This specification defines the XML-binary Optimized Packaging (XOP)
convention, a means of more efficiently serializing XML Infosets (see
[XML InfoSet]) that have certain types of content.
A XOP package is created by placing a serialization of the XML Infoset
inside of an extensible packaging format (such a MIME
Multipart/Related, see [RFC 2387]). Then, selected
portions of its content that are base64-encoded binary data are
re-encoded (i.e., the data is decoded from base64) and placed into the
package. The locations of those selected portions are marked in the XML
with a special element that links to the packaged data using URIs.
In a number of important XOP applications, binary data need never be
encoded in base64 form. If the data to be included is already available
as a binary octet stream, then either an application or other software
acting on its behalf can directly copy that data into a XOP package, at
the same time preparing suitable linking elements for use in the root
part; when parsing a XOP package, the binary data can be made available
directly to applications, or, if appropriate, the base64 binary
character representation can be computed from the binary data.
However, at the conceptual level, this binary data can be thought of as
being base64-encoded in the XML Document. As this conceptual form might
be needed during some processing of the XML Document (e.g., for signing
the XML document), it is necessary to have a one to one correspondence
between XML Infosets and XOP Packages. Therefore, the conceptual
representation of such binary data is as if it were base64-encoded,
using the canonical lexical form of XML Schema base64Binary
datatype (see [XML Schema Part 2] 3.2.16
base64Binary). In the reverse direction, XOP is capable of
optimizing only base64-encoded Infoset data that is in the canonical
lexical form.
Only element content can be optimized; attributes,
non-base64-compatible character data, and data not in the canonical
representation of the base64Binary datatype cannot be
successfully optimized by XOP.
The remainder of this specification is organized in the following
fashion:
Section 2 describes the XOP Infoset, which preserves the
non-optimized content and structure of the original XML Infoset.
Section 3 specifies the XOP processing model.
Section 4 of this specification describes the form of the XOP
Package.
Section 5 describes how XOP Documents are identified.
Section 6 explores the security considerations of using the XOP
convention.
This specification uses terminology from the XML Infoset (see [XML InfoSet]) when discussing XML content and structure. This
is only a convention for clear specification of XOP behavior.
The following terms are used in this specification:
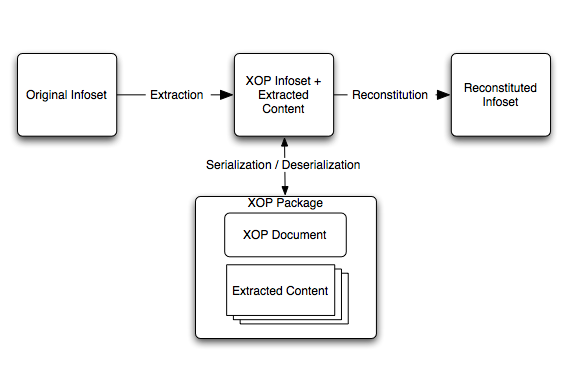
- Original XML Infoset - An XML Infoset to be optimized.
- Optimized Content - Content which has been removed from
the XML Infoset.
- XOP Infoset - The Original Infoset with
any Optimized Content removed and replaced by
xop:Includeelement information items.
- XOP Document - A serialization of the XOP Infoset using
any W3C recommendation-level version of XML.
- XOP Package - A package containing the XOP
Document and any Optimized Content. As a whole, the XOP Package
is an alternate serialization of the Original Infoset.
- Reconstituted XML Infoset - An XML Infoset that has been
constructed from the parts of a XOP Package.
Example shows an XML Infoset prior to XOP
processing. Example shows the same
Infoset, serialized using the XOP format in a MIME Multipart/Related
package. The base64-encoded content of the m:photo and
m:sig elements have been replaced by a
xop:Include element, while
the binary octets have been serialized in separate MIME parts. Note
that those examples use [Assigning Media Types to Binary Data in XML] to identify the
media type of the content of the m:photo and
m:sig elements.
Example shows an XML Infoset prior to XOP
processing. Example shows the same
Infoset, serialized using the XOP format in a MIME Multipart/Related
package. The base64-encoded content of the m:photo and
m:sig elements have been replaced by a
xop:Include element, while
the binary octets have been serialized in separate MIME parts.
