
Voice Extensible Markup Language
(VoiceXML) Version 2.0
W3C Working Draft, 23 October
2001
- This Version:
- http://www.w3.org/TR/2001/WD-voicexml20-20011023
- Latest Version:
- http://www.w3.org/TR/voicexml20
- Editors:
- Scott McGlashan, PipeBeach <Scott.McGlashan@pipebeach.com>
(Editor-in-Chief, Subgroup Chair)
Dan Burnett, Nuance Communications, <burnett@nuance.com>
Peter Danielsen, Lucent <pdanielsen@lucent.com>
Jim Ferrans, Motorola <James.Ferrans@motorola.com>
Andrew Hunt, SpeechWorks International <andrew.hunt@speechworks.com>
Gerald Karam, AT&T <karam@research.att.com>
Dave Ladd, Dynamicsoft <DLadd@dynamicsoft.com>
Bruce Lucas, IBM <bdlucas@us.ibm.com>
Brad Porter, Tellme <brad@tellme.com>
Ken Rehor, Nuance Communications <ken@nuance.com>
Steph Tryphonas, Tellme <steph@tellme.com>
Copyright ©2001 W3C®
(MIT,
INRIA, Keio), All
Rights Reserved. W3C
liability,
trademark,
document use and
software licensing rules apply.
This document specifies VoiceXML, the Voice Extensible Markup
Language. VoiceXML is designed for creating audio dialogs that
feature synthesized speech, digitized audio, recognition of
spoken and DTMF key input, recording of spoken input, telephony,
and mixed-initiative conversations. Its major goal is to bring
the advantages of web-based development and content delivery to
interactive voice response applications.
Status of this Document
This specification describes markup for representing audio
dialogs, and forms part of the proposals for the W3C Speech
Interface Framework. This document has been produced as part of
the W3C Voice Browser
Activity, following the procedures set out for the W3C Process. The
authors of this document are members of the Voice Browser Working
Group (W3C Members
only). This document is for public review, and comments and
discussion are welcomed on the public mailing list <www-voice@w3.org>. To
subscribe, send an email to <www-voice-request@w3.
org> with the word subscribe in the subject line
(include the word unsubscribe if you want to
unsubscribe). The archive
for the list is accessible online.
The proposed XML-based media types used in this specification
have been submitted to the IETF for registration. Please note
that during the registration process, the proposed media types
may be modified or removed.
The Memorandum of
Understanding between the W3C and the Voice XML Forum
has paved the way for the publication of this working draft,
with the VoiceXML Forum committing to abandoning trademark
applications involving the name "VoiceXML".
This document seeks Member and public comment on both the
technical design and the patent licensing issues arising out
of the disclosure
and licensing statements that have been made. Our
decision to publish this first public working draft has been
made to secure early comments from the community, but does
not imply that all questions of patent licensing have been
resolved or clarified. They must be resolved or work on this
document in W3C will stop. As things stand at the time of
publication of this specification, implementations
conforming to this specification may require royalty bearing
licenses for essential IPR. Further information can be found
in the patent
disclosures page. The patent policy for W3C as a whole
is under wide discussion. A set of
commitments by all participants in the Voice Browser
Activity to royalty free is a possibility for the future but
has NOT been made at time of publication.
This is a W3C Working Draft for review by W3C Members and
other interested parties. It is a draft document and may be
updated, replaced or made obsolete by other documents at any
time. It is inappropriate to use W3C Working Drafts as reference
material or to cite them as other than "work in progress".
This is work in progress and does not imply endorsement by the
W3C membership. A list of current W3C Recommendations and other
technical documents, including Working Drafts and Notes, can be
found at http://www.w3.org/TR/.
Conventions of this Document
In this document, the key words "must", "must not",
"required", "shall", "shall not", "should", "should not",
"recommended", "may", and "optional" are to be interpreted as
described in RFC
2119 and indicate requirement levels for compliant VoiceXML
implementations.
Abbreviated Contents
Full Contents
This document defines VoiceXML, the Voice Extensible Markup
Language. Its background, basic concepts and use are presented in
Section 1. The dialog constructs of form,
menu and link, and the mechanism (Form Interpretation Algorithm)
by which they are interpreted are then introduced in Section 2. User input using DTMF and speech
grammars is covered in Section 3, while Section 4 covers system output using speech
synthesis and recorded audio. Mechanisms for manipulating dialog
control flow, including variables, events, and executable
elements, are explained in Section 5.
Environment features such as parameters and properties as well as
resource handling are specified in Section 6.
The appendices provide additional information including the VoiceXML DTD, a detailed specification of the
Form Interpretation Algorithm and timing, audio
file formats, and statements relating to conformance, internationalization, accessibility and privacy.
Developers familar with VoiceXML 1.0 are particularly directed
to Changes from Previous Public
Version which summarizes how VoiceXML 2.0 differs from
VoiceXML 1.0.
VoiceXML is designed for creating audio dialogs that feature
synthesized speech, digitized audio, recognition of spoken and
DTMF key input, recording of spoken input, telephony, and
mixed-initiative conversations. Its major goal is to bring the
advantages of web-based development and content delivery to
interactive voice response applications.
Here are two short examples of VoiceXML. The first is the
venerable "Hello World":
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<block>Hello World!</block>
</form>
</vxml>
The top-level element is <vxml>, which is mainly a
container for dialogs. There are two types of dialogs:
forms and menus. Forms present information and
gather input; menus offer choices of what to do next. This
example has a single form, which contains a block that
synthesizes and presents "Hello World!" to the user. Since the
form does not specify a successor dialog, the conversation
ends.
Our second example asks the user for a choice of drink and
then submits it to a server script:
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<field name="drink">
<prompt>Would you like coffee,tea, milk, or nothing?</prompt>
<grammar src="drink.grxml" type="application/grammar+xml"/>
</field>
<block>
<submit next="http://www.drink.example.com/drink2.asp"/>
</block>
</form>
</vxml>
A field is an input field. The user must provide a
value for the field before proceeding to the next element in the
form. A sample interaction is:
C (computer): Would you like
coffee, tea, milk, or nothing?
H (human): Orange juice.
C: I did not understand what you said. (a
platform-specific default message.)
C: Would you like coffee, tea, milk, or nothing?
H: Tea
C: (continues in document
drink2.asp)
This section contains a high-level architectural model, whose
terminology is then used to describe the goals of VoiceXML, its
scope, its design principles, and the requirements it places on
the systems that support it.
The architectural model assumed by this document has the
following components:
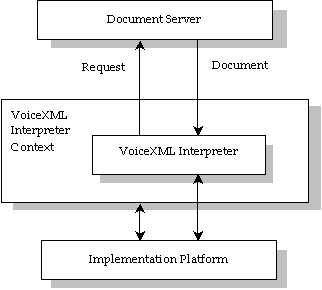
Figure 1: Architectural Model
A document server (e.g. a web server) processes
requests from a client application, the VoiceXML
Interpreter, through the VoiceXML interpreter context.
The server produces VoiceXML documents in reply, which are
processed by the VoiceXML Interpreter. The VoiceXML interpreter
context may monitor user inputs in parallel with the VoiceXML
interpreter. For example, one VoiceXML interpreter context may
always listen for a special escape phrase that takes the user to
a high-level personal assistant, and another may listen for
escape phrases that alter user preferences like volume or
text-to-speech characteristics.
The implementation platform is controlled by the
VoiceXML interpreter context and by the VoiceXML interpreter. For
instance, in an interactive voice response application, the
VoiceXML interpreter context may be responsible for detecting an
incoming call, acquiring the initial VoiceXML document,
and answering the call, while the VoiceXML interpreter conducts
the dialog after answer. The implementation platform generates
events in response to user actions (e.g. spoken or character
input received, disconnect) and system events (e.g. timer
expiration). Some of these events are acted upon by the VoiceXML
interpreter itself, as specified by the VoiceXML document, while
others are acted upon by the VoiceXML interpreter context.
VoiceXML’s main goal is to bring the full power of web
development and content delivery to voice response applications,
and to free the authors of such applications from low-level
programming and resource management. It enables integration of
voice services with data services using the familiar
client-server paradigm. A voice service is viewed as a sequence
of interaction dialogs between a user and an implementation
platform. The dialogs are provided by document servers, which may
be external to the implementation platform. Document servers
maintain overall service logic, perform database and legacy
system operations, and produce dialogs. A VoiceXML document
specifies each interaction dialog to be conducted by a VoiceXML
interpreter. User input affects dialog interpretation and is
collected into requests submitted to a document server. The
document server replies with another VoiceXML document to
continue the user’s session with other dialogs.
VoiceXML is a markup language that:
-
Minimizes client/server interactions by specifying multiple
interactions per document.
-
Shields application authors from low-level, and
platform-specific details.
-
Separates user interaction code (in VoiceXML) from service
logic (CGI scripts).
-
Promotes service portability across implementation platforms.
VoiceXML is a common language for content providers, tool
providers, and platform providers.
-
Is easy to use for simple interactions, and yet provides
language features to support complex dialogs.
While VoiceXML strives to accommodate the requirements of a
majority of voice response services, services with stringent
requirements may best be served by dedicated applications that
employ a finer level of control.
The language describes the human-machine interaction provided
by voice response systems, which includes:
-
Output of synthesized speech (text-to-speech).
-
Output of audio files.
-
Recognition of spoken input.
-
Recognition of DTMF input.
-
Recording of spoken input.
-
Control of dialog flow.
-
Telephony features such as call transfer and disconnect.
The language provides means for collecting character and/or
spoken input, assigning the input to document-defined request
variables, and making decisions that affect the interpretation of
documents written in the language. A document may be linked to
other documents through Universal Resource Identifiers
(URIs).
VoiceXML is an XML application. For details about XML, refer
to the Annotated
XML Specification .
-
The language promotes portability of services through
abstraction of platform resources.
-
The language accommodates platform diversity in supported
audio file formats, speech grammar formats, and URI schemes.
While producers of platforms may support various grammar formats
the language requires a common grammar format, namely the XML Form of the W3C
Speech Recognition Grammar Format, to facilitate
interoperability. Similarly, while various audio formats for
playback and recording may be supported, the audio formats
described in Appendix E must be
supported
-
The language supports ease of authoring for common types of
interactions.
-
The language has a well-defined semantics that preserves the
author's intent regarding the behavior of interactions with the
user. Client heuristics are not required to determine document
element interpretation.
-
The language has a control flow mechanism.
-
The language enables a separation of service logic from
interaction behavior.
-
It is not intended for intensive computation, database
operations, or legacy system operations. These are assumed to be
handled by resources outside the document interpreter, e.g. a
document server.
-
General service logic, state management, dialog generation,
and dialog sequencing are assumed to reside outside the document
interpreter.
-
The language provides ways to link documents using URIs, and
also to submit data to server scripts using URIs.
-
VoiceXML provides ways to identify exactly which data to
submit to the server, and which HTTP method (get or post) to use
in the submittal.
-
The language does not require document authors to explicitly
allocate and deallocate dialog resources, or deal with
concurrency. Resource allocation and concurrent threads of
control are to be handled by the implementation platform.
This section outlines the requirements on the
hardware/software platforms that will support a VoiceXML
interpreter.
Document acquisition. The interpreter context is
expected to acquire documents for the VoiceXML interpreter to act
on. The "http" URI protocol must be supported. In some cases, the
document request is generated by the interpretation of a VoiceXML
document, while other requests are generated by the interpreter
context in response to events outside the scope of the language,
for example an incoming phone call. When issuing document
requests via http, the interpreter context identifies itself
using the "User-Agent" header variable with the value
"<name>/<version>", for example,
"acme-browser/1.2"
Audio output. An implementation platform must support
audio output using audio files and text-to-speech (TTS). The
platform must be able to freely sequence TTS and audio output.
Audio files are referred to by a URI. The language specifies a
required set of audio file formats which must be supported (see
Appendix E); additional audio
file formats may also be supported.
Audio input. An implementation platform is required to
detect and report character and/or spoken input simultaneously
and to control input detection interval duration with a timer
whose length is specified by a VoiceXML document.
Transfer The platform should be able to support making
a third party connection through a communications network, such
as the telephone.
A VoiceXML document (or a set of documents called an
application) forms a conversational finite state machine.
The user is always in one conversational state, or dialog,
at a time. Each dialog determines the next dialog to transition
to. Transitions are specified using URIs, which define the
next document and dialog to use. If a URI does not refer to a
document, the current document is assumed. If it does not refer
to a dialog, the first dialog in the document is assumed.
Execution is terminated when a dialog does not specify a
successor, or if it has an element that explicitly exits the
conversation.
There are two kinds of dialogs: forms and menus.
Forms define an interaction that collects values for a set of
field item variables. Each field may specify a grammar that
defines the allowable inputs for that field. If a form-level
grammar is present, it can be used to fill several fields from
one utterance. A menu presents the user with a choice of options
and then transitions to another dialog based on that choice.
A subdialog is like a function call, in that it
provides a mechanism for invoking a new interaction, and
returning to the original form. Variable instances, grammars, and
state information are saved and are available upon returning to
the calling document. Subdialogs can be used, for example, to
create a confirmation sequence that may require a database query;
to create a set of components that may be shared among documents
in a single application; or to create a reusable library of
dialogs shared among many applications.
A session begins when the user starts to interact with
a VoiceXML interpreter context, continues as documents are loaded
and processed, and ends when requested by the user, a document,
or the interpreter context.
An application is a set of documents sharing the same
application root document. Whenever the user interacts
with a document in an application, its application root document
is also loaded. The application root document remains loaded
while the user is transitioning between other documents in the
same application, and it is unloaded when the user transitions to
a document that is not in the application. While it is loaded,
the application root document’s variables are available to
the other documents as application variables, and its
grammars can also be set to remain active for the duration of the
application.
Figure 2 shows the transition of documents (D) in an
application that share a common application root document
(root).
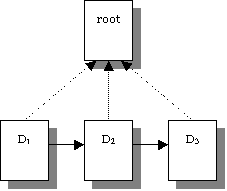
Figure 2: Transitioning between documents in an application.
Each dialog has one or more speech and/or DTMF grammars
associated with it. In machine directed applications, each
dialog’s grammars are active only when the user is in that
dialog. In mixed initiative applications, where the user
and the machine alternate in determining what to do next, some of
the dialogs are flagged to make their grammars active
(i.e., listened for) even when the user is in another dialog in
the same document, or on another loaded document in the same
application. In this situation, if the user says something
matching another dialog’s active grammars, execution
transitions to that other dialog, with the user’s utterance
treated as if it were said in that dialog. Mixed initiative adds
flexibility and power to voice applications.
VoiceXML provides a form-filling mechanism for handling
"normal" user input. In addition, VoiceXML defines a mechanism
for handling events not covered by the form mechanism.
Events are thrown by the platform under a variety of
circumstances, such as when the user does not respond, doesn't
respond intelligibly, requests help, etc. The interpreter also
throws events if it finds a semantic error in a VoiceXML
document. Events are caught by catch elements or their syntactic
shorthand. Each element in which an event can occur may specify
catch elements. Catch elements are also inherited from enclosing
elements "as if by copy". In this way, common event handling
behavior can be specified at any level, and it applies to all
lower levels.
