B An Overview of Web Services Security Technologies (Non-Normative)
This section attempts to provide a non-exhaustive description
of current available work around Web services security relevant
to the requirements and solutions presented in 3.6 Web Services Security.
Note that although these technologies build on existing
security technologies, they are relatively new and need to be
fully tested in actual deployment scenarios.
B.1 XML-Signature and XML-Encryption
XML signatures are designed for use in XML transactions. It
is a standard that was jointly developed by W3C and the IETF
(RFC 2807, RFC 3275). The standard defines a schema for
capturing the result of a digital signature operation
applied to arbitrary data and its processing. XML signatures
add authentication, data integrity, and support for
non-repudiation to the signed data.
XML Signature has the ability to sign only specific
portions of the XML tree rather than the complete
document. This is important when a single XML document may
need to be signed by multiple times by a single or multiple
parties. This flexibility can ensure the integrity of
certain portions of an XML document, while leaving open the
possibility for other portions of the document to
change. Signature validation mandates that the data object
that was signed be accessible to the party that interested
in the transaction. The XML signature will generally
indicate the location of the original signed object.
XML Encryption specifies a process for encrypting data and
representing the result in XML. The data may be arbitrary data
(including an XML document), an XML element, or XML element
content. The result of encrypting data is an XML Encryption
element which contains or references the cipher data.
B.2 Web Services Security
Developed at OASIS, Web Services Security (WSS) defines a
SOAP extension providing quality of protection through
message integrity, message confidentiality, and message
authentication. WSS mechanisms can be used to
accommodate a wide variety of security models and
encryption technologies.
The work provides a general mechanism for associating
security tokens with messages. The specification does not
require a specific type of security token. It is
designed to support multiple security token
formats. WSS describes how to encode binary
security tokens. The specification describes how to encode
X.509 certificates and Kerberos tickets. Additionally, it
also describes how to include opaque encrypted keys.
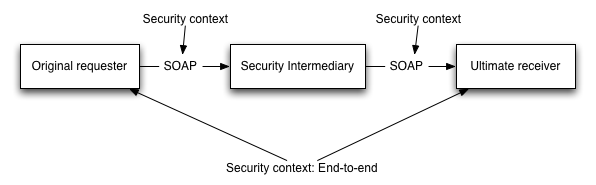
The WSS specification defines an end to end
security framework that provides support for intermediary
security processing. Message integrity is provided by
using XML Signature in conjunction with security tokens to
ensure that messages are transmitted without
modifications. The integrity mechanisms can support
multiple signatures, possibly by multiple actors. The
techniques are extensible such that they can support
additional signature formats. Message confidentiality is
granted by using XML Encryption in conjunction with
security tokens to keep portions of SOAP messages
confidential. The encryption mechanisms can support
operations by multiple actors.
B.3 XML Key Management Specification (XKMS) 2.0
XKMS 2.0 is an XML-based way of managing the Public Key
Infrastructure (PKI), a system that uses public-key
cryptography for encrypting, signing, authorizing and
verifying the authenticity of information in the
Internet. It specifies protocols for distributing and
registering public keys, suitable for use in conjunction
with the proposed standard for XML Signature and XML
Encryption.
XKMS allow implementers to outsource the task of key
registration and validation to a "trust"
utility. This simplify implementation since the actual work
of managing public and private key pairs and other PKI
details is done by third party.
An XKMS trust utility works with any PKI system, passing
the information back and forth between it and the Web
service. Since the trust utility does the work, the Web
service itself can be kept simple. XKMS is a W3C
specification.
B.4 Security Assertion Markup Language (SAML)
SAML is an Extensible Markup Language standard (XML) that
supports Single Sign On. SAML allows a user to log on once
to a Web site and conduct business with affiliated but
separate Web sites. SAML can be used in business-to-business
and business-to-consumer transactions.
There are threes basic SAML components: assertions,
protocol, and binding. Assertions can be one of three types:
authentication, attribute, and authorization. Authentication
assertion validates the identity of the user. The attribute
assertion contains specific information about the
user. While, the authorization assertion identifies what the
user is authorized to do.
The protocol defines how SAML request and receives
assertions. There are several available binding for
SAML. There are bindings that define how SAML message
exchanges are mapped to SOAP, HTTP, SMTP and FTP among
others. The Organization for the Advancement of Structured
Information Standards (OASIS) is the body developing
SAML.
B.5 XACML: Communicating Policy Information
XACML is an Extensible Markup Language standard (XML) based
technology, developed by Organization for the Advancement of
Structured Information Standards (OASIS) for writing access
control polices for disparate devices and applications.
XACML includes an access control language and
request/response language that let developers write
policies that determine what users can access on a network
or over the Web. XACML can be used to connect disparate
access control policy engines.
B.6 Identity Federation
The Liberty Alliance is defining specifications dealing with various
aspects of identity. Their phase 2 work is grouped into three
categories: ID-FF, ID-WSF, and ID-SIS.
ID-FF (Identity Federation Framework) discusses how businesses or
organizations can be affiliated into circles of trust and trust
relationships. ID-FF includes several normative specifications, which in
turn make normative references to SAML.
ID-WSF (Identity Web Services Framework) is a set of specifications for
creating, discovering, using, and updating various aspects of identities
through a particular type of web service known as an Identity
Service. ID-WSF builds on ID-FF. A user (Principal) may register with
several Identity Services. A prominent part of ID-WSF is a discovery
service for locating an Identity Service for a given user
(Principal). ID-SWF also defines a Data Services Template. ID-WSF has
also defined a draft specification for an approach to negotiating an
authentication method using SOAP messages to identify SASL mechanisms (RFC
2222).