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT",
"SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this
document are to be interpreted as described in RFC 2119 [RFC 2119].
This specification uses a number of namespace prefixes throughout;
they are listed below. Note that the choice of any namespace prefix
is arbitrary and not semantically significant.
Prefixes and Namespaces used in this
specification.| Prefix | Namespace |
|---|
| Notes |
|---|
| xop | "http://www.w3.org/2004/08/xop/include" |
|
A non-normative XML Schema [XML Schema Part 1], [XML Schema Part 2] document for the
"http://www.w3.org/2004/08/xop/include"
namespace can be found at http://www.w3.org/2004/08/xop/include. Note that XML Schema
> currently provides only for validation of XML 1.0 Infosets; accordingly,
> the schema may not be usable
> with XOP Infosets corresponding to later versions of XML.
|
| xmlmime | "http://www.w3.org/2004/06/xmlmime" |
|
The namespace for the content type attribute.
|
| xs | "http://www.w3.org/2001/XMLSchema" |
|
The namespace of XML Schema data types [XML Schema Part 2].
|
| Editorial note: HR | |
| Note that the "http://www.w3.org/2004/06/xmlmime"
URI is not final and will be changed.
|
This section describes the processing model for creating XOP Packages
and interpreting XOP Packages. Unless otherwise stated, the result of
such processing MUST be semantically equivalent to performing the
specified steps separately, and in the order given.
To create a XOP Package from an Original XML Infoset:
-
Ensure that the Original XML Infoset contains no element
information item with a [namespace name] of
"http://www.w3.org/2004/08/xop/include" and a [local
name] of
Include. As discussed in 2 XOP Infoset Constructs, XML Infosets with such element
information items cannot be represented using XOP.
-
Create an empty package.
-
Identify within the Original XML Infoset the element
information items to be optimized. To be optimized, the
characters comprising the [children] of the element
information item MUST be in the canonical form of
xs:base64Binary (see [XML Schema Part 2]3.2.16
base64Binary) and MUST NOT contain any whitespace
characters, preceding, inline with or following the non-whitespace
content.
-
Create a XOP Infoset which is a copy of the Original XML Infoset,
but with the [children] of each element
information item
identified in the previous step replaced by a
xop:Includeelement
information item (see 2.1 xop:Include element information item) constructed as follows:
-
Transform the replaced characters into binary data by
processing them as base64-encoded data.
-
Serialize the binary data into a new part of the package, with
appropriate metadata corresponding to the [normalized value] of
the
hrefattribute information item of
the xop:Includeelement information
item (see 2.2 href attribute information item).
-
If the element information item being optimized
(i.e., the [parent] of the newly inserted
xop:Includeelement information item)
has a xmlmime:contentTypeattribute
information item, its value SHOULD be reflected
appropriately in the metadata for the part.
-
Serialize the resulting XOP Infoset into the package using any W3C
recommendation-level version of XML (e.g., [XML 1.0],
[XML 1.1]) and identify it as the root part according
to the packaging mechanism's convention, labeling it with the
application/xop+xml media type, as described in 5 Identifying XOP Documents.
Additional parts MAY be added to the package to satisfy application
specific requirements. Other content-specific metadata MAY be
reflected in the packaging metadata as appropriate.
If content cannot be successfully encoded into the XOP package,
implementations SHOULD behave as if that portion of the Original XML
Infoset was not nominated for optimization.
This section specifies the means by which the Original XML Infoset
can be reconstructed from a XOP Package that has been prepared
according to the rules of 3.1 Creating XOP Packages.
Note: conventions or error reporting mechanisms to be used in
processing packages that incorrectly purport to be XOP Packages are
beyond the scope of this specification.
To create a Reconstituted XML Infoset from a XOP Package:
-
Construct an XML Infoset by parsing the root part of the package as
an XML document. The document MUST be parsed according to the level
of the XML Recommendation identified by the XML declaration of that
document. If no XML declaration is present, then the document MUST
be parsed per [XML 1.0].