A link supports mixed initiative. It specifies a
grammar that is active whenever the user is in the scope of the
link. If user input matches the link’s grammar, control
transfers to the link’s destination URI. A link can be used
to throw an event to go to a destination URI.
| Element |
Purpose |
Section |
| <assign> |
Assign a variable a value |
5.3.2 |
| <audio> |
Play an audio clip within a prompt |
4.1.3 |
| <block> |
A container of (non-interactive) executable code |
2.3.1 |
| <catch> |
Catch an event |
5.2.2 |
| <choice> |
Define a menu item |
2.2 |
| <clear> |
Clear one or more form item variables |
5.3.3 |
| <disconnect> |
Disconnect a session |
5.3.11 |
| <else> |
Used in <if> elements |
5.3.4 |
| <elseif> |
Used in <if> elements |
5.3.4 |
| <enumerate> |
Shorthand for enumerating the choices in a menu |
2.2 |
| <error> |
Catch an error event |
5.2.3 |
| <exit> |
Exit a session |
5.3.9 |
| <field> |
Declares an input field in a form |
2.3.1 |
| <filled> |
An action executed when fields are filled |
2.4 |
| <form> |
A dialog for presenting information and collecting data |
2.1 |
| <goto> |
Go to another dialog in the same or different document |
5.3.7 |
| <grammar> |
Specify a speech recognition or DTMF grammar |
3.1 |
| <help> |
Catch a help event |
5.2.3 |
| <if> |
Simple conditional logic |
5.3.4 |
| <initial> |
Declares initial logic upon entry into a (mixed-initiative)
form |
2.3.3 |
| <link> |
Specify a transition common to all dialogs in the
link’s scope |
2.5 |
| <log> |
Generate a debug message |
5.3.13 |
| <menu> |
A dialog for choosing amongst alternative destinations |
2.2 |
| <meta> |
Define a meta data item as a name/value pair |
6.2 |
| <noinput> |
Catch a noinput event |
5.2.3 |
| <nomatch> |
Catch a nomatch event |
5.2.3 |
| <object> |
Interact with a custom extension |
2.3.5 |
| <option> |
Specify an option in a <field> |
2.3 |
| <param> |
Parameter in <object> or <subdialog> |
6.4 |
| <prompt> |
Queue speech synthesis and audio output to the user |
4.1 |
| <property> |
Control implementation platform settings. |
6.3 |
| <record> |
Record an audio sample |
2.3.6 |
| <reprompt> |
Play a field prompt when a field is re-visited after an
event |
5.3.6 |
| <return> |
Return from a subdialog. |
5.3.10 |
| <script> |
Specify a block of ECMAScript client-side scripting
logic |
5.3.12 |
| <subdialog> |
Invoke another dialog as a subdialog of the current one |
2.3.4 |
| <submit> |
Submit values to a document server |
5.3.8 |
| <throw> |
Throw an event. |
5.2.1 |
| <transfer> |
Transfer the caller to another destination |
2.3.7 |
| <value> |
Insert the value of an expression in a prompt |
4.1.4 |
| <var> |
Declare a variable |
5.3.1 |
| <vxml> |
Top-level element in each VoiceXML document |
1.5.1 |
A VoiceXML document is primarily composed of top-level
elements called dialogs. There are two types of dialogs:
forms and menus. A document may also have
<meta> elements, <var> and <script> elements,
<property> elements, <catch> elements, and
<link> elements.
Document execution begins at the first dialog by default. As
each dialog executes, it determines the next dialog. When a
dialog doesn’t specify a successor dialog, document
execution stops.
Here is "Hello World!" expanded to illustrate some of this. It
now has a document level variable called "hi" which holds the
greeting. Its value is used as the prompt in the first form. Once
the first form plays the greeting, it goes to the form named
"say_goodbye", which prompts the user with "Goodbye!" Because the
second form does not transition to another dialog, it causes the
document to be exited.
<?xml version="1.0"?>
<vxml version="2.0">
<meta name="author" content="John Doe"/>
<meta name="maintainer" content="hello-support@hi.example.com"/>
<var name="hi" expr="'Hello World!'"/>
<form>
<block>
<value expr="hi"/>
<goto next="#say_goodbye"/>
</block>
</form>
<form id="say_goodbye">
<block>
Goodbye!
</block>
</form>
</vxml>
Stylistically it is best to combine the forms:
<?xml version="1.0"?>
<vxml version="2.0">
<meta name="author" content="John Doe"/>
<meta name="maintainer" content="hello-support@hi.example.com"/>
<var name="hi" expr="'Hello World!'"/>
<form>
<block>
<value expr="hi"/> Goodbye!
</block>
</form>
</vxml>
Attributes of <vxml> include:
| version |
The version of VoiceXML of this document (required). The
current version number is 2.0. |
| base |
The base URI. As in HTML, an absolute URI which all relative
references within the document take as their base. |
| xml:lang |
The language and locale type for this document as defined in
RFC 1766. If
omitted, the value is a platform-specific default. |
| application |
The URI of this document’s application root document,
if any. |
Language information is inherited down the document hierarchy:
the value of "xml:lang" is inherited by elements which also
define the "xml:lang" attribute, such as <grammar> and
<prompt>, unless these elements specify an alternative
value.
Normally, each document runs as an isolated application. In
cases where you want multiple documents to work together as one
application, you select one document to be the application
root document, and refer to it in the other
documents’<vxml> elements.
When this is done, every time the interpreter is told to load
a document in this application, it also loads the application
root document if it is not already loaded. The application root
document remains loaded until the interpreter is told to load a
document that belongs to a different application. Thus one of the
following two conditions always holds during interpretation:
-
The application root document is loaded and the user is
executing in it.
-
The application root document and one other document in the
application, known as an application leaf document, are
both loaded and the user is executing in the leaf document.
If there is a chain of subdialogs defined in separate
documents, then there may be more than one leaf document loaded
although execution will only be in one of these documents.
There are several benefits to multi-document applications.
First, the application root document’s variables are
available for use by the other documents in the application, so
that information can be shared and retained. Second, the grammars
of the application root document are active even when the user is
in other application documents, so that the user can always
interact with forms, links, and menus from the application root
document. Third, catch elements of the application root document
can define default event handling for all documents within the
application. Fourth, property elements in the application root
document can specify default values for properties used
throughout the application.
Here is a two-document application illustrating this:
Application root document (app-root.vxml)
<?xml version="1.0"?>
<vxml version="2.0">
<var name="bye" expr="'Ciao'"/>
<link next="operator_xfer.vxml">
<grammar>
<rule id="root" scope="public">operator</rule>
</grammar>
</link>
</vxml>
Leaf document (leaf.vxml)
<?xml version="1.0"?>
<vxml version="2.0" application="app-root.vxml">
<form id="say_goodbye">
<field name="answer" type="boolean">
<prompt>Shall we say <value expr="application.bye"/>?</prompt>
<filled>
<if cond="answer">
<exit/>
</if>
<clear namelist="answer"/>
</filled>
</field>
</form>
</vxml>
In this example, the application is designed so that leaf.vxml
must be loaded first. Its application attribute specifies that
app-root.vxml should be used as the application root document.
So, app-root.vxml is then loaded, which creates the application
variable bye and also defines a link that navigates to
operator-xfer.vxml whenever the user says "operator". The user
starts out in the say_goodbye form:
C: Shall we say Ciao?
H: Si.
C: I did not understand what you said. (a
platform-specific default message.)
C: Shall we say Ciao?
H: Ciao
C: I did not understand what you said.
H: Operator.
C: (Goes to operator_xfer.vxml, which
transfers the caller to a human operator.)
Note that when the user is in a multi-document application, at
most two documents are loaded at any one time: the application
root document and, unless the user is actually interacting with
the application root document, an application leaf document.A
root document's <vxml> element does not have an application
attribute specified. A leaf document's <vxml> element does
have an application attribute specified. An interpreter always
has an application root document loaded; it does not always have
an application leaf document loaded.
The name of the interpreter's current application is
the application root document's absolute URI. The absolute URI
includes a query string, if present, but it does not include a
fragment identifier. The interpreter remains in the same
application as long as the name remains the same. When the name
changes, a new application is entered and its root context is
initialized. The application's root context consists of the
variables, grammars, catch elements, and properties in
application scope.
During a user session an interpreter transitions from one
document to another as requested by <choice>, <goto>
<link>, <subdialog>, and <submit> elements.
Some transitions are within an application, others are between
applications. The preservation or initialization of the root
context depends on the type of transition:
- Root to Leaf Within Application
- A root to leaf transition within the same application occurs
when the current document is a root document and the target
document's application attribute's value resolves to the same
absolute URI as the name of the current application. The
application root document and its context are preserved.
- Leaf to Leaf Within Application
- A leaf to leaf transition within the same application occurs
when the current document is a leaf document and the target
document's application attribute's value resolves to the same
absolute URI as the name of the current application. The
application root document and its context are preserved.
- Leaf to Root Within Application
- A leaf to root transition within the same application occurs
when the current document is a leaf document and the target
document's absolute URI is the same as the name of the current
application. The current application root document and its
context are preserved when the transition is caused by a
<choice>, <goto>, or <link> element. The root
context is initialized when a <submit> element causes the
leaf to root transition.
- Root to Root
- A root to root transition occurs when the current document is
a root document and the target document is a root document, i.e.
it does not have an application attribute. The root context is
initialized with the new application root document, even if the
documents are the same or have the same application name.
- Subdialog
- A subdialog invocation occurs when a root or leaf document
executes a <subdialog> element. As discussed in Section 2.3.4, subdialog invocation creates
a new execution context. The application root document and its
context in the calling document's execution context are preserved
untouched during subdialog execution, and are used again once the
subdialog returns. A subdialog's new execution context has its
own root context and, possibly, leaf context. If a subdialog is
invoked with an empty URI reference and a fragment identifier,
e.g. "#sub1", the new root and leaf contexts are initialized from
the root and leaf documents used by the calling dialog. When the
subdialog is invoked with a non-empty URI reference, the caching
policy in Section 6.1.2 is used to
acquire the root and leaf documents that will be used to
initialize the new root and leaf contexts.
- Inter-Application Transitions
- All other transitions are between applications which cause
the application root context to be initialized with the next
application's root document.
If a document refers to a non-existent application root
document, or if a document's application attribute refers to a
document that also has an application attribute specified, an
error.semantic event is thrown.
The following diagrams illustrate the effect of the
transitions between root and leaf documents on the application
root context. In these diagrams, boxes represent documents, box
texture changes identify root context initialization, solid
arrows symbolize transitions to the URI in the arrow's label,
dashed vertical arrows indicate an application attribute whose
URI is the arrow's label.
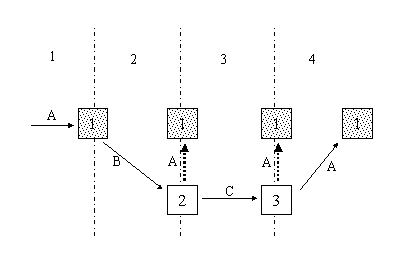
Figure 3: Transitions that Preserve the Root Context
In this diagram, all the documents belong to the same
application. The transitions are identified by the numbers 1-4
across the top of the figure. They are:
- A transition to URI A results in document 1, the application
context is initialized from document 1's content. Assume that
this is the first document in the session. The current
application's name is A.
- Document 1 specifies a transition to URI B, which yields
document 2. Document 2's application attribute equals URI A. The
root is document 1 with its context preserved. This is a root to
leaf transition within the same application.
- Document 2 specifies a transition to URI C, which yields
another leaf document, document 3. Its application attribute also
equals URI A. The root is document 1 with its context preserved.
This is a leaf to leaf transition within the same
application.
- Document 3 specifies a transition to URI A using a
<choice>, <goto>, or <link>. Document 1 is used
with its root context intact. This is a leaf to root transition
within the same application.
The next diagram illustrates transitions which initialize the
root context.
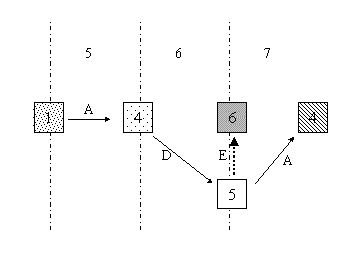
Figure 4: Transitions that Initialize the Root Context
- Document 1 specifies a transition to its own URI A. The
resulting document 4 does not have an application attribute, so
it is considered a root document, and the root context is
initialized. This is a root to root transition.
- Document 4 specifies a transition to URI D, which yields a
leaf document 5. Its application attribute is different: URI E. A
new application is being entered. URI E produces the root
document 6. The root context is initialized from the content of
document 6. This is an inter-application transition.
- Document 5 specifies a transition to URI A. The cache check
returns document 4 which does not have an application attribute
and therefore belongs to application A, so the root context is
initialized. Initialization occurs even though this application
and this root document were used earlier in the session. This is
an inter-application transition.
A subdialog is a mechanism for decomposing complex sequences
of dialogs to better structure them, or to create reusable
components. For example, the solicitation of account information
may involve gathering several pieces of information, such as
account number, and home telephone number. A customer care
service might be structured with several independent applications
that could share this basic building block, thus it would be
reasonable to construct it as a subdialog. This is illustrated in
the example below. The first document, app.vxml, seeks to adjust
a customer’s account, and in doing so must get the account
information and then the adjustment level. The account
information is obtained by using a subdialog element that invokes
another VoiceXML document to solicit the user input. While the
second document is being executed, the calling dialog is
suspended, awaiting the return of information. The second
document provides the results of its user interactions using a
<return> element, and the resulting values are accessed
through the variable defined by the name attribute on the
<subdialog> element.
Customer Service Application (app.vxml)
<?xml version="1.0"?>
<vxml version="2.0">
<form id="billing_adjustment">
<var name="account_number"/>
<var name="home_phone"/>
<subdialog name="accountinfo" src="acct_info.vxml#basic">
<filled>
<!-- Note the variable defined by "accountinfo" is
returned as an ECMAScript object and it contains two
properties defined by the variables specified in the
"return" element of the subdialog. -->
<assign name="account_number" expr="accountinfo.acctnum"/>
<assign name="home_phone" expr="accountinfo.acctphone"/>
</filled>
</subdialog>
<field name="adjustment_amount" type="currency">
<prompt>
What is the value of your account adjustment?
</prompt>
<filled>
<submit next="/cgi-bin/updateaccount"/>
</filled>
</field>
</form>
</vxml>
Document Containing Account Information Subdialog
(acct_info.vxml)
<?xml version="1.0"?>
<vxml version="2.0">
<form id="basic">
<field name="acctnum" type="digits">
<prompt> What is your account number? </prompt>
</field>
<field name="acctphone" type="phone">
<prompt> What is your home telephone number? </prompt>
<filled>
<!-- The values obtained by the two fields are supplied
to the calling dialog by the "return" element. -->
<return namelist="acctnum acctphone"/>
</filled>
</field>
</form>
</vxml>
Subdialogs add a new execution context when they are
invoked.The subdialog could be a new dialog within the existing
document, or a new dialog within a new document.
Subdialogs can be composed of several documents. Figure 5
shows the execution flow where a sequence of documents (D)
transitions to a subdialog (SD) and then back.
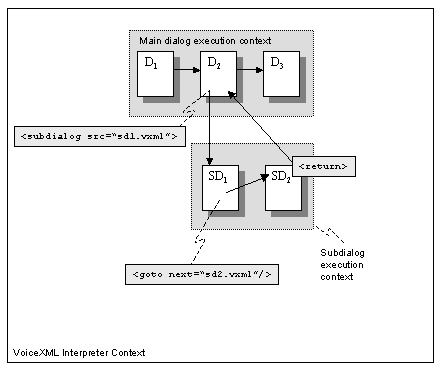
Figure 5: Subdialog composed of several documents
returning from the last subdialog document.
The execution context in dialog D2 is suspended when it
invokes the subdialog SD1 in document sd1.vxml. This subdialog
specifies execution is to be transfered to the dialog in sd2.vxml
(using <goto>). Consequently, when the dialog in sd2.vxml
returns, control is returned directly to dialog D2.
Figure 6 shows an example of a multi-document subdialog where
control is transferred from one subdialog to another.
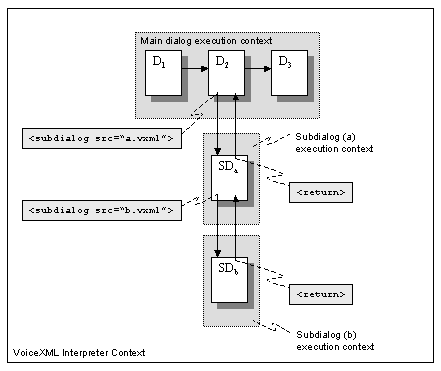
Figure 6: Subdialog composed of several documents
returning from the first subdialog document.
The subdialog in sd1.vxml specifies that control is to be
transfered to a second subdialog, SD2, in sd2.vxml. When
executing SD2, there are two suspended contexts: the dialog
context in D2 is suspending awaiting SD1 to return; and the
dialog context in SD1 awaiting SD2 to return. When SD2 returns,
control is returned to the SD1. It in turn returns control to
dialog D2.
Forms are the key component of VoiceXML documents. A form
contains:
-
A set of form items, elements that are visited in the
main loop of the form interpretation algorithm. Form items are
subdivided into field items, those that define the
form’s field item variables, and control items,
those that help control the gathering of the form’s
fields.
-
Declarations of non-field item variables.
