
"\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n " |
| dm:typed-value(E5) |
= |
xdt:untypedAtomic("\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n ") |
| dm:type-name(E5) |
= |
xs:anyType |
| dm:is-id(E5) |
= |
false |
| dm:is-idrefs(E5) |
= |
false |
| dm:parent(E5) |
= |
([E4]) |
| dm:children(E5) |
= |
() |
| dm:attributes(E5) |
= |
() |
| dm:namespace-nodes(E5) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E5) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Text node T2 |
| dm:base-uri(T2) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T2) |
= |
"text" |
| dm:string-value(T2) |
= |
"\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n " |
| dm:typed-value(T2) |
= |
xdt:untypedAtomic("\n Lyrics from the hit song 'It's Been Awhile'\n are shown in white, beneath the large\n 'Flock & Weld' Staind logo.\n ") |
| dm:type-name(T2) |
= |
xdt:untypedAtomic |
| dm:parent(T2) |
= |
([E5]) |
| |
| // Element node E6 |
| dm:base-uri(E6) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E6) |
= |
"element" |
| dm:node-name(E6) |
= |
xs:QName("http://www.example.com/catalog", "price") |
| dm:string-value(E6) |
= |
"25.00" |
| // The typed-value is based on the content type of the complex type for the element |
| dm:typed-value(E6) |
= |
cat:monetaryAmount(25.0) |
| dm:type-name(E6) |
= |
cat:price |
| dm:is-id(E6) |
= |
false |
| dm:is-idrefs(E6) |
= |
false |
| dm:parent(E6) |
= |
([E2]) |
| dm:children(E6) |
= |
() |
| dm:attributes(E6) |
= |
() |
| dm:namespace-nodes(E6) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E6) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Text node T3 |
| dm:base-uri(T3) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T3) |
= |
"text" |
| dm:string-value(T3) |
= |
"25.00" |
| dm:typed-value(T3) |
= |
xdt:untypedAtomic("25.00") |
| dm:type-name(T3) |
= |
xdt:untypedAtomic |
| dm:parent(T3) |
= |
([E6]) |
| |
| // Element node E7 |
| dm:base-uri(E7) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E7) |
= |
"element" |
| dm:node-name(E7) |
= |
xs:QName("http://www.example.com/catalog", "album") |
| dm:string-value(E7) |
= |
" It's Been A While 10.99 Staind " |
| dm:typed-value(E7) |
= |
fn:error() |
| dm:type-name(E7) |
= |
cat:albumType |
| dm:is-id(E7) |
= |
false |
| dm:is-idrefs(E7) |
= |
false |
| dm:parent(E7) |
= |
([E1]) |
| dm:children(E7) |
= |
([E8], [E9], [E10], [E11]) |
| dm:attributes(E7) |
= |
([A8], [A9], [A10]) |
| dm:namespace-nodes(E7) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E7) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Attribute node A8 |
| dm:node-kind(A8) |
= |
"attribute" |
| dm:node-name(A8) |
= |
xs:QName("", "code") |
| dm:string-value(A8) |
= |
"A1481344" |
| dm:typed-value(A8) |
= |
xs:ID("A1481344") |
| dm:type-name(A8) |
= |
xs:ID |
| dm:is-id(A8) |
= |
true |
| dm:is-idrefs(A8) |
= |
false |
| dm:parent(A8) |
= |
([E7]) |
| |
| // Attribute node A9 |
| dm:node-kind(A9) |
= |
"attribute" |
| dm:node-name(A9) |
= |
xs:QName("", "label") |
| dm:string-value(A9) |
= |
"Staind : Its Been A While" |
| dm:typed-value(A9) |
= |
xs:token("Staind : Its Been A While") |
| dm:type-name(A9) |
= |
xs:token |
| dm:is-id(A9) |
= |
false |
| dm:is-idrefs(A9) |
= |
false |
| dm:parent(A9) |
= |
([E7]) |
| |
| // Attribute node A10 |
| dm:node-kind(A10) |
= |
"attribute" |
| dm:node-name(A10) |
= |
xs:QName("", "formats") |
| dm:string-value(A10) |
= |
"CD" |
| dm:typed-value(A10) |
= |
cat:formatType("CD") |
| dm:type-name(A10) |
= |
cat:formatType |
| dm:is-id(A10) |
= |
false |
| dm:is-idrefs(A10) |
= |
false |
| dm:parent(A10) |
= |
([E7]) |
| |
| // Element node E8 |
| dm:base-uri(E8) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E8) |
= |
"element" |
| dm:node-name(E8) |
= |
xs:QName("http://www.example.com/catalog", "title") |
| dm:string-value(E8) |
= |
"It's Been A While" |
| dm:typed-value(E8) |
= |
xs:token("It's Been A While") |
| dm:type-name(E8) |
= |
xs:token |
| dm:is-id(E8) |
= |
false |
