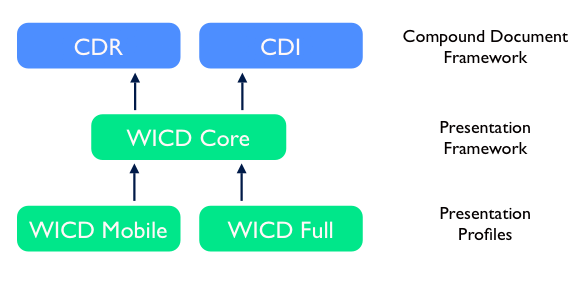
In a WICD document, the focusable items, i.e., items which can form part of
a focus traversal, are defined by the respective document types being
combined. For example, focusable items in an SVG document are defined by
the SVG 1.2 focusable attribute
[SVGMobile12, interact].
6.3.1 Two Dimensional Focus Navigation (Flat, Graphical, Joystick)
Vendors of handset devices that do not provide a pointing input device
are encouraged to implement
this model of a two dimensional, flat graphical focus navigation.
Mobile handset devices in general don't provide a pointing device.
On these type of devices, the joystick must replace mouse or stylus,
cursor keys, tab keys and page up/down keys.
The benefits of the flat graphical focus navigation
come into effect, when a web document needs to be operated
with a joystick device.
In this model a union of all focusable objects within
each component of a compound document is presented as a so-called flattened set. All
focusable objects in a compound document act equivalently and are used without any
dependency based on which component document they were defined in.
Therefore, all focusable objects in child documents are used in the same way as
focusable objects in a parent document.
Two dimensional, graphical focus navigation is not based on the concept
of a linear focus ring. The traversal order is not related to the position
of a focusable object in the source document.
The graphical foucs navigation always needs to consider
the current state of the rendered document.
For example, scripts and animations may change the
document's presentation at any time.
Therefore, any focus navigation action is calculated at the moment,
when the user interacts with the document.
The following examples show specific navigation issues with WICD documents.
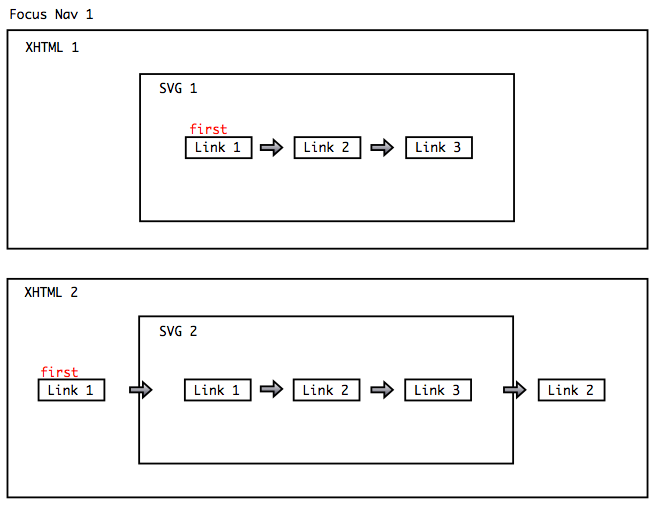
Example 1: The images below show two similar WICD documents.
The 1st image shows a WICD document with a parent document, that
does not have any focusable objects. The first focusable object is located
inside the SVG child document.
The 2nd image shows focusable objects in both parent and child. The
positioning of the focusable objects requires focus traversal to go
through the child document.
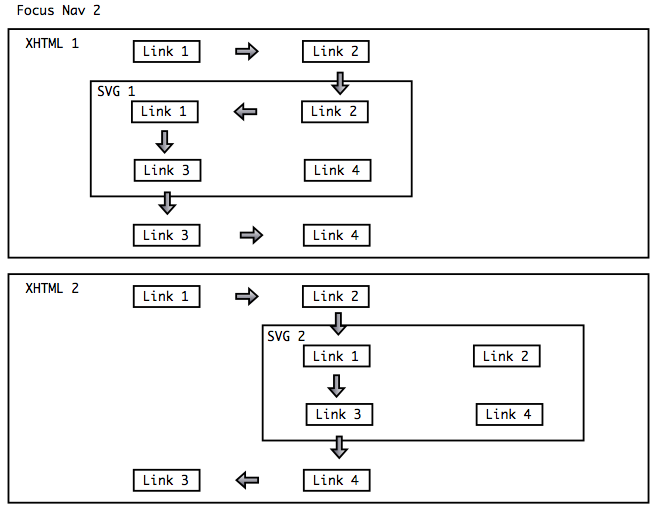
Example 2: The image below shows again two WICD documents.
The focusable objects in both documents are identical.
But the rendered location of the child document differs in both examples.
This results in highly different focus traversal. The arrows in both
images show just one of many ways a user can navigate through these
WICD documents.