-
Event handlers.
-
"Filled" actions, blocks of procedural logic that execute when
certain combinations of field items are filled in.
Form attributes are:
| id |
The name of the form. If specified, the form can be
referenced within the document or from another document. For
instance <form id="weather">, <goto
next="#weather">. |
| scope |
The default scope of the form’s grammars. If it is
dialog then the form grammars are active only in the form. If the
scope is document, then the form grammars are active during any
dialog in the same document. If the scope is document and the
document is an application root document, then the form grammars
are active during any dialog in any document of this application.
Note that the scope of individual form grammars takes precedence
over the default scope; for example, in non-root documents a form
with the default scope "dialog", and a form grammar with the
scope "document", then that grammar is active in any dialog in
the document. |
This section describes some of the concepts behind forms, and
then gives some detailed examples of their operation.
Forms are interpreted by an implicit form interpretation
algorithm (FIA). The FIA has a main loop that repeatedly selects
a form item and then visits it. The selected form item is the
first in document order whose guard condition is not satisfied.
For instance, a field item’s default guard condition tests
to see if the field item variable has a value, so that if a
simple form contains only field items, the user will be prompted
for each field item in turn.
Interpreting a form item generally involves:
-
Selecting and playing one or more prompts;
-
Collecting a user input, either a response that fills in one
or more fields, or a throwing of some event (help, for instance);
and
-
Interpreting any <filled> actions that pertained to the
newly filled in fields.
The FIA ends when it interprets a transfer of control
statement (e.g. a <goto> to another dialog or document, or
a <submit> of data to the document server). It also ends
with an implied <exit> when no form item remains eligible
to select.
The FIA is described in more detail in Section 2.1.6.
A form’s form items are the elements that can be visited
in the main loop of the form interpretation algorithm. Field
items direct the FIA to gather a specific field. When the FIA
selects a control item, the control item may contain a block of
procedural code to execute, or it may tell the FIA to set up the
initial prompt-and-collect for a mixed initiative form.
A field item specifies a field item variable to gather
from the user. Field items have prompts to tell the user what to
say or key in, grammars that define the allowed inputs, and event
handlers that process any resulting events. A field item may also
have a <filled> element that defines an action to take just
after the field item variable is filled in. Field items are
subdivided into:
| <field> |
A field item whose value is obtained via ASR or DTMF
grammars. |
| <record> |
A field item whose value is an audio clip recorded by the
user. A <record> element could collect a voice mail
message, for instance. |
| <transfer> |
A field item which transfers the user to another telephone
number. If the transfer returns control, the field variable will
be set to the result status. |
| <object> |
This field item invokes a platform-specific "object" with
various parameters. The result of the platform object is an
ECMAScript Object with one or more properties. One platform
object could be a builtin dialog that gathers credit card
information. Another could gather a text message using some
proprietary DTMF text entry method. There is no requirement for
implementations to provide platform-specific objects, although
implementations must handle the <object> element by
throwing error.unsupported.object if the particular
platform-specific object is not supported. |
| <subdialog> |
A <subdialog> field item is roughly like a function
call. It invokes another dialog on the current page, or invokes
another VoiceXML document. It returns an ECMAScript Object as its
result. |
There are two types of control items:
| <block> |
A sequence of procedural statements used for prompting and
computation, but not for gathering input. A block has a (normally
implicit) form item variable that is set to true just before it
is interpreted. |
| <initial> |
This element controls the initial interaction in a mixed
initiative form. Its prompts should be written to encourage the
user to say something matching a form level grammar. When at
least one field item variable is filled as a result of
recognition during an <initial> element, the form item
variable of <initial> becomes true, thus removing it as an
alternative for the FIA. |
Each form item has an associated form item variable,
which by default is set to undefined when the form is entered.
This form item variable will contain the result of interpreting
the form item. A field item’s form item variable is also
called a field item variable, and it holds the value
collected from the user. A form item variable can be given a name
using the name attribute, or left nameless, in which case an
internal name is generated.
Each form item also has a guard condition, which
governs whether or not that form item can be selected by the form
interpretation algorithm. The default guard condition just tests
to see if the form item variable has a value. If it does, the
form item will not be visited.
Typically, field items are given names, but control items are
not. Generally form item variables are not given initial values
and additional guard conditions are not specified. But sometimes
there is a need for more detailed control. One form may have a
form item variable initially set to hide a field, and later
cleared (e.g., using <clear>) to force the field’s
collection. Another field may have a guard condition that
activates it only when it has not been collected, and when two
other fields have been filled. A block item could execute only
when some condition holds true. Thus, fine control can be
exercised over the order in which form items are selected and
executed by the FIA, however in general, many dialogs can be
constructed without resorting to this level of complexity.
In summary, all form items have the following attributes:
| name |
The name of a dialog-scoped form item variable that will hold
the value of the form item. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be executed unless the form item variable is
cleared. |
| cond |
An expression to evaluate in conjunction with the test of the
form item variable. If absent, this defaults to true, or in the
case of <initial>, a test to see if any field item variable
has been filled in. |
The simplest and most common type of form is one in which the
form items are executed exactly once in sequential order to
implement a computer-directed interaction. Here is a weather
information service that uses such a form.
<form id="weather_info">
<block>Welcome to the weather information service.</block>
<field name="state">
<prompt>What state?</prompt>
<grammar src="state.grxml" type="application/grammar+xml"/>
<catch event="help">
Please speak the state for which you want the weather.
</catch>
</field>
<field name="city">
<prompt>What city?</prompt>
<grammar src="city.grxml" type="application/grammar+xml"/>
<catch event="help">
Please speak the city for which you want the weather.
</catch>
</field>
<block>
<submit next="/servlet/weather" namelist="city state"/>
</block>
</form>
This dialog proceeds sequentially:
C (computer): Welcome to the weather information service. What
state?
H (human): Help
C: Please speak the state for which you want the weather.
H: Georgia
C: What city?
H: Tblisi
C: I did not understand what you said. What city?
H: Macon
C: The conditions in Macon Georgia are sunny and clear at 11
AM ...
The form interpretation algorithm’s first iteration
selects the first block, since its (hidden) form item variable is
initially undefined. This block outputs the main prompt, and its
form item variable is set to true. On the FIA’s second
iteration, the first block is skipped because its form item
variable is now defined, and the state field is selected because
the dialog variable state is undefined. This field prompts the
user for the state, and then sets the variable state to the
answer. The third form iteration prompts and collects the city
field. The fourth iteration executes the final block and
transitions to a different URI.
Each field in this example has a prompt to play in order to
elicit a response, a grammar that specifies what to listen for,
and an event handler for the help event. The help event is thrown
whenever the user asks for assistance. The help event handler
catches these events and plays a more detailed prompt.
Here is a second directed form, one that prompts for credit
card information:
<form id="get_card_info">
<block>We now need your credit card type, number,
and expiration date.</block>
<field name="card_type">
<prompt count="1">What kind of credit card
do you have?</prompt>
<prompt count="2">Type of card?</prompt>
<!-- This is an inline grammar. -->
<grammar>
<rule id="r2" scope="public">
<one-of>
<item>visa</item>
<item>master <count number="optional">card</count></item>
<item>amex</item>
<item>american express</item>
</one-of>
</rule>
</grammar>
<help> Please say Visa, Mastercard, or American Express.</help>
</field>
<!-- The grammar for type="digits" is built in. -->
<field name="card_num" type="digits">
<prompt count="1">What is your card number?</prompt>
<prompt count="2">Card number?</prompt>
<catch event="help">
<if cond="card_type =='amex' || card_type =='american express'">
Please say or key in your 15 digit card number.
<else/>
Please say or key in your 16 digit card number.
</if>
</catch>
<filled>
<if cond="(card_type == 'amex' || card_type =='american express')
&& card_num.length != 15">
American Express card numbers must have 15 digits.
<clear namelist="card_num"/>
<throw event="nomatch"/>
<elseif cond="card_type != 'amex'
&& card_type !='american express'
&& card_num.length != 16"/>
Mastercard and Visa card numbers have 16 digits.
<clear namelist="card_num"/>
<throw event="nomatch"/>
</if>
</filled>
</field>
<field name="expiry_date" type="digits">
<prompt count="1">What is your card's expiration date?</prompt>
<prompt count="2">Expiration date?</prompt>
<help>
Say or key in the expiration date, for example one two oh one.
</help>
<filled>
<!-- validate the mmyy -->
<var name="mm"/>
<var name="i" expr="expiry_date.length"/>
<if cond="i == 3">
<assign name="mm" expr="expiry_date.substring(0,1)"/>
<elseif cond="i == 4"/>
<assign name="mm" expr="expiry_date.substring(0,2)"/>
</if>
<if cond="mm == '' || mm < 1 || mm > 12">
<clear namelist="expiry_date"/>
<throw event="nomatch"/>
</if>
</filled>
</field>
<field name="confirm" type="boolean">
<prompt>
I have <value expr="card_type"/> number
<value expr="card_num"/>, expiring on
<value expr="expiry_date"/>.
Is this correct?
</prompt>
<filled>
<if cond="confirm">
<submit next="place_order.asp"
namelist="card_type card_num expiry_date"/>
</if>
<clear namelist="card_type card_num expiry_date acknowledge"/>
</filled>
</field>
</form>
Note that the grammar alteratives 'amex' and 'american
express' return literal values which need to be handled
separately in the conditional expressions. Section 3.1.5 describes how semantic
attachments in the grammar can be used to return a single
representation of these inputs.
The dialog might go something like this:
C: We now need your credit card type, number, and expiration
date.
C: What kind of credit card do you have?
H: Discover
C: I did not understand what you said. (a
platform-specific default message.)
C: Type of card? (the second prompt is
used now.)
H: Shoot. (fortunately treated as "help"
by this platform)
C: Please say Visa, Master card, or American Express.
H: Uh, Amex. (this platform ignores
"uh")
C: What is your card number?
H: One two three four ... wait ...
C: I did not understand what you said.
C: Card number?
H: (uses DTMF) 1 2 3 4 5 6 7 8 9 0
1 2 3 4 5 #
C: What is your card’s expiration date?
H: one two oh one
C: I have Amex number 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 expiring
on 1 2 0 1. Is this correct?
H: Yes
Fields are the major building blocks of forms. A field
declares a variable and specifies the prompts, grammars, DTMF
sequences, help messages, and other event handlers that are used
to obtain it. Each field declares a VoiceXML field item variable
in the form’s dialog scope. These may be submitted once the
form is filled, or copied into other variables.
Each field has its own speech and/or DTMF grammars, specified
explicitly using <grammar> elements, or implicitly using
the type attribute. The type attribute is used for standard
builtin grammars, like digits, boolean, or number. The type
attribute also governs how that field’s value is spoken by
the speech synthesizer.
Each field can have one or more prompts. If there is one, it
is repeatedly used to prompt the user for the value until one is
provided. If there are many, they must be given count attributes.
These determine which prompt to use on each attempt. In the
example, prompts become shorter. This is called tapered
prompting.
The <catch event="help"> elements are event handlers
that define what to do when the user asks for help. Help messages
can also be tapered. These can be abbreviated, so that the
following two elements are equivalent:
<catch event="help">
Please say visa, mastercard, or amex.
</catch>
<help>
Please say visa, mastercard, or amex.
</help>
The <filled> element defines what to do when the user
provides a recognized input for that field. One use is to specify
integrity constraints over and above the checking done by the
grammars, as with the date field above.
The last section talked about forms implementing rigid,
computer-directed conversations. To make a form mixed
initiative, where both the computer and the human direct the
conversation, it must have one or more <initial> form items
and one or more form-level grammars.
If a form has form-level grammars:
The filling of field variables when using a form-level grammar
is described in Section 3.1.6.
Also, the form’s grammars can be active when the user is
in other dialogs. If a document has two forms on it, say a car
rental form and a hotel reservation form, and both forms have
grammars that are active for that document, a user could respond
to a request for hotel reservation information with information
about the car rental, and thus direct the computer to talk about
the car rental instead. The user can speak to any active grammar,
and have fields set and actions taken in response.
Example. Here is a second version of the weather
information service, showing mixed initiative. It has been
"enhanced" for illustrative purposes with advertising and with a
confirmation of the city and state:
<form id="weather_info">
<grammar src="cityandstate.grxml" type="application/grammar+xml"/>
<!-- Caller can't barge in on today's advertisement. -->
<block>
<prompt bargein="false">
Welcome to the weather information service.
<audio src="http://www.online-ads.example.com/wis.wav"/>
</prompt>
</block>
<initial name="start">
<prompt>
For what city and state would you like the weather?
</prompt>
<help>
Please say the name of the city and
state for which you would like a weather report.
</help>
<!-- If user is silent, reprompt once, then
try directed prompts. -->
<noinput count="1"> <reprompt/></noinput>
<noinput count="2"> <reprompt/>
<assign name="start" expr="true"/></noinput>
</initial>
<field name="state">
<prompt>What state?</prompt>
<help>
Please speak the state for which you want the weather.
</help>
</field>
<field name="city">
<prompt>Please say the city in <value expr="state"/>
for which you want the weather.</prompt>
<help>Please speak the city for which you
want the weather.</help>
<filled>
<!-- Most of our customers are in LA. -->
<if cond="city == 'Los Angeles' && state == undefined">
<assign name="state" expr="'California'"/>
</if>
</filled>
</field>
<field name="go_ahead" type="boolean" modal="true">
<prompt>Do you want to hear the weather for
<value expr="city"/>, <value expr="state"/>?
</prompt>
<filled>
<if cond="go_ahead">
<prompt bargein="false">
<audio src="http://www.online-ads.example.com/wis2.wav"/>
</prompt>
<submit next="/servlet/weather" namelist="city state"/>
</if>
<clear namelist="start city state go_ahead"/>
</filled>
</field>
</form>
Here is a transcript showing the advantages for even a novice
user:
C: Welcome to the weather information service. Buy Joe’s
Spicy Shrimp Sauce.
C: For what city and state would you like the weather?
H: Uh, California.
C: Please say the city in California for which you want the
weather.
H: San Francisco, please.
C: Do you want to hear the weather for San Francisco,
California?
H: No
C: For what city and state would you like the weather?
H: Los Angeles.
C: Do you want to hear the weather for Los Angeles,
California?
H: Yes
C: Don’t forget, buy Joe’s Spicy Shrimp Sauce
tonight!
C: Mostly sunny today with highs in the 80s. Lows tonight from
the low 60s ...
The go_ahead field has its modal attribute set to true. This
causes all grammars to be disabled except the ones defined in the
current form item, so that the only grammar active during this
field is the builtin grammar for boolean.
An experienced user can get things done much faster (but is
still forced to listen to the ads):
C: Welcome to the weather information service. Buy Joe’s
Spicy Shrimp Sauce.
C: What ...
H (barging in): LA
C: Do you ...
H (barging in): Yes
C: Don’t forget, buy Joe’s Spicy Shrimp Sauce
tonight!
C: Mostly sunny today with highs in the 80s. Lows tonight from
the low 60s ...
The form interpretation algorithm can be customized in several
ways. One way is to assign a value to a form item variable, so
that its form item will not be selected. Another is to use
<clear> to set a form item variable to undefined; this
forces the FIA to revisit the form item again.
Another method is to explicitly specify the next field item to
visit using <goto nextitem>. This forces an immediate
transfer to that field item. No variables, conditions or counters
in the targeted form item will be reset. The form item's prompt
will be played even if it has already been visited. If the
<goto nextitem> occurs in a <filled> action, the rest
of the <filled> action and any pending <filled>
actions will be skipped.
Here is an example <goto nextitem> executed in response
to the exit event:
<form id="survey_2000_03_30">
<catch event="exit">
<reprompt/>
<goto nextitem="confirm_exit"/>
</catch>
<block>
<prompt>
Hello, you have been called at random to answer questions
critical to U.S. foreign policy.
</prompt>
</block>
<field name="q1" type="boolean">
<prompt>Do you agree with the IMF position on
privatizing certain functions of Burkina Faso’s
agriculture ministry?</prompt>
</field>
<field name="q2" type="boolean">
<prompt>If this privatization occurs, will its
effects be beneficial mainly to Ouagadougou and
Bobo-Dioulasso?</prompt>
</field>
<field name="q3" type="boolean">
<prompt>Do you agree that sorghum and millet output
might thereby increase by as much as four percent per
annum?</prompt>
</field>
<block>
<submit next="register" namelist="q1 q2 q3"/>
</block>
<field name="confirm_exit" type="boolean">
<prompt>You have elected to exit. Are you
sure you want to do this, and perhaps adversely affect
U.S. foreign policy vis-`-vis sub-Saharan Africa for
decades to come?</prompt>
<filled>
<if cond="confirm_exit">
Okay, but the U.S. State Department is displeased.