| dm:is-idrefs(E8) |
= |
false |
| dm:parent(E8) |
= |
([E7]) |
| dm:children(E8) |
= |
() |
| dm:attributes(E8) |
= |
() |
| dm:namespace-nodes(E8) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E8) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Text node T4 |
| dm:base-uri(T4) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T4) |
= |
"text" |
| dm:string-value(T4) |
= |
"It's Been A While" |
| dm:typed-value(T4) |
= |
xdt:untypedAtomic("It's Been A While") |
| dm:type-name(T4) |
= |
xdt:untypedAtomic |
| dm:parent(T4) |
= |
([E8]) |
| |
| // Element node E9 |
| dm:base-uri(E9) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E9) |
= |
"element" |
| dm:node-name(E9) |
= |
xs:QName("http://www.example.com/catalog", "description") |
| dm:string-value(E9) |
= |
"" |
| // xsi:nil is true so the typed value is the empty sequence |
| dm:typed-value(E9) |
= |
() |
| dm:type-name(E9) |
= |
cat:description |
| dm:is-id(E9) |
= |
false |
| dm:is-idrefs(E9) |
= |
false |
| dm:parent(E9) |
= |
([E7]) |
| dm:children(E9) |
= |
() |
| dm:attributes(E9) |
= |
([A11]) |
| dm:namespace-nodes(E9) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E9) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Attribute node A11 |
| dm:node-kind(A11) |
= |
"attribute" |
| dm:node-name(A11) |
= |
xs:QName("http://www.w3.org/2001/XMLSchema-instance", "xsi:nil") |
| dm:string-value(A11) |
= |
"true" |
| dm:typed-value(A11) |
= |
xs:boolean("true") |
| dm:type-name(A11) |
= |
xs:boolean |
| dm:is-id(A11) |
= |
false |
| dm:is-idrefs(A11) |
= |
false |
| dm:parent(A11) |
= |
([E9]) |
| |
| // Element node E10 |
| dm:base-uri(E10) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E10) |
= |
"element" |
| dm:node-name(E10) |
= |
xs:QName("http://www.example.com/catalog", "price") |
| dm:string-value(E10) |
= |
"10.99" |
| dm:typed-value(E10) |
= |
cat:monetaryAmount(10.99) |
| dm:type-name(E10) |
= |
cat:price |
| dm:is-id(E10) |
= |
false |
| dm:is-idrefs(E10) |
= |
false |
| dm:parent(E10) |
= |
([E7]) |
| dm:children(E10) |
= |
() |
| dm:attributes(E10) |
= |
([A12]) |
| dm:namespace-nodes(E10) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E10) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Attribute node A12 |
| dm:node-kind(A12) |
= |
"attribute" |
| dm:node-name(A12) |
= |
xs:QName("", "currency") |
| dm:string-value(A12) |
= |
"USD" |
| dm:typed-value(A12) |
= |
cat:currencyType("USD") |
| dm:type-name(A12) |
= |
cat:currencyType |
| dm:is-id(A12) |
= |
false |
| dm:is-idrefs(A12) |
= |
false |
| dm:parent(A12) |
= |
([E10]) |
| |
| // Text node T5 |
| dm:base-uri(T5) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T5) |
= |
"text" |
| dm:string-value(T5) |
= |
"10.99" |
| dm:typed-value(T5) |
= |
xdt:untypedAtomic("10.99") |
| dm:type-name(T5) |
= |
xdt:untypedAtomic |
| dm:parent(T5) |
= |
([E10]) |
| |
| // Element node E11 |
| dm:base-uri(E11) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(E11) |
= |
"element" |
| dm:node-name(E11) |
= |
xs:QName("http://www.example.com/catalog", "artist") |
| dm:string-value(E11) |
= |
" Staind " |
| dm:typed-value(E11) |
= |
" Staind " |
| dm:type-name(E11) |
= |
xs:string |
| dm:is-id(E11) |
= |
false |
| dm:is-idrefs(E11) |
= |
false |
| dm:parent(E11) |
= |
([E7]) |
| dm:children(E11) |
= |
() |
| dm:attributes(E11) |
= |
() |
| dm:namespace-nodes(E11) |
= |
([N1], [N2], [N3], [N4], [N5]) |
| dm:namespace-bindings(E11) |
= |
("xml", "http://www.w3.org/XML/1998/namespace", "", "http://www.example.com/catalog", "html", "http://www.w3.org/1999/xhtml", "xlink", "http://www.w3.org/1999/xlink", "xsi", "http://www.w3.org/2001/XMLSchema-instance") |
| |
| // Text node T6 |
| dm:base-uri(T6) |
= |
xs:anyURI("http://www.example.com/catalog.xml") |
| dm:node-kind(T6) |
= |
"text" |
| dm:string-value(T6) |
= |
" Staind " |
| dm:typed-value(T6) |
= |
xdt:untypedAtomic(" Staind ") |
| dm:type-name(T6) |
= |
xdt:untypedAtomic |
| dm:parent(T6) |
= |
([E11]) |
| |
{kind=link}
{kind=link}