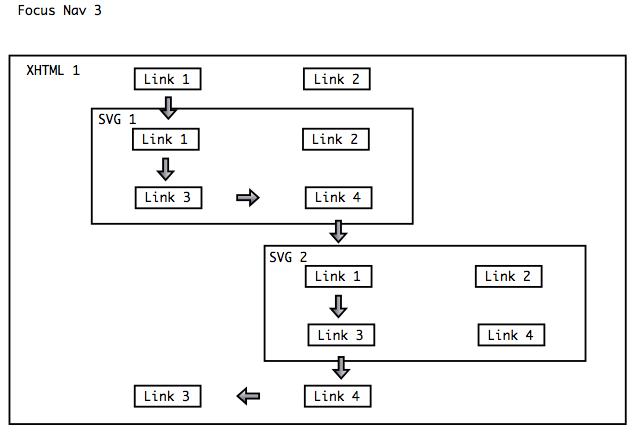
Example 3: The image below shows one WICD document with
two child documents. The issue here is, that Link-4 of SVG-1
is positioned just above Link-1 of SVG-2.
Ideally, the agent will allow the user to navigate directly
from one child object to the next.
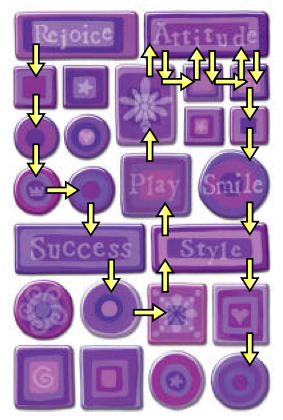
The main idea of the flat graphical focus navigation is the concept
of an invisible 'current focus point' inside the page and inside the currently focused
object.
This 'current focus point' can be visualized to indicate the position inside
the currently focused object (using a UI component such as a
pointer or some other type of icon).
It can also be presented by highlighting visual objects around
the current focus point. The current focus point is used as a
starting location for calculating a distance function towards
the other focusable objects when navigating.
When user navigates (e.g. presses navigation input controls), the
current focus point is moved and a different object receives focus.
The focus point movement depends on current movement direction and
available focusable content in that direction.
The concept of the invisible current focus point enables a very
natural navigation behavior between focusable objects of different size.
The arrows in the upper right in the following image show how
focus traversal always moves back from the 'Attitude' object to
the originating object.
The focus navigation algorithm consists of three phases: finding
candidates for focus movements, calculating and adjusting movement based on a distance function, and
moving the current focus point with possibly changing focusable object.
Phase 1. At first, focusable objects are searched from the direction
of navigation. The search includes content that is currently visible
in that direction and content that becomes visible if viewport changes.
Phase 2. At second, the current focus point is moved to the direction of
navigation. This movement may keep the point within the
current focusable object or it may move it out of the current
focusable object. Then, the current focus point movement is adjusted by distance
function. The distance function takes location of current focus
point, and locations and shapes of available focusable content in the area, and
calculates most suitable
location for the point movement. The distance function enables
selection of near focusable objects in cases where more unintuitive
selection would otherwise be made.
Phase 3. Finally, there is a check that
when focus point moves to another object, focused object is changed accordingly.
The distance function takes into account the following metrics:
- the Euclidian distance (dotDist) between the current focus point position and
its potential position in each of the candidates determined in phase 1. If the two positions have the same
coordinate on the axis
orthogonal to the navigation direction, we force dotDist to be 0 in order to favor elements in direction of
navigation.
- the absolute distance (dx or dy) on the navigation axis between the opposing edges of currently focused element and each of candidates determined in phase 1.
- the absolute distance (xdisplacement or ydisplacement) on the axis orthogonal to the navigation axis
between the opposing edges of currently focused element and each of candidates determined in phase 1.
When dx (dy) != 0, xdisplacement (ydisplacement) = 0. These values are used to compensate for the situations
where an element is close on the navigation axis, but very far on the orthogonal axis. In such a case, it is
more natural to navigate to another element, which may be further away on the navigation axis, but
approximately on the same level on the other axis.
- the overlap (Overlap) between the opposing edges of currently focused element and each of
candidates determined in phase 1. Elements are rewarded for having high overlap with the currently
focused element. To prevent the longer boxes always win focus over shorter boxes when longer boxes are partially
outside of viewport, the visible width has been set as an upper limit for the overlap.
The distance function (df) is:
df = dotDist + dx + dy + 2 * (xdisplacement + ydisplacement) - sqrt(Overlap)
6.3.2 One Dimensional Focus Navigation (Linear, Focus Ring, Tab)
Desktop agents, Tablet's and PDA's usually allow navigation of a Web document
using a pointing device (mouse or stylus).
On desktop agents, the tab-key can be used additionally, to navigate over
focusable objects. Here, all focusable objects of a single Web document are chained
in one linear path, based on the order of accurence in the source document.
This creates the so called focus navigation ring, where advancing over the last
focusable element brings the focus back to the first focusable element.
XHTML and SVG have methods for linear one dimensional focus traversal.
XHTML provides a default traversal order, and allows it to be
changed with the use of tabindex attribute within one XHTML
document. SVG's provides the focusNext and focusPrev
elements which may be used to provide similar functionality within
an SVG document. However, neither of these methods can be used
when XHTML and SVG are combined. Therefore in the case of a
WICD document by reference, combining XHTML with SVG, some
alternate form of navigation is required.
When navigating an XHTML document it is possible to assign so-called
access keys to links in order to provide a 'hot-key' navigation ability.
It is unclear how such access keys work in the case of a referenced
XHTML document containing access keys. Similarly if multiple parts of
a WICD document contained access keys, should the user agent
provide access key navigation into the child document or restrict it
to the parent document only.