-
Using that XML Infoset, for each element information
item, E, which has, as the sole member of its [children] property, a
xop:Includeelement information item (as defined in 2.1 xop:Include element information item):
-
Locate the part of the package corresponding to the URI in the
hrefattribute information item of
the xop:Includeelement information item (i.e., corresponding to the URI
encoded in the attribute information item's
[normalized value]).
-
Replace the
xop:Includeelement information item that appears in the
[children] property of E with character information items representing
the canonical base64 encoding of the entity body of the
identified package part (i.e., effectively replace the
xop:Includeelement information item
with the data reconstructed from the
package part).
XOP is capable of using a variety of underlying packaging mechanisms.
Such packaging mechanisms MUST be able to represent, with full fidelity
all the parts created according to 3 XOP Processing Model (see 3.1 Creating XOP Packages), and MUST be used in a manner that provides a
means of designating a distinguished root (main, primary etc.) part.
The subsection below specifies normatively how a particular packaging
mechanism, MIME Multipart/Related, is used, but does not preclude the
use of other packaging mechanisms with the XOP convention.
This section describes how MIME Multipart/Related packaging (as
specified in [RFC 2387]) is used with XOP.
The root MIME part is the root part of the XOP package, MUST be a
serialization of the XOP Infoset using any W3C recommendation-level
version of XML (e.g., [XML 1.0], [XML 1.1]), and
MUST be identified with a media type of "application/xop+xml" (as defined below).
The "start-info" parameter of the package's media type MUST contain the content type
associated with the content's XML serialization. (i.e. it will contain the same
value as the "type" parameter of the root part).
Except for purposes of determining the root MIME part, as specified
by [RFC 2387], ordering of MIME parts MUST NOT be
considered significant to XOP processing or to the construction of
the XOP Infoset.
Part metadata is reflected in MIME header fields. Specifically,
the URI used in the value of an href attribute
information item on a xop:Include element
information item contains a URI that uses the 'cid:' scheme
(see [RFC 2392]), so the corresponding MIME
part MUST have a Content-ID header field (see [RFC 2387]
with a corresponding field-value.
Furthermore, if a xmlmime:contentType attribute
information item is found (as described in 3 XOP Processing Model), it SHOULD be reflected in the field value
of the MIME Content-Type header.
This appendix summarizes the XOP dependencies upon underlying
specifications, the nature of appropriate payloads for XOP and the
means of extending XOP.
The XOP convention builds upon a number of underlying specifications.
They are:
XML (e.g., [XML 1.0], [XML 1.1]) - The XOP
Document is encoded using any W3C recommendation-level version of
XML (see 3.1 Creating XOP Packages). Formats that
use XOP MUST identify which versions of XML are permissible for
encoding the XOP Infoset. XOP does not constrain the use of any
mechanisms defined by XML, including those explicitly allowing
extensions, nor does it constrain the use of underlying
specifications.
Namespaces in XML (e.g., [Namespaces in XML], [Namespaces in XML 1.1]) - The XOP Document uses any W3C
recommendation-level version of Namespaces in XML compatible with
the version(s) of XML used. Formats that use XOP MUST identify
which versions of Namespaces in XML are permissible for encoding
the XOP Infoset. XOP does not constrain the use of any mechanisms
defined by Namespaces in XML, including those explicitly
allowing extensions, nor does it constrain the use of underlying
specifications.
Uniform Resource Identifiers (see [RFC 2396]) - The
XOP Document uses URIs to locate parts in the XOP Package (see
2.2 href attribute information item. XOP does not constrain the use of any
mechanisms defined by URIs, including those explicitly allowing
extensions, nor does it constrain the use of underlying
specifications.
Packaging Mechanism - XOP requires the use of a packaging
mechanism that satisfies the requirements in 4 XOP Packages. One such mechanism MUST be in use, but
XOP does not require a specific mechanism. Formats using XOP MUST
identify at least one such mechanism permissible for creating the
XOP Package, and MUST specify how each allowed mechanism is to
be used for building the XOP Package.