<exit/>
<else/>
Good, let's pick up where we left off.
<clear namelist="confirm_exit"/>
</if>
</filled>
</field>
</form>
If the user says "exit" in response to any of the survey
questions, an exit event is thrown by the platform and caught by
the <catch> event handler. This handler directs that
confirm_exit be the next visited field. The confirm_exit field
would not be visited during normal completion of the survey
because the preceding <block> element transfers control to
the registration script.
We’ve presented the form interpretation algorithm (FIA)
at a conceptual level. In this section we describe it in more
detail. A more formal description is provided in Appendix C.
Whenever a form is entered, it is initialized. Internal prompt
counter variables (in the form’s dialog scope) are reset to
1. Each variable (form-level <var> elements and form item
variables) is initialized, in document order, to undefined or to
the value of the relevant expr attribute.
The main loop of the FIA has three phases:
The select phase: the next form item is selected for
visiting.
The collect phase: the next unfilled form
item is visited, which prompts the user for input, enables
the appropriate grammars, and then waits for and collects an
input (such as a spoken phrase or DTMF key presses) or
an event (such as a request for help or a no input
timeout).
The process phase: an input is processed by filling
form items and executing <filled> elements to perform
actions such as input validation. An event is processed by
executing the appropriate event handler for that event type.
Note that the FIA may be given an input (a set of grammar
slot/slot value pairs) that was collected while the user was in a
different form’s FIA. In this case the first iteration of
the main loop skips the select and collect phases, and goes right
to the process phase with that input.
The purpose of the select phase is to select the next form
item to visit. This is done as follows:
If a <goto> from the last main loop iteration’s
process phase specified a <goto nextitem>, then the
specified form item is selected.
Otherwise the first form item whose guard condition
is false is chosen to be visited.
If no guard condition is false, then the last iteration
completed the form without encountering an explicit transfer of
control, so the FIA does an implicit <exit> operation.
The purpose of the collect phase is to collect an input or an
event. The selected form item is visited, which performs
actions that depend on the type of form item:
If a field item is visited, the FIA selects and queues up any
prompts based on the field item’s prompt counter and the
prompt conditions. Then it listens for the field level grammar(s)
and any active higher-level grammars, and waits for a grammar
recognition or for some event.
If a <transfer> is visited, the prompts are queued based
on the item’s prompt counter and the prompt conditions. The
item grammars are activated. The queue is played before the
transfer is executed.
If a <subdialog> or <object> is visited, the
prompts are queued based on the item’s prompt counter and
the prompt conditions. Grammars are not activated. Instead, the
input collection behavior is specified by the executing context
for the subdialog or object. The queue is not played before the
subdialog or object is executed, but instead should be played
during the subsequent input collection.
If an <initial> is visited, the FIA selects and queues
up prompts based on the <initial>’s prompt counter
and prompt conditions. Then it listens for the form level
grammar(s) and any active higher-level grammars. It waits for a
grammar recognition or for an event.
A <block> element is visited by setting its form item
variable to true, evaluating its content, and then bypassing the
process phase. No input is collected, and the next iteration of
the FIA’s main loop is entered.
The purpose of the process phase is to process the input or
event collected during the collect phase, as follows:
- If an event (such as a noinput or a hangup) occurred, then
the applicable catch element is identified and executed.
Selection of the applicable catch element starts in the scope of
the current form item and then proceeds outward by enclosing
dialog scopes. This can cause the FIA to terminate (e.g. if it
transitions to a different dialog or document or it does an
<exit>), or it can cause the FIA to go into the next
iteration of the main loop (e.g. as when the default help event
handler is executed).
- If an input matches a grammar from a <link> then that
link’s transition is executed, or its event is thrown. If
the <link> throws an event, the event is processed in the
context of the current form item (e.g. <initial>,
<field>, <transfer>, and so forth).
- If an input matches a grammar in a form other than the
current form, then the FIA terminates, the other form is
initialized, and that form’s FIA is started with this input
in its process phase.
If an input matches a grammar in this form, then:
- The input’s grammar slot values are assigned to the
corresponding field item variables.
- The <filled> actions triggered by these assignments are
identified as described in Section
2.4.
- Each identified <filled> action is executed in document
order. If a <submit>, <disconnect>, <exit>,
<return>, <goto> or <throw> is encountered, the
remaining <filled> elements are not executed, and the FIA
either terminates or continues in the next main loop iteration.
<reprompt> does not terminate the FIA (the name suggests an
action), but rather just sets a flag that affects the treatment
of prompts on the subsequent iteration of the FIA. If an event is
thrown during the execution of a <filled>, event handler
selection starts in the scope of the <filled>, which could
be a form item or the form itself, and then proceeds outward by
enclosing dialog scopes.
After completion of the process phase, interpretation
continues by returning to the select phase.
A more detailed form interpretation algorithm can be found in
Appendix C.
A menu is a convenient syntactic shorthand for a form
containing a single anonymous field that prompts the user to make
a choice and transitions to different places based on that
choice. Like a regular form, it can have its grammar scoped such
that it is active when the user is executing another dialog. The
following menu offers the user three choices:
<menu>
<prompt>
Welcome home. Say one of: <enumerate/>
</prompt>
<choice next="http://www.sports.example.com/vxml/start.vxml">
Sports
</choice>
<choice next="http://www.weather.example.com/intro.vxml">
Weather
</choice>
<choice next="http://www.stargazer.example.com/voice/astronews.vxml">
Stargazer astrophysics news
</choice>
<noinput>Please say one of <enumerate/></noinput>
</menu>
This dialog might proceed as follows:
C: Welcome home. Say one of: sports; weather; Stargazer
astrophysics news.
H: Astrology.
C: I did not understand what you said. (a
platform-specific default message.)
C: Welcome home. Say one of: sports; weather; Stargazer
astrophysics news.
H: sports.
C: (proceeds to
http://www.sports.example.com/vxml/start.vxml)
This identifies the menu, and determines the scope of its
grammars. Menu attributes are:
| id |
The identifier of the menu. It allows the menu to be the
target of a <goto> or a <submit>. |
| scope |
The menu’s grammar scope. If it is dialog – the
default – the menu’s grammars are only active when
the user transitions into the menu. If the scope is document, its
grammars are active over the whole document (or if the menu is in
the application root document, any loaded document in the
application). |
| dtmf |
When set to true, any choices that do not have explicit DTMF
elements are given the implicit ones "1", "2", etc. |
| accept |
When set to "exact" (the default), the text of the choice
elements in the menu defines the exact phrase to be recognized.
When set to "approximate", the text of the choice elements
defines an approximate recognition phrase (as described under grammar generation). Each <choice> can
override this setting. |
Choice element
The <choice> element serves several purposes:
-
It specifies a speech grammar fragment and/or a DTMF grammar
fragment that determines when that choice has been selected.
-
The contents are used to form the <enumerate> prompt
string.
-
It specifies the URI to go to when the choice is selected.
Choice attributes are:
| dtmf |
The DTMF sequence for this choice. |
| accept |
Override the setting for accept in <menu> for this
particular choice. When set to "exact" (the default), the text of
the choice element defines the exact phrase to be recognized.
When set to "approximate", the text of the choice element defines
an approximate recognition phrase (as described under grammar generation). |
| next |
The URI of next dialog or document. |
| event |
Specify an event to be thrown instead of specifying a next.
The 'next' and 'expr' attributes have precedence over the 'event'
attribute. |
| expr |
Specify an expression to evaluate as a URI to transition to
instead of specifying a next. The 'next' attribute has precedence
over the 'expr' attribute. |
| fetchaudio |
See Section 6.1. This defaults to the
fetchaudio property. |
| fetchhint |
See Section 6.1. This defaults to the
documentfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
documentmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
documentmaxstale property. |
If a <grammar> element is specified in <choice>,
then the external grammar is used instead of an automatically
generated grammar. This allows the developer to precisely control
the <choice> grammar; for example:
<menu>
<choice next="http://www.sports.example.com/vxml/start.vxml">
<grammar src="sports.grxml" type="application/grammar+xml"/>
Sports
</choice>
<choice next="http://www.weather.example.com/intro.vxml">
<grammar src="weather.grxml" type="application/grammar+xml"/>
Weather
</choice>
<choice next="http://www.stargazer.example.com/voice/astronews.vxml">
<grammar src="astronews.grxml" type="application/grammar+xml"/>
Stargazer astrphysics
</choice>
</menu>
DTMF in Menus
Menus can rely purely on speech, purely on DTMF, or both in
combination by including a <property> element in the
<menu>. Here is a DTMF-only menu with explicit DTMF
sequences given to each choice, using the choice’s dtmf
attribute:
<menu>
<property name="inputmodes" value="dtmf"/>
<prompt>
For sports press 1, For weather press 2, For Stargazer
astrophysics press 3.
</prompt>
<choice dtmf="1" next="http://www.sports.example.com/vxml/start.vxml"/>
<choice dtmf="2" next="http://www.weather.example.com/intro.vxml"/>
<choice dtmf="3" next="http://www.stargazer.example.com/astronews.vxml"/>
</menu>
Alternatively, you can set the <menu>’s dtmf
attribute to true to assign sequential DTMF digits to each of the
first nine choices: the first choice has DTMF "1", and so on:
<menu dtmf="true">
<property name="inputmodes" value="dtmf"/>
<prompt>
For sports press 1, For weather
press 2, For Stargazer astrophysics press 3.
</prompt>
<choice next="http://www.sports.example.com/vxml/start.vxml"/>
<choice next="http://www.weather.example.com/intro.vxml"/>
<choice
next="http://www.stargazer.example.com/voice/astronews.vxml"/>
</menu>
Enumerate element
The <enumerate> element is an automatically generated
description of the choices available to the user. It specifies a
template that is applied to each choice in the order they appear
in the menu. If it is used with no content, a default template
that lists all the choices is used, determined by the interpreter
context. If it has content, the content is the template
specifier. This specifier may refer to two special variables:
_prompt is the choice’s prompt, and _dtmf is the
choice’s assigned DTMF sequence. For example, if the menu
were rewritten as
<menu dtmf="true">
<prompt>
Welcome home.
<enumerate>
For <value expr="_prompt"/>, press <value
expr="_dtmf"/>.
</enumerate>
</prompt>
<choice next="http://www.sports.example.com/vxml/start.vxml">
sports </choice>
<choice next="http://www.weather.example.com/intro.vxml">
weather </choice>
<choice next="http://www.stargazer.example.com/voice/astronews.vxml">
Stargazer astrophysics news
</choice>
</menu>
then the menu’s prompt would be:
C: Welcome home. For sports, press 1. For weather, press 2.
For Stargazer astrophysics news, press 3.
The <enumerate> element may be used within the prompts
and the catch elements associated with <menu> elements and
with <field> elements that contain <option> elements,
as discussed in Section 2.3.1.3. An
error.semantic event is thrown if <enumerate> is used
elsewhere.
Any choice phrase specifies a set of words and phrases
to listen for. A choice phrase is constructed from the PCDATA of
the elements contained directly or indirectly in the
<choice> element.
If the accept attribute is "exact" then the user must say the
entire phrase in the same order in which they occur in the choice
phrase.
If the accept attribute is "approximate", then the choice may
be matched when a user says a subphrase of the expression. For
example, in response to the prompt "Stargazer astrophysics news"
a user could say "Stargazer", "astrophysics", "Stargazer news",
"astrophysics news", and so on. The equivalent grammar may be
language and platform dependent.
As an example of using "exact" and "approximate" in different
choices, consider this example:
<menu accept="approximate">
<choice next="..."> Stargazer Astrophysics News </choice>
<choice accept="exact" next="..."> Physics Weekly </choice>
<choice accept="exact" next="..."> Particle Physics Update </choice>
<choice next="..."> Astronomy Today </choice>
</menu>
Because "approximate" is specified for the first choice, the
user may say a subphrase when matching the first choice; for
instance, "Stargazer" or "Astrophysics News". However, because
"exact" is specified in the second and third choices, only a
complete phrase will match: "Physics Weekly" and "Partical
Physics Update".
As an example of the use of PCDATA contained in descendants of
the <choice> element, consider the following example:
<choice accept="exact"
next="http://www.stargazer.example.com/voice/astronews.vxml">
<audio src="http://www.stargazer.example.com/space.wav">
Stargazer <emphasis>astrophysics</emphasis> news
</audio>
</choice>
This choice would be read from the audio file, or as
"Stargazer Astrophysics News" if the file could not be
played. The grammar for the choice would be the exact phrase
"Stargazer astrophysics news" gleaned from the PCDATA of the
<choice> element’s descendants.
Interpretation model
A menu behaves like a form with a single field that does all
the work. The menu prompts become field prompts. The menu event
handlers become the field event handlers. The menu grammars
become form grammars.
Upon entry, the menu’s grammars are built and enabled,
and the prompt is played. When the user input matches a choice,
control transitions according to the value of the next, expr, or
event attribute of the <choice>, only one of which may be
specified. If an event attribute is specified but its event
handler does not cause the interpreter to exit or transition
control, then the FIA will clear the form item variable of the
menu's anonymous field, causing the menu to be executed
again.
A form item is an element of a <form> that can be
visited during form interpretation. They include <field>,
<block>, <initial>, <subdialog>,
<object>, <record>, and <transfer>.
All form items have the following characteristics:
-
They have a result variable, specified by the name attribute.
This variable may be given an initial value with the expr
attribute.
-
They have a guard condition specified with the cond
attribute.
-
Form items are subdivided into field items, those that
define the form’s field item variables, and control
items, those that help control the gathering of the
form’s fields. Field items (<field>,
<subdialog>, <object>, <record>, and
<transfer>) generally may contain the following
elements:
-
<filled> elements containing some action to execute at
the moment the result field is filled in.
-
<property> elements to specify properties that are in
effect for this field item.
-
<prompt> elements to specify prompts to be played when
this field is visited.
-
<grammar> elements to specify allowable spoken and
character input for this field item.
-
<catch> elements and catch shorthands that are in effect
for this field item.
Each field item may have an associated set of shadow
variables. Shadow variables are used to return results from
the execution of a field item, other than the value stored under
the name attribute. For example, it may be useful to know the
confidence level that was obtained as a result of a recognized
grammar in a <field> element. A shadow variable is
referenced as name$.shadowvar where name is
the value of the field item’s name attribute, and
shadowvar is the name of a specific shadow variable. For
example, the <field> element returns a shadow variable
confidence. The code fragment below illustrates how this shadow
variable is accessed.
<field name="state">
<prompt> Please say the name of a state. </prompt>
<grammar src="http://mygrammars.example.com/states.grm"
type="application/grammar"/>
<filled>
<if cond="state$.confidence < 0.4">
<throw event="nomatch"/>
</if>
</filled>
</field>
In the example, the confidence of the result is examined, and
the result is rejected if the confidence is too low.
A field specifies an input item to be gathered from the user.
Attributes of fields include:
| name |
The field item variable in the dialog scope that will hold
the result. The name must be a unique variable name within the
scope of the form. If the name is not unique, then a badfetch
error is thrown when the document is fetched. The name must
conform to the variable naming conventions in Section 5.1. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
| type |
The type of field, i.e., the name of an internal grammar.
This name must be from a standard set supported by all conformant
platforms. If not present, <grammar> elements can be
specified instead. |
| slot |
The name of the grammar slot used to populate the variable
(if it is absent, it defaults to the variable name). This
attribute is useful in the case where the grammar format being
used has a mechanism for returning sets of slot/value pairs and
the slot names differ from the field item variable names. If the
grammar returns only one slot, as do the builtin type grammars
like boolean, then no matter what the slot’s name, the
field item variable gets the value of that slot. |
| modal |
If this is false (the default) all active grammars are turned
on while collecting this field. If this is true, then only the
field’s grammars are enabled: all others are temporarily
disabled. |
The shadow variables of a <field> element whose name is
name are the same used in the application.lastresult$
array, name$.confidence, name$.utterance,
name$.inputmode, and name$.interpretation. The
value of each of these shadow variables will necessarily be the
same as that found in first element of the array:
application.lastresult$[0].confidence,
application.lastresult$[0].utterance,
application.lastresult$[0].inputmode, and
application.lastresult$[0].interpretation, respectively. See Section 5.1.5 for a description of the
contents of these variables.