Note that WS-Security specifically states that establishing a security
context or authentication mechanisms is outside its scope. ID-WSF may fill
this void. However, WS-Security also defines a Username Token Profile,
which could be used as an authentication mechanism. Potentially, Liberty
ID-WSF could be used to negotiate the use of WSS Username Token Profile as
the authentication mechanism. Currently, WSS Username Token Profile is not
registered in IANA's SASL Mechanisms collection.
ID-SIS (Identity Service Instance Specifications) defines profiles for
particular types of Identity Services. These profiles conform to the
ID-WSF Data Services Template. Liberty has defined two such profiles. The
Employee Profile (ID-SIS-EP) defines how to query and modify information
associated with a Principal in the context of their employer. The Personal
Profile (ID-SIS-PP) defines how to query and modify identity information
for Principals themselves.
D Acknowledgments (Non-Normative)
This document has been produced by the Web
Services Architecture Working Group
. The chairs of this Working Group were Chris Ferris (until July 2002), Michael Champion (starting July 2002) and Dave Hollander (starting July 2002). The chairs also wish to thank the following (listed in alphabetic order) for their substantial contributions to the final documents: Daniel Austin, Mark Baker, Abbie Barbir, David Booth, Martin Chapman, Ugo Corda, Roger Cutler, Paul Denning, Zulah Eckert, Chris Ferris, Hugo Haas, Hao He, Yin-Leng Husband, Mark Jones, Heather Kreger, Michael Mahan, Frank McCabe, Eric Newcomer, David Orchard, Katia Sycara.
Members of the Working Group are (at the time of writing, and in alphabetical order): Geoff Arnold (Sun Microsystems, Inc.), Mukund Balasubramanian (Infravio, Inc.), Mike Ballantyne (EDS), Abbie Barbir (Nortel Networks), David Booth (W3C), Mike Brumbelow (Apple), Doug Bunting (Sun Microsystems, Inc.), Greg Carpenter (Nokia), Tom Carroll (W. W. Grainger, Inc.), Alex Cheng (Ipedo), Michael Champion (Software AG), Martin Chapman (Oracle Corporation), Ugo Corda (SeeBeyond Technology Corporation), Roger Cutler (ChevronTexaco), Jonathan Dale (Fujitsu), Suresh Damodaran (Sterling Commerce(SBC)), James Davenport (MITRE Corporation), Paul Denning (MITRE Corporation), Gerald Edgar (The Boeing Company), Shishir Garg (France Telecom), Hugo Haas (W3C), Hao He (The Thomson Corporation), Dave Hollander (Contivo), Yin-Leng Husband (Hewlett-Packard Company), Mario Jeckle (DaimlerChrysler Research and Technology), Heather Kreger (IBM), Sandeep Kumar (Cisco Systems Inc), Hal Lockhart (OASIS), Michael Mahan (Nokia), Francis McCabe (Fujitsu), Michael Mealling (VeriSign, Inc.), Jeff Mischkinsky (Oracle Corporation), Eric Newcomer (IONA), Mark Nottingham (BEA Systems), David Orchard (BEA Systems), Bijan Parsia (MIND Lab), Adinarayana Sakala (IONA), Waqar Sadiq (EDS), Igor Sedukhin (Computer Associates), Hans-Peter Steiert (DaimlerChrysler Research and Technology), Katia Sycara (Carnegie Mellon University), Bryan Thompson (Hicks & Associates, Inc.), Sinisa Zimek (SAP).
Previous members of the Working Group were: Assaf Arkin (Intalio, Inc.), Daniel Austin (W. W. Grainger, Inc.), Mark Baker (Idokorro Mobile, Inc. / Planetfred, Inc.), Tom Bradford (XQRL, Inc.), Allen Brown (Microsoft Corporation), Dipto Chakravarty (Artesia Technologies), Jun Chen (MartSoft Corp.), Alan Davies (SeeBeyond Technology Corporation), Glen Daniels (Macromedia), Ayse Dilber (AT&T), Zulah Eckert (Hewlett-Packard Company), Colleen Evans (Sonic Software), Chris Ferris (IBM), Daniela Florescu (XQRL Inc.), Sharad Garg (Intel), Mark Hapner (Sun Microsystems, Inc.), Joseph Hui (Exodus/Digital Island), Michael Hui (Computer Associates), Nigel Hutchison (Software AG), Marcel Jemio (DISA), Mark Jones (AT&T), Timothy Jones (CrossWeave, Inc.), Tom Jordahl (Macromedia), Jim Knutson (IBM), Steve Lind (AT&T), Mark Little (Arjuna), Bob Lojek (Intalio, Inc.), Anne Thomas Manes (Systinet), Jens Meinkoehn (T-Nova Deutsche Telekom Innovationsgesellschaft), Nilo Mitra (Ericsson), Don Mullen (TIBCO Software, Inc.), Himagiri Mukkamala (Sybase, Inc.), Joel Munter (Intel), Henrik Frystyk Nielsen (Microsoft Corporation), Duane Nickull (XML Global Technologies), David Noor (Rogue Wave Software), Srinivas Pandrangi (Ipedo), Kevin Perkins (Compaq), Mark Potts (Talking Blocks, Inc.), Fabio Riccardi (XQRL, Inc.), Don Robertson (Documentum), Darran Rolls (Waveset Technologies, Inc.), Krishna Sankar (Cisco Systems Inc), Jim Shur (Rogue Wave Software), Patrick Thompson (Rogue Wave Software), Steve Vinoski (IONA), Scott Vorthmann (TIBCO Software, Inc.), Jim Webber (Arjuna), Prasad Yendluri (webMethods, Inc.), Jin Yu (MartSoft Corp.) .
The people who have contributed to discussions on the www-ws-arch
public mailing list are also gratefully acknowledged.