The relationship of one such mechanism to XOP, The MIME
Multipart/Related Content-type, is specified in 4.1 MIME Multipart/Related XOP Packages.
- XML 1.0
- W3C
Recommendation "Extensible Markup Language (XML) 1.0 (Third
Edition)", Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler,
François Yergeau, 4 February 2004. (See http://www.w3.org/TR/2004/REC-xml-20040204.)
- XML 1.1
- W3C
Recommendation "Extensible Markup Language (XML) 1.1", Tim Bray,
Jean Paoli, C. M. Sperberg-McQueen, Eve Maler, François Yergeay,
John Cowan, 15 Apris 2004. (See http://www.w3.org/TR/2004/REC-xml11-20040204/.)
- MTOM
- W3C
Working Draft "SOAP Message Transmission Optimization Mechanism", N.
Mendelsohn, M. Nottingham, H. Ruellan, August 2004. (See http://www.w3.org/TR/2004/CR-soap12-mtom-20040826/.)
- SOAP Representation Header
- W3C
Working Draft "SOAP Resource Representation Header", A. Karmarkar, M.
Gudgin, Y. Lafon, August 2004. (See http://www.w3.org/TR/2004/CR-soap12-rep-20040826/.)
- SOAP Optimized Serialization Use Cases and Requirements
- W3C Working Draft
"SOAP Optimized Serialization Use Cases and Requirements", M. A. Jones, Tony Graham, Anish Karmarkar, June 2004. (See http://www.w3.org/TR/2004/WD-soap12-os-ucr-20040608/.)
- Namespaces in XML
- W3C Recommendation "Namespaces in XML", Tim Bray, Dave
Hollander, Andrew Layman, 14 January 1999. (See http://www.w3.org/TR/1999/REC-xml-names-19990114/.)
- Namespaces in XML 1.1
- W3C Recommendation "Namespaces in XML 1.1", Tim Bray,
Dave Hollander, Andrew Layman, Richard Tobin, 4 Frebruary
2004. (See http://www.w3.org/TR/2004/REC-xml-names11-20040204.)
- XML InfoSet
- W3C
Recommendation "XML Information Set", John Cowan, Richard Tobin, 24
October 2001. (See http://www.w3.org/TR/2001/REC-xml-infoset-20011024/.)
- XML Schema Part 1
- W3C
Proposed Edited Recommendation "XML Schema Part 1: Structures
Second Edition", Henry S. Thompson, David Beech, Murray Maloney,
Noah Mendelsohn, 18 March 2004. (See http://www.w3.org/TR/2004/PER-xmlschema-1-20040318/.)
- XML Schema Part 2
- W3C
Proposed Edited Recommendation "XML Schema Part 2: Datatypes Second
Edition", Paul V. Biron, Ashok Malhotra, 18 March 2004. (See http://www.w3.org/TR/2004/PER-xmlschema-2-20040318/.)
- Assigning Media Types to Binary Data in XML
-
W3C Working Draft "Assigning Media Types to Binary Data in XML", Anish Karmarkar, Ümit Yalçınalp, June 2004.
(See http://www.w3.org/TR/2004/WD-xml-media-types-20040608.)
- RFC 2119
- IETF "RFC
2119: Keywords for use in RFCs to Indicate Requirement Levels", S.
Bradner, March 1997. (See http://www.ietf.org/rfc/rfc2119.txt.)
- RFC 2387
- IETF "The
MIME Multipart/Related Content-type", E. Levinson, August
1998. (See http://www.ietf.org/rfc/rfc2387.txt.)
- RFC 2557
- IETF "MIME
Encapsulation of Aggregate Documents, such as HTML (MHTML)", J.
Palme, A. Hopmann, N. Shelness, March 1999. (See http://www.ietf.org/rfc/rfc2557.txt.)
- RFC 2392
- IETF
"Content-ID and Message-ID Uniform Resource Locators", E. Levinson,
August 1998. (See http://www.ietf.org/rfc/rfc1873.txt.)
- RFC 2396
- Uniform
Resource Identifiers (URI): Generic Syntax, T. Berners-Lee, R.
Fielding, U.C. Irvine, L. Masinter, August 1998. (See http://www.ietf.org/rfc/rfc2396.txt.)