Issues:
- The definition for precedence of grammars in Section 3.1.5
may, in certain circumstances, conflict with the requirement
above that 0th entry in the n-best provide the contents of a
field's shadow variables. A future working draft will resolve
this conflict.
The <field> type attribute is used to specify a builtin
grammar for one of the fundamental types, and also specifies how
its value is to be spoken if subsequently used in a value
attribute in a prompt. An example:
<field name="lo_fat_meal" type="boolean">
<prompt>
Do you want a low fat meal on this flight?
</prompt>
<help>
Low fat means less than 10 grams of fat, and under
250 calories.
</help>
<filled>
<prompt>
I heard <emphasis><value expr="lo_fat_meal"/></emphasis>.
</prompt>
</filled>
</field>
In this example, the boolean type indicates that inputs are
various forms of true and false. The value actually put into the
field is either true or false. The field would be read "yes" or
"no" in prompts.
In the next example, digits indicates that input will be
spoken or keyed digits. The result is stored as a string, and
rendered as digits, i.e., "one-two-three", not "one hundred
twenty-three". The <filled> action tests the field to see
if it has 12 digits. If not, the user hears the error
message.
<field
name="ticket_num" type="digits">
<prompt>
Read the 12 digit number from your ticket.
</prompt>
<help>The 12 digit number is to the lower left.</help>
<filled>
<if cond="ticket_num.length != 12">
<prompt>
Sorry, I didn't hear exactly 12 digits.
</prompt>
<assign name="ticket_num" expr="undefined"/>
</if>
</filled>
</field>
Each builtin type has a convention for the format of the value
returned. These are independent of locale and of the
implementation. The return type for builtin fields is string
except for the boolean field type. To access the actual
recognition result, the author can reference the shadow variable
name$.utterance.
The builtin types are defined in such a way that a VoiceXML
application developer can assume some consistency of user input
across implementations. This permits help messages and other
prompts to be independent of platform in many instances. For
example, the boolean type’s grammar should minimally allow
"yes" and "no" responses, but each implementation is free to add
other choices, such as "yeah" and "nope".
In cases where an application requires specific behavior or
different behavior than defined for a builtin, it should use an
explicit field grammar. The following are circumstances in which
an application must provide an explicit field grammar in order to
ensure portability of the application with a consistent user
interface
A platform is not required to implement a grammar that accepts
all possible values that might be returned by a builtin. For
instance, the currency builtin defines the return value
formatting for a very broad range of currencies (by reference to
ISO 4217:1995). The platform is not required to support spoken
input that includes any of the world's currencies since that can
negatively impact recognition accuracy. Similarly, the number
builtin can return positive or negative floating point numbers
but the grammar is not required to support all possible spoken
floating point numbers.
Builtins are also limited in their ability to handle
underspecified spoken input. For instance, "20 peso" cannot be
resolved to a specific ISO 4217:1995 currency code because the
"peso" is the name of the currency of numerous nations. In such
cases the platform may return a specific currency code according
to the locale or may omit the currency code.
All builtin types must support both voice and DTMF entry.
The builtin types are:
| boolean |
Inputs include affirmative and negative phrases appropriate
to the current locale. DTMF 1 is yes and 2 is no. The result is
ECMAScript true for "yes" or false for "no". The value will be
submitted as the string "true" or the string "false". If the
field value is subsequently used in a prompt, it will be spoken
as an affirmative or negative phrase appropriate to the current
locale. |
| date |
Valid spoken inputs include phrases that specify a date,
including a month day and year. DTMF inputs are: four digits for
the year, followed by two digits for the month, and two digits
for the day. The result is a fixed-length date string with format
yyyymmdd, e.g. "20000704". If the year is not specified, yyyy is
returned as "????"; if the month is not specified mm is returned
as "??"; and if the day is not specified dd is returned as "??".
The set of accepted spoken date formats is platform dependent and
may vary by locale. |
| digits |
Valid spoken or DTMF inputs include one or more digits, 0
through 9. The result is a string of digits. If the field value
is subsequently used in a prompt, it will be spoken as a sequence
of digits. A user can say for example "two one two seven", but
not "twenty one hundred and twenty-seven". A platform may support
constructs such as "two double-five eight". |
| currency |
Valid spoken inputs include phrases that specify a currency
amount. For DTMF input, the "*" key will act as the decimal
point. The result is a string with the format UUUmm.nn, where UUU
is the three character currency indicator according to ISO
standard 4217:1995, or mm.nn if the currency is not spoken by the
user or if the currency cannot be reliably determined (e.g.
"dollar" and "peso" are ambiguous). If the field value is
subsequently used in a prompt, it will be spoken as a currency
amount appropriate to the current locale. The set of accepted
spoken currency formats is platform dependent and may vary by
locale. |
| number |
Valid spoken inputs include phrases that specify numbers,
such as "one hundred twenty-three", or "five point three". Valid
DTMF input includes positive numbers entered using digits and "*"
to represent a decimal point. The result is a string of digits
from 0 to 9 and may optionally include a decimal point (".")
and/or a plus or minus sign. ECMAScript automatically converts
result strings to numerical values when used in numerical
expressions. The result must not use a leading zero (which would
cause ECMAScript to interpret as an octal number). The set of
accepted spoken number formats is platform dependent and may vary
by locale. |
| phone |
Valid spoken inputs include phrases that specify a phone
number. DTMF asterisk "*" represents "x". The result is a string
containing a telephone number consisting of a string of digits
and optionally containing the character "x" to indicate a phone
number with an extension. For North America, a result could be
"8005551234x789". The range of accepted spoken phone formats is
platform dependent and may vary by locale. |
| time |
Valid spoken inputs include phrases that specify a time,
including hours and minutes. The result is a five character
string in the format hhmmx, where x is one of "a" for AM, "p" for
PM, "h" to indicate a time specified using 24 hour clock, or "?"
to indicate an ambiguous time. Input can be via DTMF. Because
there is no DTMF convention for specifying AM/PM, in the case of
DTMF input, the result will always end with "h" or "?". If the
field value is subsequently used in a prompt, the value will be
spoken as a time appropriate to the current locale. The set of
accepted spoken time formats is platform dependent and may vary
by locale. |
Explicit grammars can be specified via a URI, which can be
absolute or relative:
<field name="flavor">
<prompt>What is your favorite ice cream?</prompt>
<grammar src="../grammars/ice_cream.grxml"
type="application/grammar+xml"/>
</field>
Grammars can be specified inline, for example using a W3C
Augmented BNF grammar:
<field name="flavor">
<prompt>What is your favorite flavor?</prompt>
<help>Say one of vanilla, chocolate, or strawberry.</help>
<grammar type="application/grammar">
vanilla | chocolate | strawberry
</grammar>
</field>
If both the src attribute and an inline grammar are provided
the grammar identified by the src attribute takes precedence.
When a simple set of alternatives is all that is needed to
specify the legal input values for a field, it may be more
convenient to use an option list than a grammar. An option list
is represented by a set of <option> elements contained in a
<field> element. Each <option> element contains
PCDATA that is used to generate a grammar for the spoken input it
accepts using the same method described for <choice>. It
also has attributes specifying the DTMF key for selecting the
option and the value to assign to the field when the option is
chosen.
The following field offers the user three choices and assigns
the value of the value attribute of the selected option to the
maincourse variable:
<form>
<field name="maincourse">
<prompt>
Please select an entree. Today, we’re featuring <enumerate/>
</prompt>
<option dtmf="1" value="fish"> swordfish </option>
<option dtmf="2" value="beef"> roast beef </option>
<option dtmf="3" value="chicken"> frog legs </option>
<filled>
<submit next="/cgi-bin/maincourse.cgi"
method="post" namelist="maincourse"/>
</filled>
</field>
</form>
This conversation might sound like:
C: Please select an entree. Today, we’re featuring
swordfish; roast beef; frog legs.
H: frog legs
C: (assigns "chicken" to "maincourse",
then submits "maincourse=chicken" to /maincourse.cgi)
The following example shows proper and improper use of
<enumerate> in a catch element of a form with several
fields containing <option> elements:
<form>
<block>
We need a few more details to complete your order.
</block>
<field name="color">
<prompt>Which color?</prompt>
<option>red</option>
<option>blue</option>
<option>green</option>
</field>
<field name="size">
<prompt>Which size?</prompt>
<option>small</option>
<option>medium</option>
<option>large</option>
</field>
<field name="quantity" type="number">
<prompt>How many?</prompt>
</field>
<block>
Thank you. Your order is being processed.
<submit next="details.cgi"/>
</block>
<catch event="help nomatch">
Your options are <enumerate/>.
</catch>
</form>
A scenario might be:
C: We need a few more details to complete your order. Which
color?
H: help. (throws "help" event caught by form-level
<catch>)
C: Your options are red, blue, green.
H: red.
C: Which size?
H: 7 (throws "nomatch" event caught by form-level
<catch>)
C: Your options are small, medium, large.
H: small.
In the steps above, the <enumerate/> in the form-level
catch had something to enumerate: the <option> elements in
the "color" and "size" <field> elements. The next
<field>, however, is different:
C: How many?
H: a lot. (throws "nomatch" event caught by form-level
<catch>)
The form-level <catch>'s use of <enumerate> causes
an "error.semantic" event to be thrown because the "quantity"
<field> does not contain any <option> elements that
can be enumerated.
One solution is to add a field-level <catch> to the
"quantity" <field>:
<catch event="help nomatch">
Please say the number of items to be ordered.
</catch>
The "nomatch" event would then be caught locally, resulting in
the following possible completion of the scenario:
C: Please say the number of items to be ordered.
H: 50
C: Thank you. Your order is being processed.
The <enumerate> element is also discussed in Section 2.2.
The attributes of <option> are:
| dtmf |
The DTMF sequence for this option. |
| value |
The string to assign to the field item variable when a user
selects this option, whether by speech or DTMF. If a DTMF
sequence is specified, but not value or CDATA, then the field
variable is assigned the DTMF sequence. The default assignment is
the CDATA content of the <option> element with leading and
trailing white space removed. |
The use of <option> does not preclude the simultaneous
use of <grammar>. The result would be the match from either
'grammar', not unlike the occurence of two <grammar>
elements in the same <field> representing a disjunction of
choices.
Fundamental builtin grammars are explicitly referenced using
the special-purpose "builtin:" URI scheme which allows access to
resources such as speech grammars, DTMF grammars and audio files.
In addition, the "builtin:" URI scheme may also be used to access
platform-specific builtin grammars that are supported by
particular interpreter contexts. It is recommended that
plaform-specific builtin grammar names begin with the string
"x-", as this namespace will not be used in future versions of
the standard.
Examples of fundamental builtin grammars:
<grammar src="builtin:grammar/boolean"/>
<grammar src="builtin:dtmf/boolean"/>
where the first <grammar> references the builtin boolean
speech grammar, and the second references the builtin boolean
DTMF grammar.
Examples of platform-specific builtin grammars:
<grammar src="builtin:grammar/x-sample"/>
<grammar src="builtin:dtmf/x-sample"/>
Some builtin field types and grammars can be parameterized.
This may be done by explicitly referring to builtin grammars
using the special-purpose "builtin:" URI scheme and a URI-style
query syntax of the form type?param=value in
the src attribute of a <grammar> element, or in the type
attribute of a field, for example:
<grammar src="builtin:dtmf/boolean?y=7;n=9"/>
<field type="boolean?y=7;n=9>...</field>
<field type="digits?minlength=3;maxlength=5">...</field>
Where the <grammar> parameterizes the builtin DTMF
grammar, the first <field> parameterizes the builtin DTMF
grammar (the speech grammar will be activated as normal) and the
second <field> parameterizes both builtin DTMF and speech
grammars. Parameters which are undefined for a given grammar type
will be ignored; for example, "builtin:grammar/boolean?y=7".
By definition the following:
<field type="sample">...</field>
is equivalent to:
<field>
<grammar src="builtin:grammar/sample"/>
<grammar src="builtin:dtmf/sample"/>
...
</field>
where sample is one of the fundamental builtin field
types (e.g., boolean, date, etc.). The digits and boolean
grammars can be parameterized as follows:
| digits?minlength=n |
A string of at least n digits. Applicable to speech
and DTMF grammars. If minlength conflicts with either the length
or maxlength attributes then a error.badfetch event is
thrown. |
| digits?maxlength=n |
A string of at most n digits. Applicable to speech and
DTMF grammars. If maxlength conflicts with either the length or
minlength attributes then a error.badfetch event is thrown. |
| digits?length=n |
A string of exactly n digits. Applicable to speech and
DTMF grammars. If length conflicts with either the minlength or
maxlength attributes then a error.badfetch event is thrown. |
| boolean?y=d |
A grammar that treats the keypress d as an affirmative
answer. Applicable only to the DTMF grammar. |
| boolean?n=d |
A grammar that treats the keypress d as a negative
answer. Applicable only to the DTMF grammar. |
Note that more than one parameter may be specified separated
by ";" as illustrated above. In <grammar> elements, the src
attribute URI must start with builtin:grammar/ or builtin:dtmf/
as shown above. When a <grammar> element with the mode set
to "voice" (the default value) is specified in a <field>,
it overrides the default speech grammar implied by the type
attribute of the field. Likewise, when a <grammar> element
with the mode set to "dtmf" is specified in a <field>, it
overrides the default DTMF grammar.
This element is a form item. It contains executable content
that is executed if the block’s form item variable is
undefined and the block's cond attribute, if any, evaluates to
true.
<block>
Welcome to Flamingo, your source for lawn ornaments.
</block>
The form item variable is automatically set to true just
before the block is entered. Therefore, blocks are typically
executed just once per form invocation.
Sometimes you may need more control over blocks. To do this,
you can name the form item variable, and set or clear it to
control execution of the <block>. This variable is declared
in the dialog scope of the form.
Attributes of <block> include:
| name |
The name of the form item variable used to track whether this
block is eligible to be executed; defaults to an inaccessible
internal variable. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
In a typical mixed initiative form, the <initial>
element is visited when the user is initially being prompted for
form-wide information, and has not yet entered into the directed
mode where each field is solicited individually. Like field
items, it has prompts, catches, and event counters. Unlike field
items, <initial> has no grammars, and no <filled>
action. For instance:
<form id="get_from_and_to_cities">
<grammar src="http://www.directions.example.com/grammars/from_to.grxml"
type="application/grammar+xml"/>
<block>
Welcome to the Driving Directions By Phone.
</block>
<initial name="bypass_init">
<prompt>
Where do you want to drive from and to?
</prompt>
<nomatch count="1">
Please say something like "from Atlanta Georgia to Toledo Ohio".
</nomatch>
<nomatch count="2">
I'm sorry, I still don't understand.
I'll ask you for information one piece at a time.
<assign name="bypass_init" expr="true"/>
<reprompt/>
</nomatch>
</initial>
<field name="from_city">
<grammar src="http://www.directions.example.com/grammars/city.grxml"
type="application/grammar+xml"/>
<prompt>From which city are you leaving?</prompt>
... etc. ...
</field>
... etc. ...
</form>
While visiting an <initial> element, no field grammar is
active. If an event occurs while visiting an <initial>,
then one of its event handlers executes. As with other form
items, <initial> continues to be eligible to be visited
while its form item variable is undefined and while its cond
attribute is true. If one or more of the field item variables is
set by user input, then all <initial> form item variables
are set to true, before any <filled> actions are
executed.
An <initial> form item variable can be manipulated
explicitly to disable, or re-enable the <initial>'s
eligibility to the FIA. For example, in the program above, the
<initial>'s form item variable is set on the second nomatch
event. This causes the FIA to no longer consider the
<initial> and to choose the next form item, which is a
<field> to prompt explicitly for the origination city.
Similarly, an <initial>’s form item variable could be
cleared, so that <initial> gets selected again by the
FIA.
Note: explicit assignment of values to field item variables
does not affect the value of an <initial>’s form item
variable.
Attributes of <initial> include:
| name |
The name of a form item variable used to track whether the
<initial> is eligible to execute; defaults to an
inaccessible internal variable. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
A <subdialog> element invokes a 'called' dialog (known
as the subdialog) identified by its src attribute in the
'calling' dialog. The subdialog executes in a new execution
context that includes all the declarations and state information
for the dialog, the dialog’s document, and the application
root (if present), with counters reset, and variables
initialized. The subdialog proceeds until the execution of a
<return> element which causes the subdialog to return. When
the subdialog returns, its execution context is deleted, and
execution resumes in the calling dialog with any appropriate
<filled> elements.
The subdialog context and the context of the callee dialog are
independent, even if the dialogs are in the same document.
Variables in the scope chain of the calling dialog are not shared
with the called subdialog: there is no sharing of variable
instances between execution contexts. Even when the subdialog is
specified in the same document as the calling dialog, its
execution context contains different variable instances. When the
subdialog and calling dialog are in different documents but share
a root document, the subdialog's root variables are likewise
different instances. All variable bindings applied in the
subdialog context are lost on return to the calling context.
Within the subdialog context, however, normal scoping rules
for grammars, events and variables apply. Active grammars in a
subdialog include default grammars defined by the interpreter
context and appropriately scoped grammars in <link>,
<menu> and <form> elements in the subdialog's
document and its root document. Event handling and variable
binding likewise follow the standard scoping hierarchy.
From a programming perspective, subdialogs behave differently
from subroutines because the calling and called contexts are
independent. While a subroutine can access variable instances in
its calling routine, a subdialog cannot access the same variable
instance defined in its calling dialog. Similarly, subdialogs do
not follow the event percolation model in languages like Java
where an event thrown in a subrountine automatically percolates
up to the calling context if not handled in the called context.
Events thrown in a subdialog are treated by event handlers
defined within its context; they can only be passed to the
calling context by a local event handler which explicitly returns
the event to the calling context (see Section 5.3.10).
Subdialogs can permit the reuse of a common dialog and can be
used to build libraries of reusable applications.
The attributes are:
| name |
The result returned from the subdialog, an ECMAScript object
whose properties are the ones defined in the namelist attribute
of the <return> element. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
| namelist |
Same as namelist in <submit>, except that the default
is to submit nothing. Only valid when fetching another
document. |
| src |
The URI of the <subdialog>. |
| method |
See Section 5.3.8. |
| enctype |
See Section 5.3.8. |
| fetchaudio |
See Section 6.1. This defaults to the
fetchaudio property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| fetchhint |
See Section 6.1. This defaults to the
documentfetchhint property |
| maxage |
See Section 6.1. This defaults to the
documentmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
documentmaxstale property. |
The <subdialog> element may contain elements common to
all form items, and may also contain <param> elements. The
<param> elements of a <subdialog> specify the
parameters to pass to the subdialog. These parameters must be
declared in the subdialog using <var> elements; it is a
semantic error to attempt to set a form item variable or an
undeclared variable using <param>. When a subdialog
initializes, its variables are initialized in document order to
the corresponding <param> value. An expr attribute in the
<var> element is ignored in this case. If no corresponding
<param> is specified to <var> element, an expr
attribute is used as a default value, or the variable is
undefined if the expr attribute is unspecified as with the
regular <form> element.
In the example below, the birthday of an individual is used to
validate their driver's license. The src attribute of the
subdialog refers to a form that is within the same document. The
<param> element is used to pass the birthday value to the
subdialog.
<!-- form dialog that calls a subdialog -->
<form>
<subdialog name="result" src="#getdriverslicense">
<param name="birthday" expr="'2000-02-10'"/>
<filled>
<submit next="http://myservice.example.com/cgi-bin/process"/>
</filled>
</subdialog>
</form>
<!-- subdialog to get drivers license -->
<form id="getdriverslicense">
<var name="birthday"/>
<field name="drivelicense">
<grammar src="http://grammarlib/drivegrammar.grxml"
type="application/grammar+xml"/>
<prompt> Please say your driver's license. </prompt>
<filled>
<if cond="validdrivelicense(drivelicense,birthday)">
<var name="status" expr="true"/>
<else/>
<var name="status" expr="false"/>
</if>
<return namelist="drivelicense status"/>
</filled>
</field>
</form>
The driver’s license value is returned to calling
dialog, along with a status variable in order to indicate whether
the license is valid or not.
This example also illustrates the convenience of using
<param> as a means for forwarding data to the subdialog as
a means of instantiating values in the subdialog without using
server side scripting. An alternate solution that uses scripting,
is shown below.
Document with form that calls a subdialog
<?xml
version="1.0"?>
<vxml version="2.0">
<form>
<field name="birthday" type="date">
What is your birthday?
</field>
<subdialog name="result"
src="/cgi-bin/getlib#getdriverslicense"
namelist="birthday">
<filled>
<submit next="http://myservice.example.com/cgi-bin/process"/>
</filled>
</subdialog>
</form>
</vxml>
Document containing the subdialog
(generated by /cgi-bin/getlib)
<?xml version="1.0"?>
<vxml version="2.0">
<form id="getdriverlicense">
<var name="birthday" expr="'1980-02-10'"/>
<!-- Generated by server script -->
<field name="drivelicense">
<grammar src="http://grammarlib/drivegrammar.grxml"
type="application/grammar+xml"/>
<prompt>
Please say your driver’s license number.
</prompt>
<filled>
<if cond="validdrivelicense(drivelicense,birthday)">
<var name="status" expr="true"/>
<else/>
<var name="status" expr="false"/>
</if>
<return namelist="drivelicense status"/>
</filled>
</field>
</form>
</vxml>
In the above example, a server side script had to generate the
document and embed the birthday value.
One last example is shown below that illustrates a subdialog
to capture general credit card information. First the subdialog
is defined in a separate document; it is intended to be reusable
across different applications. It returns a status, the credit
card number, and the expiry date; if a result cannot be obtained,
the status is returned with value "no_result".
<?xml version="1.0"?>
<vxml version="2.0">
<!-- Example of subdialog to collect credit card information. -->
<!-- file is at http://www.somedomain.example.com/ccn.vxml -->
<form id="getcredit">
<var name="status" expr="'no_result'"/>
<field name="creditcardnum">
<prompt>
What is your credit card number?
</prompt>
<help>
I am trying to collect your credit card information.
<reprompt/>
</help>
<nomatch>
<return namelist="status"/>
</nomatch>
<grammar src="ccn.grxml" type="application/grammar+xml"/>
</field>
<field name="expirydate" type="date">
<prompt>
What is the expiry date of this card?
</prompt>
<help>
I am trying to collect the expiry date of the credit
card number you provided.
<reprompt/>
</help>
<nomatch>
<return namelist="status"/>
</nomatch>
</field>
<block>
<assign name="status" expr="'result'"/>
<return namelist="status creditcardnum expirydate"/>
</block>
</form>
</vxml>
An application that includes a calling dialog is shown below.
It obtains the name of a software product and operating system
using a mixed initiative dialog, and then solicits credit card
information using the subdialog.
<?xml version="1.0"?>
<vxml version="2.0">
<!-- Example main program -->
<!-- http://www.somedomain.example.com/main.vxml -->
<!-- calls subdialog ccn.vxml -->
<!-- assume this gets defined by some dialog -->
<var name="username"/>
<form id="buysoftware">
<var name="ccn"/>
<var name="exp"/>
<grammar src="buysoftware.grxml" type="application/grammar+xml"/>
<initial name="start">
<prompt>
Please tell us the software product you wish to buy
and the operating system on which it must run.
</prompt>
<noinput>
<assign name="start" expr="true"/>
</noinput>
</initial>
<field name="product">
<prompt>
Which software product would you like to buy?
</prompt>
</field>
<field name="operatingsystem">
<prompt>
Which operating system does this software need to run on?
</prompt>
</field>
<subdialog name="cc_results"
src="http://somedomain.example.com/ccn.vxml">
<filled>
<if cond="cc_results.status=='no_result'">
Sorry, your credit card information could not be
Obtained. This order is cancelled.
<exit/>
<else/>
<assign name="ccn" expr="cc_results.creditcardnum"/>
<assign name="exp" expr="cc_results.expirydate"/>
</if>
</filled>
</subdialog>
<block>
We will now process your order. Please hold.
<submit next="www.somedomain.example.com/process_order.asp"
namelist="username product operatingsystem ccn exp"/>
</block>
</form>
</vxml>
A VoiceXML implementation platform may expose
platform-specific functionality for use by a VoiceXML application
via the <object> element. The <object> element makes
direct use of its own content during initialization (e.g.
<param> child element) and execution. As a result,
<object> content cannot be treated as alternative
content.
For example, a platform-specifc credit card collection object
could be accessed like this:
<object
name="debit"
classid="method://credit_card/gather_and_debit"
data="http://www.recordings.example.com/prompts/credit/jesse.jar">
<param name="amount" expr="document.amt"/>
<param name="vendor" expr="vendor_num"/>
</object>
In this example, the <param> element (Section 6.4) is used to pass parameters to the
object when it is invoked. When this <object> is executed,
it returns an ECMAScript object as the value of its form item
variable. This <block> presents the values returned from
the credit card object:
<block>
<prompt>
The card type is <value expr="debit.card"/>.
</prompt>
<prompt>
The card number is <value expr="debit.card_no"/>.
</prompt>
<prompt>
The expiration date is <value expr="debit.expiry_date"/>.
</prompt>
<prompt>
The approval code is <value expr="debit.approval_code"/>.
</prompt>
<prompt>The confirmation number is
<value expr="debit.conf_no"/>.
</prompt>
</block>
As another example, suppose that a platform has a feature that
allows the user to enter arbitrary text messages using a
telephone keypad.
<form id="gather_pager_message">
<object name="message"
classid="builtin://keypad_text_input">
<prompt>
Enter your message by pressing your keypad once
per letter. For a space, enter star. To end the
message, press the pound sign.
</prompt>
</object>
<block>
<assign name="document.pager_message" expr="message.text"/>
<goto next="#confirm_pager_message"/>
</block>
</form>
The user is first prompted for the pager message, then keys it
in. The <block> copies the message to the variable
document.pager_message.
Attributes of <object> include:
| name |
When the object is evaluated, it sets this variable to an
ECMAScript value whose type is defined by the object. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
| classid |
The URI specifying the location of the object’s
implementation. The URI conventions are platform-dependent. |
| codebase |
The base path used to resolve relative URIs specified by
classid, data, and archive. It defaults to the base URI of the
current document. |
| codetype |
The content type of data expected when downloading the object
specified by classid. When absent it defaults to the value of the
type attribute. |
| data |
The URI specifying the location of the object’s data.
If it is a relative URI, it is interpreted relative to the
codebase attribute. |
| type |
The content type of the data specified by the data
attribute. |
| archive |
A space-separated list of URIs for archives containing
resources relevant to the object, which may include the resources
specified by the classid and data attributes. URIs which are
relative are interpreted relative to the codebase
attribute.
|
| fetchhint |
See Section 6.1. This defaults to the
objectfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
objectmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
objectmaxstale property. |
If an <object> element refers to an unknown object, the
error.unsupported.object event is thrown. There is no requirement
for implementations to provide platform-specific objects,
although implementations must handle the <object> element
by throwing error.unsupported.object if the particular
platform-specific object is not supported.
The <record> element is a field item that collects a
recording from the user. A reference to the recorded audio is
stored in the field item variable, which can be played back
(using the expr attribute on either <value> or
<audio>) or submitted to a server, as shown in this
example:
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<record name="greeting" beep="true" maxtime="10s"
finalsilence="4000ms" dtmfterm="true" type="audio/wav">
<prompt>
At the tone, please say your greeting.
</prompt>
<noinput>
I didn't hear anything, please try again.
</noinput>
</record>
<field name="confirm" type="boolean">
<prompt>
Your greeting is <value expr="greeting"/>.
</prompt>
<prompt>
To keep it, say yes. To discard it, say no.
</prompt>
<filled>
<if cond="confirm">
<submit next="save_greeting.pl"
method="post" namelist="greeting"/>
</if>
<clear/>
</filled>
</field>
</form>
</vxml>
The user is prompted for a greeting and then records it. The
recording terminates when one of the following conditions is met:
the interval of final silence occurs, a DTMF key is pressed, the
maximum recording time is exceeded, or the caller hangs up. The
greeting is played back, and if the user approves it, is sent on
to the server for storage using the HTTP POST method. Notice that
like other field items, <record> has prompts and catch
elements. It may also have <filled> actions.
When a user hangs up during recording, the recording
terminates and a telephone.disconnect.hangup event is thrown.
However, audio recorded up until the hangup is available through
the <record> variable. Applications, such as simple
voicemail services, can then return audio data to a server even
afer disconnection:
<form>
<record name="voicemail">
...
<catch name="telephone.disconnect.hangup">
<submit next="./voicemail_server.asp"/>
</catch>
</record>
...
</form>
If the platform supports simultaneous recognition and
recording, then the local grammar may be used for termination of
the recording. The 'terminating' speech input is accessible via
the "utterance" shadow variable; its confidence via the
"confidence" shadow variable. The audio of the recognized
'terminating' speech input is not available and is not part of
the recording (as with DTMF termination). Form and document
scoped grammars may also be active while the recording is in
progress. If a form or document scoped grammar is matched,
recording is terminated, the record element is left unfilled, and
the form interpretation algorithm is invoked.
The attributes of <record> are:
| name |
The field item variable that will hold the recording. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
| modal |
If this is true (the default) all higher level speech and
DTMF grammars are turned off while making the recording. If this
is false, speech and DTMF grammars scoped to the form, document,
application, and calling documents are listened for. Most
implementations will not support simultaneous recognition and
recording. |
| beep |
If true, a tone is emitted just prior to recording. Defaults
to false. |
| maxtime |
The maximum duration to record. |
| finalsilence |
The interval of silence that indicates end of speech. |
| dtmfterm |
If true, a DTMF keypress terminates recording. Defaults to
true. The DTMF tone is not part of the recording. |
| type |
The media format of the resulting recording. Platforms must
support the audio file formats specified in Appendix E (other formats may also
be supported). Defaults to a platform-specific format which
should be one of the required formats. |
| dest |
The URI for the destination of the recording, for platforms
that may support storage of recording to streaming media or
messaging servers.
If the recording destination cannot be accessed for audio
playback and/or HTTP POST submit, error.semantic is thrown when
the recording field variable is referenced. |
The <record> shadow variable name$ has the
following ECMAScript properties after the recording has been
made:
- name$.duration
- The duration of the recording in milliseconds.
- name$.size
- The size of the recording in bytes.
- name$.termchar
- If the dtmfterm attribute is true, and the user terminates
the recording by pressing a DTMF key, then this shadow variable
is the key pressed (e.g. "#"). Otherwise it is null.
- name$.maxtime
- Boolean, true if the recording was terminated because the
maxtime duration was reached.
- name$.dest
- URI referencing the recording. If the destination redirects
the original request, for instance in the case of RTSP or HTTP
servers, this variable holds the redirected URI.
Issues:
- The mime type of the recording is not always sufficiently
specific to identify the precise audio encoding format; for
example, the "audio/wav" mime type does not identify the codec
used. RFC 2361
defines a method of referencing CODEC IDs in the Microsoft WAVE
registry, e.g. "audio/vnd.wave; codec=123". A future revision of
this document may include an attribute which specifies the
precise encoding.