- RFC 2732
- Format
for Literal IPv6 Addresses in URL's, R. Hinden, B. Carpenter,
L. Masinter, December 1999 (See http://www.ietf.org/rfc/rfc2732.txt.)
- Canonical XML
- "Canonical XML
Version 1.0", John Boyer, March 2001. (See http://www.w3.org/TR/xml-c14n.)
- Exclusive XML Canonicalization
- "Exclusive XML
Canonicalization Version 1.0", John Boyer, Donald E. Eastlake 3rd,
Joseph Reagle, July 2002. (See http://www.w3.org/TR/xml-exc-c14n.)
- XML Encryption
- "XML Encryption
Syntax and Processing", Donald Eastlake, Joseph Reagle, December
2002. (See http://www.w3.org/TR/xmlenc-core.)
- SOAP Part 1
- W3C
Recommendation "SOAP Version 1.2 Part 1: Messaging Framework", M.
Gudgin, M. Hadley, N. Mendelsohn, J-J. Moreau, H. F. Nielsen, May
2003. (See http://www.w3.org/TR/soap12-part1/.)
- SOAP Part 2
- W3C
Recommendation "SOAP Version 1.2 Part 2: Adjuncts", M. Gudgin, M.
Hadley, N. Mendelsohn, J-J. Moreau, H. F. Nielsen, May 2003. (See http://www.w3.org/TR/soap12-part2/.)
This specification is the work of the W3C XML Protocol Working Group.
Participants in the Working Group are (at the time of writing, and by
alphabetical order): David Fallside (IBM),
Tony Graham (Sun Microsystems),
Martin Gudgin (Microsoft Corporation, formerly of DevelopMentor),
Marc Hadley (Sun Microsystems),
Gerd Hoelzing (SAP AG),
John Ibbotson (IBM),
Anish Karmarkar (Oracle),
Suresh Kodichath (IONA Technologies),
Yves Lafon (W3C),
Michael Mahan (Nokia),
Noah Mendelsohn (IBM, formerly of Lotus Development),
Jeff Mischkinsky (Oracle),
Jean-Jacques Moreau (Canon),
Mark Nottingham (BEA Systems, formerly of Akamai Technologies),
David Orchard (BEA Systems, formerly of Jamcracker),
Herve Ruellan (Canon),
Jeff Schlimmer (Microsoft Corporation),
Pete Wenzel (SeeBeyond),
Volker Wiechers (SAP AG).
Previous participants were: Yasser alSafadi (Philips Research),
Bill Anderson (Xerox),
Vidur Apparao (Netscape),
Camilo Arbelaez (webMethods),
Mark Baker (Idokorro Mobile, Inc., formerly of Sun Microsystems),
Philippe Bedu (EDF (Electricite De France)),
Olivier Boudeville (EDF (Electricite De France)),
Carine Bournez (W3C),
Don Box (Microsoft Corporation, formerly of DevelopMentor),
Tom Breuel (Xerox),
Dick Brooks (Group 8760),
Winston Bumpus (Novell, Inc.),
David Burdett (Commerce One),
Charles Campbell (Informix Software),
Alex Ceponkus (Bowstreet),
Michael Champion (Software AG),
David Chappell (Sonic Software),
Miles Chaston (Epicentric),
David Clay (Oracle),
David Cleary (Progress Software),
Dave Cleary (webMethods),
Ugo Corda (Xerox),
Paul Cotton (Microsoft Corporation),
Fransisco Cubera (IBM),
Jim d'Augustine (Excelon Corporation),
Ron Daniel (Interwoven),
Glen Daniels (Macromedia),
Doug Davis (IBM),
Ray Denenberg (Library of Congress),
Paul Denning (MITRE Corporation),
Frank DeRose (TIBCO Software, Inc.),
Mike Dierken (DataChannel),
Andrew Eisenberg (Progress Software),
Brian Eisenberg (DataChannel),
Colleen Evans (Sonic Software),
John Evdemon (XMLSolutions),