Occasionally, it is appropriate to suspend the session between
the user and the interpreter and initiate a session with another
entity. The most common use for this capability in current
practice is to connect a user in a telephone conversation with an
interpreter to a third party through the telephone network. The
<transfer> element directs the interpreter to make such a
third party connection. Two scenarios are supported:
| bridge transfer |
The interpreter remains connected to the call; the original
caller resumes his session with the interpreter after the far end
disconnects. |
| blind transfer |
No resumption is possible; as soon as the call connects, the
platform throws a telephone.disconnect.transfer. The interpreter
disconnects from the session and continues execution (if anything
remains to execute) but cannot regain control of the call. The
caller and callee remain connected in a conversation. |
The form item variable is used to store the outcome of the
transfer attempt. In the case of a blind transfer, the value of
the form item variable is undefined. The possible values for
bridge transfers are:
| busy |
The endpoint refused the call. |
| noanswer |
There was no answer within the time specified by the
connecttimeout attribute. |
| network_busy |
Some intermediate network refused the call. |
| near_end_disconnect |
The call completed and was terminated by the caller. |
| far_end_disconnect |
The call completed and was terminated by the callee. |
| network_disconnect |
The call completed and was terminated by the network. |
| maxtime_disconnect |
The call duration exceeded the value of maxtime attribute and
was terminated by the platform. |
| unknown |
This value may be returned if the outcome of the transfer is
unknown, for instance if the platform does not support reporting
the outcome of blind transfer completion. |
The following example attempts to transfer the user to a
customer support operator and then wait for that conversation to
terminate. An audio file is played before actually performing the
transfer; this is useful in cases where the it is desired to
inform the caller of what is happening, with a notice such as
"Please wait while we transfer your call". After the audio play
completes, the transfer begins. The caller is connected to the
outgoing telephony channel. They will hear the audio from the far
end (including call progress tones such as ringing, busy, network
busy, etc.) The "transferaudio" attribute specifies an audio file
to be played to the caller in place of audio from the far end
until the far end answers. The audio will stop playing
immediately upon far-end answer. If the audio file ends before
the far-end answers, the caller will be connected to the far-end
audio (thus hearing call progress tones).
<form id="xfer">
<var name="mydur" expr="0"/>
<block>
<prompt>
<!-- queue and played before starting the transfer -->
<!-- "Please wait while we transfer your call..." -->
<audio src="please_wait.wav">
</prompt>
</block>
<!-- play elevator music while ringing;
wait up to 60 seconds for the far end to answer -->
<transfer name="mycall" dest="tel:+358-555-1234567"
transferaudio="elevator_music.wav"
connecttimeout="60s" bridge="true">
<filled>
<assign name="mydur" expr="mycall$.duration"/>
<if cond="mycall == 'busy'">
<prompt>
Sorry, our customer support team is busy serving
other customers. Please try again later.
</prompt>
<elseif cond="mycall == 'noanswer'"/>
<prompt>
Sorry, our customer support team's normal hours
are 9 am to 7 pm Monday through Saturday.
</prompt>
</if>
</filled>
</transfer>
<block>
<submit namelist="mycall mydur" next="/cgi-bin/report"/>
</block>
</form>
During a bridge transfer, the platform can listen for DTMF and
voice input from the caller. In particular, if a DTMF grammar
appears inside the <transfer> element, DTMF input matching
that grammar will terminate the transfer and return control to
the interpreter. Similarly, a bridge transfer may be terminated
by recognition of an utterance matching an enclosed
<grammar> element; support for speech recognition during
transfer is not required. The <transfer> element is modal
in that no grammar defined outside its scope is active. When
transfer is terminated by DTMF or speech, a near_end_disconnect
value is returned.
As is the case with other field items, <prompt> elements
within <transfer> are queued and played before the transfer
begins.
A <grammar> included within a <transfer> is active
during playing of prompts, and during the transfer.
The <transfer> element is optional, though platforms
should support it.
Attributes include:
| name |
The outcome of the transfer attempt. |
| expr |
The initial value of the form item variable; default is
ECMAScript undefined. If initialized to a value, then the form
item will not be visited unless the form item variable is
cleared. |
| cond |
A boolean condition that must also evaluate to true in order
for the form item to be visited. |
| dest |
The URI of the destination (phone, IP telephony address).
Platforms must support the tel: URL syntax described in RFC 2806 and may
support other URI-based addressing schemes. |
| destexpr |
An ECMAScript expression yielding the URI of the destination.
Note that only one of dest or destexpr is allowed. |
| bridge |
This attribute determines what to do once the call is
connected. If bridge is true, document interpretation suspends
until the transferred call terminates and the platform remains
connected to the call.
If it is false, as soon as the call connects, the platform
throws a telephone.disconnect.transfer. |
| connecttimeout |
The time to wait while trying to connect the call before
returning the noanswer condition. Default is platform
specific. |
| maxtime |
The time that the call is allowed to last, or 0 if it can
last arbitrarily long. Only applies if bridge is true. Default is
0. |
| transferaudio |
URI of audio file/stream; for example,
transferaudio="http://www.musiconhold.example.com/foo.wav" |
The <transfer> shadow variable (name$) has the
following ECMAScript properties after a transfer completes:
- name$.duration
- The duration of a successful call in seconds
(floating-point). The duration is 0 if the transferred call was
terminated prior to being answered.
Events thrown inside a <transfer> include:
- telephone.disconnect.hangup
- If the caller hung up.
- telephone.disconnect.transfer
- If the caller has been transferred unconditionally to another
line and will not return.
- error.telephone.noauthorization
- If the caller is not allowed to call the destination.
- error.telephone.baddestination
- If the destination URI is malformed.
- error.telephone.noroute
- If the platform is not able to place a call to the
destination.
- error.telephone.noresource
- If the platform cannot allocate resources to place the
call.
- error.telephone.protocol.nnn
- The telephony protocol stack raised an exception that does
not correspond to one of the other error.telephone events.
The <filled> element specifies an action to perform when
some combination of fields are filled by user input. It may occur
in two places: as a child of the <form> element, or as a
child of a field item.
As a child of a <form> element, the <filled>
element can be used to perform actions that occur when a
combination of one or more fields is filled. For example, the
following <filled> element does a cross-check to ensure
that a starting city field differs from the ending city
field:
<form id="get_starting_and_ending_cities">
<field name="start_city">
<grammar src="http://www.grammars.example.com/voicexml/city.grxml"
type="application/grammar+xml"/>
<prompt>What is the starting city?</prompt>
</field>
<field name="end_city">
<grammar src="http://www.grammars.example.com/voicexml/city.grxml"
type="application/grammar+xml"/>
<prompt>What is the ending city?</prompt>
</field>
<filled mode="any" namelist="start_city end_city">
<if cond="start_city == end_city">
<prompt>
You can't fly from and to the same city.
</prompt>
<clear/>
</if>
</filled>
</form>
If the <filled> element appears inside a field item, it
specifies an action to perform after that field is filled in by
user input:
<form id="get_city">
<field name="city">
<grammar type="application/grammar+xml"/>
src="http://www.ship-it.example.com/grammars/served_cities.grxml"
<prompt>What is the city?</prompt>
<filled>
<if cond="city == 'Novosibirsk'">
<prompt>
Note, Novosibirsk service ends next year.
</prompt>
</if>
</filled>
</field>
</form>
After each gathering of the user’s input, all the fields
mentioned in the input are set, and then the interpreter looks at
each <filled> element in document order (no preference is
given to ones in fields vs. ones in the form). Those whose
conditions are matched by the utterance are then executed in
order, until there are no more, or until one transfers control or
throws an event.
Attributes include:
| mode |
Either all (the default), or any. If any, this action is
executed when any of the specified fields is filled by the last
user input. If all, this action is executed when all of the
mentioned fields are filled, and at least one has been filled by
the last user input. A <filled> element in a field item
cannot specify a mode. |
| namelist |
The fields to trigger on. For a <filled> in a form,
namelist defaults to the names (explicit and implicit) of the
form’s field items. A <filled> element in a field
item cannot specify a namelist; the namelist in this case is the
field item name. |
A <link> element may have one or more grammars, which
are scoped to the element containing the <link>. Grammar
elements contained in the <link> are not permitted to
specify scope. When one of these grammars is matched, the link
activates, and either:
For instance, this link activates when you say "books" or
press "2".
<link next="http://www.voicexml.org/books/main.vxml">
<grammar mode="voice">
<rule id="root" scope="public">
<one-of>
<item>books</item>
<item>VoiceXML books</item>
</one-of>
</rule>
</grammar>
<grammar mode="dtmf">
<rule id="r2" scope="public"> 2 </rule>
</grammar>
</link>
This link takes you to a dynamically determined dialog in the
current document:
<link expr="'#' + document.helpstate">
<grammar mode="voice">
<rule id="root" scope="public"> help </rule>
</grammar>
</link>
The <link> element can be a child of <vxml>,
<form>, or of a form item. A link at the <vxml> level
has grammars that are active throughout the document. A link at
the <form> level has grammars active while the user is in
that form. If an application root document has a document-level
link, its grammars are active no matter what document of the
application is being executed.
If execution is in a modal form item, then link grammars at
the form or document level are not active.
You can also define a link that, when matched, throws an event
instead of going to a new document. This event is thrown at the
current location in the execution, not at the location where the
link is specified. For example, if the user matches this
link’s grammar or enters '2' on the keypad, a help event is
thrown in the form item the user was visiting and is handled by
the best qualified <catch> in the item's scope (see Catch Element Selection for further
details):
<link dtmf="2" event="help">
<grammar mode="voice">
<rule id="r5" scope="public">
<one-of>
<item>arrgh</item>
<item>alas all is lost</item>
<item>fie ye froward machine</item>
<item>I don't get it</item>
</one-of>
</rule>
</grammar>
</link>
Attributes of <link> are:
| next |
The URI to go to. This URI is a document (perhaps with an
anchor to specify the starting dialog), or a dialog in the
current document (just a bare anchor). |
| expr |
Like next, except that the URI is dynamically determined by
evaluating the given ECMAScript expression. |
| event |
The event to throw when the user matches one of the link
grammars. Note that only one of next, expr, or event may be
specified. |
| dtmf |
The DTMF sequence for this link. It is equivalent to a simple
DTMF <grammar>. The attribute can be used at the same time
as other <grammar>s: the link is activated when user input
matches a link grammar or the DTMF sequence. |
| fetchaudio |
See Section 6.1. This defaults to the
fetchaudio property. |
| fetchhint |
See Section 6.1. This defaults to the
documentfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
documentmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
documentmaxstale property. |
The <grammar> element is used to provide a speech
grammar that
-
specifies a set of utterances that a user may speak to perform
an action or supply information, and
-
provides a corresponding string value (in the case of a field
grammar) or set of attribute-value pairs (in the case of a form
grammar) to describe the information or action.
The <grammar> element is designed to accommodate any
grammar format that meets these two requirements. VoiceXML
platforms must support at least one common format, the XML Form of the W3C
Speech Recognition Grammar Format. VoiceXML platforms may
support the Augmented BNF Form of
the W3C Speech Recognition Grammar Format. VoiceXML platforms
may support other grammar formats such as the Java Speech API Grammar
Format (the format used throughout the VoiceXML 1.0
specification) or proprietary formats.
VoiceXML platforms should be a Conforming XML Grammar
Processor as defined in the W3C Speech Recognition
Grammar Format. While this requires a platform to process
documents with one or more "xml:lang" attributes defined, it does
not require that the platform must be multi-lingual. When an
unsupported language, or language list, is encountered, the
platform throws an error.unsupported.language event which
specifies the unsupported language(s) in its message
variable.
The following elements are defined for grammar support. This
document does not redefine these elements. Refer to the W3C Speech Recognition
Grammar Format for definitions and examples.
| Element |
Purpose |
Section
(in grammar spec) |
| <count> |
Rule expansion that defines the number of times its content
may be repeated |
2.5 |
| <example> |
Element contained within a rule definition that provides an
example of input that matches the rule |
3.3 |
| <import> |
Define a local alias for an externally defined rule or
grammar |
4.5 |
| <item> |
Define a sequence or one of a set of alternative
expansions |
2.3 |
| <one-of> |
Define a set of alternative rule expansions |
2.4 |
| <rule> |
Define a grammar rule |
3. |
| <ruleref> |
Refer to a rule defined locally or externally |
2.2 |
| <token> |
Define a word or other entity that may serve as input |
2.1 |
Isssues:
- It is intended that grammar element described in this
document is synchronized with the W3C Speech Recognition Grammar
Format specification. Where there are discrepanies during the W3C
process, Speech Recognition Grammar Format definitions take
precedence.
- A future version of this document use a schema approach where
the grammar element is specified by reference to a separate
namespace defined in the W3C Speech Recognition Grammar Format
document.
The <grammar> element may be used to specify an
inline grammar or an external grammar. An
inline grammar is specified by the content of a <grammar>
element and defines an entire grammar:
<grammar type="mime-type" mode="voice">
inline speech grammar
</grammar>
It may be necessary in this case to enclose the content in a
CDATA
section. For inline grammars the type parameter specifies a media
type that governs the interpretation of the content of the
<grammar> tag.
The following is an example of grammar defined by the XML Form of the W3C
Speech Recognition Grammar Format.
<grammar mode="voice" xml:lang="en-US">
<!-- Command is an action on an object -->
<!-- e.g. "open a window" -->
<rule id="command" scope="public">
<ruleref uri="#action"/> <ruleref uri="#object"/>
</rule>
<rule id="action">
<one-of>
<item> open </item>
<item> close </item>
<item> delete </item>
<item> move </item>
</one-of>
</rule>
<rule id="object">
<count number="optional">
<one-of> <item> the </item> <item> a </item> </one-of>
</count>
<one-of>
<item> window </item>
<item> file </item>
<item> menu </item>
</one-of>
</rule>
</grammar>
The following is the equivalent example of grammar defined by
the Augmented BNF
Form of the W3C Speech Recognition Grammar Format. Because
VoiceXML platforms are not required to support this format it may
be less portable.
<grammar mode="voice" type="application/grammar">
public $command = $action $object;
$action = open | close | delete | move;
$object = [the | a] (window | file | menu);
</grammar>
Issues
- The capabilities for inline grammars in this working draft
are consistent with the spirit of included grammars in VoiceXML
1.0. Both XML and non-XML grammar formats (e.g. the W3C ABNF
format or JSGF) can be included. This represents an overloading
of the grammar element and requires the use of mixed-content in
the DTD. This permits incompatibilities between the W3C XML
Grammar format and the XML grammars permitted within VoiceXML
2.0. We are considering addressing the issue in a future working
draft by an approach such as
- Strict mode: permit only XML grammars to be included within
VoiceXML 2.0
- Loose: as in the current draft allow the grammar element to
include a text grammar as CDATA or include an XML grammar with a
looser DTD than in the grammar spec
- Nested: introduce a new element to contain textual (non-XML)
grammars such as W3C ABNF or JSGF.
(See also the equivalent issues for grammar fragments in the next
section.)
The <grammar> element may also be used to specify an
inline grammar fragment. A grammar fragment is defined
as a legal rule
expansion in the grammar format. (Note: the W3C grammar
specification does not yet address conformance behavior for
grammar fragments.)
Note: the specification does not currently permit inline
grammar fragments to be defined with the XML grammar format. This
issue is under study (see the Issues below).
<grammar type="mime-type" mode="voice">
inline speech grammar fragment
</grammar>
Grammar fragments are a useful short-hand when the inline
grammar represents a short phrase or set of short phrases.
It may be necessary in this case to enclose the content in a
CDATA
section. For inline grammars the type parameter specifies a media
type that governs the interpretation of the content of the
<grammar> tag.
The following is an example of a grammar fragment defined with
the Augmented BNF
Form of the W3C Speech Recognition Grammar Format. Because
VoiceXML platforms are not required to support this format it
might be less portable.
<grammar mode="voice" type="application/grammar">
red | green | blue
</grammar>
Issues
- The current draft does not permit inline grammar fragments to
be defined with the XML grammar format. The motivation is to
avoid unnecessary incompatibilities with the W3C XML Grammar
Format. The issue remains under consideration and may change if
the grammar specification defines conformance behavior with
respect to XML fragments and after the impact of permitting XML
grammar fragments has been studied. In the mean time, developers
should wrap XML rule expansions with a single rule element. For
example, the equivalent XML form of the example above is:
<grammar>
<rule id="root" scope="public">
<one-of>
<item> red </item>
<item> green </item>
<item> blue </item>
</one-of>
</rule>
</grammar>
An external grammar is specified by an element of the form
<grammar src="URI" type="media-type"/>
The media type is optional in this case because this
information may be obtained via the URI protocol (as in the case
of HTTP), and may be inferred from the filename extension. If the
type is not specified, and cannot be inferred, the default type
is platform specific. However, if the type is specified using the
type attribute, it overrides other information about the
type.
If the src attribute is defined and there is an inline grammar
as content of a grammar element then the src attribute takes
precedence.
The following is an example of a reference to an external
grammar written in the W3C XML Grammar Format.
<grammar type="application/grammar+xml"
src="http://www.grammar.example.com/date.grxml"/>
The following example is the equivalent grammar reference for
a grammar that is authored using the W3C Augmented BNF grammar
format.