David Ezell (Hewlett Packard),
James Falek (TIBCO Software, Inc.),
Eric Fedok (Active Data Exchange),
Chris Ferris (Sun Microsystems),
Daniela Florescu (Propel),
Dan Frantz (BEA Systems),
Michael Freeman (Engenia Software),
Dietmar Gaertner (Software AG),
Scott Golubock (Epicentric),
Mike Greenberg (IONA Technologies),
Rich Greenfield (Library of Congress),
Hugo Haas (W3C),
Mark Hale (Interwoven),
Randy Hall (Intel),
Bjoern Heckel (Epicentric),
Frederick Hirsch (Zolera Systems),
Erin Hoffmann (Tradia Inc.),
Steve Hole (MessagingDirect Ltd.),
Mary Holstege (Calico Commerce),
Jim Hughes (Fujitsu Limited),
Oisin Hurley (IONA Technologies),
Yin-Leng Husband (Hewlett Packard, formerly of Compaq),
Ryuji Inoue (Matsushita Electric Industrial Co., Ltd.),
Scott Isaacson (Novell, Inc.),
Kazunori Iwasa (Fujitsu Limited),
Murali Janakiraman (Rogue Wave),
Mario Jeckle (DaimlerChrysler Research and Technology),
Eric Jenkins (Engenia Software),
Mark Jones (AT&T),
Jay Kasi (Commerce One),
Jeffrey Kay (Engenia Software),
Richard Koo (Vitria Technology Inc.),
Jacek Kopecky (Systinet),
Alan Kropp (Epicentric),
Julian Kumar (Epicentric),
Peter Lecuyer (Progress Software),
Tony Lee (Vitria Technology Inc.),
Michah Lerner (AT&T),
Bob Lojek (Intalio Inc.),
Henry Lowe (OMG),
Brad Lund (Intel),
Matthew MacKenzie (XMLGlobal Technologies),
Murray Maloney (Commerce One),
Richard Martin (Active Data Exchange),
Alex Milowski (Lexica),
Kevin Mitchell (XMLSolutions),
Nilo Mitra (Ericsson),
Ed Mooney (Sun Microsystems),
Dean Moses (Epicentric),
Highland Mary Mountain (Intel),
Don Mullen (TIBCO Software, Inc.),
Rekha Nagarajan (Calico Commerce),
Raj Nair (Cisco Systems),
Masahiko Narita (Fujitsu Limited),
Mark Needleman (Data Research Associates),
Art Nevarez (Novell, Inc.),
Eric Newcomer (IONA Technologies),
Henrik Nielsen (Microsoft Corporation),
Conleth O'Connell (Vignette),
Kevin Perkins (Compaq),
Jags Ramnaryan (BEA Systems),
Andreas Riegg (DaimlerChrysler Research and Technology),
Vilhelm Rosenqvist (NCR),
Marwan Sabbouh (MITRE Corporation),
Waqar Sadiq (Vitria Technology Inc.),
Rich Salz (Zolera Systems),
Krishna Sankar (Cisco Systems),
George Scott (Tradia Inc.),
Shane Sesta (Active Data Exchange),
Lew Shannon (NCR),
John-Paul Sicotte (MessagingDirect Ltd.),
Miroslav Simek (Systinet),
Simeon Simeonov (Macromedia),
Aaron Skonnard (DevelopMentor),
Nick Smilonich (Unisys),
Seumas Soltysik (IONA Technologies),
Soumitro Tagore (Informix Software),
James Tauber (Bowstreet),
Anne Thomas Manes (Sun Microsystems),
Lynne Thompson (Unisys),
Patrick Thompson (Rogue Wave),
Jim Trezzo (Oracle),
Asir Vedamuthu (webMethods),
Randy Waldrop (WebMethods),
Fred Waskiewicz (OMG),
David Webber (XMLGlobal Technologies),
Ray Whitmer (Netscape),
Stuart Williams (Hewlett Packard),
Yan Xu (DataChannel),
Amr Yassin (Philips Research),
Susan Yee (Active Data Exchange),
Jin Yu (MartSoft Corp.).
The people who have contributed to discussions on
xml-dist-app@w3.org
are also gratefully acknowledged.