<grammar type="application/grammar"
src="http://www.grammar.example.com/date.grm"/>
The following example is the equivalent grammar reference for
a grammar that is authored using the JSpeech Grammar Format. The
example illustrates that VoiceXML 2.0 does not restrict which
grammar formats a VoiceXML platform may support. Since the W3C
XML Grammar Format is the only format that a platform is required
to support it should be used when interoperability and
portability are required.
<grammar type="application/x-jsgf"
src="http://www.grammar.example.com/date.gram"/>
Note: the filename suffixes and media types in
these examples are tentative.
A weight for the grammar can be specified by the weight
attribute:
<grammar weight="0.6" src="form.grxmlm" type="application/grammar+xml"/>
Grammar elements, including those in link, field and form
elements, can have a weight attribute. The grammar can be inline,
external or built-in. The value of the weight attribute indicates
the occurrence likelyhood of each grammar, and must be zero or a
positive floating point number (nnn[.nnn]). The default weight
for a grammar whose weight is unspecified is 1.0.
Consequently, if no weight is specified for any grammar element,
all grammars are equally likely. The semantics of weight
attributes is equivalent to the case where all active grammars
are listed as items in alternatives (one-of element) in W3C XML
Grammar Format, except for the fact that the grammar with no
weight specified has default weight of 1.0.
<link event="help">
<grammar weight="0.5" mode="voice">
<rule id="help" scope="public">
<count number="optional"><item>Please</item></count><item>help</item>
</rule>
</grammar>
</link>
<form>
<grammar src="form.grxml" type="application/grammar+xml"/>
<field name="expireDate">
<grammar weight="1.2" src="builtin:grammar/date"/>
</field>
</form>
In the example above, the semantics of weights is equivalent
to the following W3C XML grammar.
<one-of>
<item weight="0.5"> <ruleref uri="#help"/> </item>
<item weight="1.0"> <ruleref uri="form.grxml"/> </item>
<item weight="1.2"> <ruleref uri="builtin:grammar/boolean"/></item>
</one-of>
<rule id="help">
<count number="optional"><item>Please</item></count><item>help</item>
</rule>
Implicit grammars, such as those in options, do not support
weights - use the <grammar> element instead for control
over grammar weight.
Grammar weights only affect grammar processing. They do not
directly affect the post processing of grammar results, including
grammar precedence when user input matches multiple active
grammar (see Section 3.1.4).
A weight has no effect on DTMF grammars (See Section 3.1.2). Any weight attribute
specified in a grammar element whose mode attribute is dtmf
is ignored.
<grammar mode="dtmf" weight="0.3" src="builtin:number"/> <!-- weight will be ignored -->
Appropriate weights are difficult to determine, and guessing
weights does not always improve recognition performance.
Effective weights are usually obtained by study of real speech
and textual data on a paricular platform. Furthermore, a grammar
weight is platform specific. Note that different ASR engines may
treat the same weight value differently. Therefore, the weight
value that works well on particular platform may generate
different results on other platforms.
Attributes of <grammar> include:
| xml:lang |
The language and locale identifier of the contained or
referenced grammar following RFC 1766. (For
example, "fr-CA" for Canadian French.) If omitted, the value is
inherited down from the document hierarchy. Should the grammar
self-identify its locale, that definition has precedence. |
| src |
The URI specifying the location of the grammar and optionally
a rulename within that grammar, if it is external. The URI is
interpreted as a rule reference as defined in Section 2.2
of the Speech Recognition Grammar Format but not all forms of
rule reference are permitted from within VoiceXML. The rule
reference capabilities are described in detail below this
table. |
| scope |
Either "document", which makes the grammar active in all
dialogs of the current document (and relevant application leaf
documents), or "dialog", to make the grammar active throughout
the current form. If omitted, the grammar scoping is resolved by
looking at the parent element. See Section
3.1.3 for details on scoping including precedence
behavior. |
| type |
The media type of the grammar. If this is omitted, the
interpreter context will attempt to determine the type
dynamically. If the content of the element is an XML grammar then
the media type may be omitted. The tentative media types for the
W3C grammar format are "application/grammar+xml" for the XML form
and "application/grammar" for Augmented BNF grammars. |
| mode |
Defines the mode of the contained or referenced grammar
following the modes of the W3C Speech Recognition
Grammar Format. Defined values are "voice" and "dtmf" for
DTMF input. If the mode value is in conflict with the mode of the
grammar itself, a "badfetch" event is thrown. |
| root |
Defines the public rule which acts as the root rule of the
grammar. The root rule is only used when the grammar is inline
and must be present when using an inline XML grammar to identify
which rule to activate. |
| version |
Defines the version of the grammar. The default value is
"1.0". |
| weight |
Specifies the weight of the grammar. See Section 3.1.1.4 |
| fetchhint |
See Section 6.1. This defaults to the
grammarfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
grammarmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
grammarmaxstale property. |
When referencing an external grammar, the value of the src
attribute is a URI specifying the location of the grammar with an
optional fragment for the rulename. Section 2.2
of the Speech Recognition Grammar Format defines several forms of
rule reference. The following are the forms that are permitted on
a grammar element in VoiceXML.
- Reference to a named rule in an external grammar:
src attribute is an absolute or relative URI reference to a
grammar which includes a fragment with a rulename. This form of
rule reference to an external grammar follows the behavior
defined in Section
2.2.2 of SRGF. If the URI cannot be fetched or if the
rulename is not defined in the grammar or is not a public
(activatable) rule of that grammar then an error.badfetch is
thrown.
- Reference to the root rule of an external grammar:
src attribute is an absolute or relative URI reference to a
grammar but does not include a fragment identifying a rulename.
This form implicitly references the root rule of the grammar as
defined in Section
2.2.2 of SRGF. If the URI cannot be fetched or if the grammar
cannot be referenced by its root (see Section 4.4
of SRGF) then an error.badfetch is thrown.
The following are the forms of rule reference defined by SRGF
that are not supported in VoiceXML 2.0.
- Local rule reference: a fragment-only URI is not
permited. (See definition in Section
2.2.1 of SRGF). A fragment-only URI value for the src
attribute causes an error.semantic event.
- Reference by alias: although an inline grammar may
define aliases and make reference by alias there is no support
for alias references on the grammar element itself. (See
definitions in Section
2.2.3 of SRGF). There is no syntactic support for this form
so no error can be generated.
- Reference to special rules: although an inline
grammar may reference the special rules of SRGF (NULL, VOID,
GARBAGE) there is no support for special rule references on the
grammar element itself. (See definitions in Section
2.2.3 of SRGF). There is no syntactic support for this form
so no error can be generated.
The <grammar> element can be used to specify a DTMF
grammar that
-
defines a set of key presses that a user may use to perform an
action or supply information, and
-
defines the corresponding string value that describes that
information or action.
VoiceXML platforms are required to support the DTMF grammar
XML format defined in Appendix D of the W3C Grammar
specification to advance application portability.
A DTMF grammar is distinguished from a speech grammar by the
mode attribute on the <grammar> element. An "xml:lang"
attribute has no effect on DTMF grammar handling. In other
respects speech and DTMF grammars are handled identically
including the ability to define the grammar inline, by an inline
grammar fragment, or by an external grammar reference. The media
type handling, scoping and fetching are also identical.
The following is an example of a simple XML DTMF grammar that
accepts as input either "123" or "#" as input.
<grammar mode="dtmf">
<rule id="root" scope="public">
<one-of>
<item> 123 </item>
<item> # </item>
</one-of>
</rule>
</grammar>
Field grammars are always scoped to their fields,
that is, they are not active unless the interpreter is visiting
that field. Grammars contained in fields cannot specify a
scope.
Link grammars are given the scope of the element that
contains the link. Thus, if they are defined in the application
root document, links are also active in any other loaded
application document. Grammars contained in links cannot specify
a scope.
Form grammars are by default given dialog scope, so
that they are active only when the user is in the form. If they
are given scope document, they are active whenever the user is in
the document. If they are given scope document and the document
is the application root document, then they are also active
whenever the user is in another loaded document in the same
application. A grammar in a form may be given document scope
either by specifying the scope attribute on the form element or
by specifying the scope attribute on the <grammar> element.
If both are specified, the grammar assumes the scope specified by
the <grammar> element.
Menu grammars are also by default given dialog scope,
and are active only when the user is in the menu. But they can be
given document scope and be active throughout the document, and
if their document is the application root document, also be
active in any other loaded document belonging to the application.
Grammars contained in menu choices cannot specify a scope.
Sometimes a form may need to have some grammars active
throughout the document, and other grammars that should be active
only when in the form. One reason for doing this is to minimize
grammar overlap problems. To do this, each individual
<grammar> element can be given its own scope if that scope
should be different than the scope of the <form> element
itself:
<form scope="document">
<grammar> ... </grammar>
<grammar scope="dialog"> ... </grammar>
</form>
When the interpreter waits for input as a result of visiting a
field, the following grammars are active:
-
grammars for that field, including grammars contained in links
in that field;
-
grammars for its form, including grammars contained in links
in that form;
-
grammars contained in links in its document, and grammars for
menus and other forms in its document which are given document
scope;
-
grammars contained in links in its application root document,
and grammars for menus and forms in its application root document
which are given document scope.
-
grammars defined by platform default event handlers, such as
help, exit and cancel.
In the case that an input matches more than one active
grammar, the list above defines the precedence order. If the
input matches more than one active grammar with the same
precedence, the precedence is determined using document order.
Menus behave with regard to grammar activation like their
equivalent forms (see Section 2.2).
If the form item is modal (i.e., its modal attribute is set to
true), all grammars except its own are turned off while waiting
for input. If the input matches a grammar in a form or menu other
than the current form or menu, control passes to the other form
or menu. If the match causes control to leave the current form,
all current form data is lost.
Issues:
- The definition above for precedence of grammars may, in
certain circumstances, conflict with the requirement in Section
2.3.1 that 0th entry in the n-best provide the contents of a
field's shadow variables. A future working draft will resolve
this conflict.
Issues:
The W3C Voice Browser Working Group is
currently developing standards for processing and representation
of semantic input. The following is a summary of the work in
progress and the issues that are being addressed. The intent of
this work is to provide a standard mechanism for each of the
following:
- Grammar annotation: A speech or DTMF
grammar may be annotated with tags that indicate how to process
input that matches the grammar. The current W3C Speech Recognition
Grammar Specification defines the tag capabilities in Section
2.6.
- Semantic interpretation tags: A
definition of the content of those tags and of the computational
process by which the tags are used to process input speech or
DTMF events. This specification has not yet been published.
- Natural Language Semantics Markup
Language: A XML document that represents the semantic content
of a input utterance. The first Working Draft of this
specification is available.
- VoiceXML: A representation of that
semantic content in the scope of the VoiceXML Processor that
permits the VoiceXML application to use the information in dialog
processing.
The following is a tentative example of
semantic attachments The tags represent simple keys that will be
returned as the result when either the speech or DTMF grammar is
matched. Whether the user says "Amex" or "American Express" or
enters DTMF key '1' the result will be the "AMEX" tag.
<grammar mode="voice">
<rule id="rule" scope="public">
<one-of>
<item tag="MC">master card</item>
<item tag="VISA">visa</item>
<item tag="AMEX">amex</item>
<item tag="AMEX">american express</item>
</one-of>
</rule>
</grammar>
<grammar mode="dtmf">
<rule id="rule" scope="public">
<one-of>
<item tag="MC"> 1 </item>
<item tag="VISA"> 2 </item>
<item tag="AMEX"> 3 </item>
</one-of>
</rule>
</grammar>
In order to make the results of the interpretation of a user's
utterance usable within a VoiceXML form, the interpretation must
be mapped into VoiceXML ECMAScript variables, Results can
be represented either in the proposed XML format defined by the
Natural Language
Semantics Markup Language or in the ECMAScript-like
output format defined in the Speech Recognition
Grammar Specification. In either case, many of the same
issues arise; however, because the Natural Language Semantics
Markup Language is less mature than the speech recognition output
format, we focus in this discussion on examples using the
ECMAScript-based ASR result format.
This discussion deals with issues concerning mapping results
from form-level and field level grammars. There is also a brief
discussion of other issues such as the NL Semantics to
ECMAScript mapping, transitioning information from ASR results to
VoiceXML,and dealing with mismatches between the interpretation
result and the VoiceXML form.
Consider the following interpretation result from the sentence
"I would like a coca cola and three large pizzas with pepperoni
and mushrooms."
{
drink: "coke"
pizza: {
number: "3"
size: "large"
topping: [
"pepperoni"
"mushrooms"
]
}
}
produced by the following grammar:
$order = I would like a $drink {drink:$drink} and $pizza {pizza:$pizza};
$drink = coke | pepsi | coca cola {{coke}};
$pizza = $number $size {size:$size; number:$number.n} pizzas with $tops {topping:$tops.l};
$number = (a | one){n:1} | two {n:2}| three {n:3};
$size = small | medium | large ;
$tops = $top {l:List($top)} (and $top {l:Append(l,$top)})+ ; // construct list of toppings
$top = anchovies|pepperoni|mushrooms;
The following table illustrates how the result shown above
from a form-level grammar would be assigned to various fields
within the form. Note that all fields that can be filled in from
the interpretation are filled in simultaneously before any fields
are visited by the FIA.
| VoiceXML field |
Assigned ECMAScript value |
Explanation |
| 1. <field
name="drink"/> |
"coke" |
By default a field is assigned the top-level
result property whose name matches the field name. |
| 2. <field name="..."
slot="drink"/> |
"coke" |
If specified, the slot overrides the field name
for selecting the result property. |
3. <field name="pizza"/>
--or--
<field name="..." slot="pizza"/> |
{number: "3", size: "large", topping:
["pepperoni", "mushroom"]} |
The field name or slot may select a property
that is a non-scalar ECMAScript variable in the same way that a
scalar value is selected in the previous example. However the
application must then handle inspecting the components of the
object. This does not take advantage of the VoiceXML form-filling
algorithm, in that missing slots in the result would not be
automatically prompted for. This may be sufficient in situations
where the server is prepared to deal with a structured object.
Otherwise, an application may prefer to use the method described
in the next example. |
4. <field name="..."
slot="pizza.number"/>
<field name="..." slot="pizza.size"/> |
"3"
"large" |
The slot may be used to select a sub-property of
the result. This approach distributes the result among a number
of fields. |
| 5. <field name="..."
slot="pizza.topping"/> |
["pepperoni", "mushroom"] |
The selected property may be a compound
object. |
These examples can be explained by rules that are compatible
with and are straightforward extensions of the VoiceXML 1.0
"name" and "slot" attributes:
- The "slot" attribute of a <field> is a (very
restricted) ECMAScript expression that selects some portion of
the result to be assigned to the field. Note that it is possible
for a specific slot value to fill more than one field, if the
slot names of the fields are the same.
- If the portion of the result named by the "slot" (or "name")
attribute of a <field> doesn't exist in a given result then
the field item's value is unchanged.
- The default value for the "slot" attribute is supplied by the
value of "name" attribute.
The examples only show only one level of sub-element, but it
seems reasonable to allow sub-sub-elements to arbitrary levels of
nesting, using a dot-separated list of element/property names.
Another potential extension would be to use the slot name to
select an array element, for example "slot="pizza.topping[0]".
However, it's not clear how useful it would be since there's no
mechanism in VoiceXML for looping through the array elements. In
addition, this raises other questions, such as whether the index
of the array can be a variable.
Field-level grammars, unlike form-level grammars, are only
active while visiting the field in which they are contained, and
therefore they are only able to supply a value for that field.
This is useful for example in directed dialogs, where a user is
prompted individually for a value for each field. This is
supported by assigning to the field variable the entire semantic
result from a field-level grammar.
Consider for example the following field that contains a
field-level grammar that returns a value representing the credit
card type. (Note that the exact format of the XML grammar tags
hasn't yet been determined; the example will be reconciled with
this format when it is fully defined.)
<field name="cardname"/>
<prompt>Which credit card?</prompt>
<grammar mode="voice">
<rule id="rule" scope="public">
<one-of>
<item tag="MC">master card</item>
<item tag="VISA">visa</item>
<item tag="AMEX">amex</item>
<item tag="AMEX">american express</item>
</one-of>
</rule>
</grammar>
When the user responds with a credit card name such as
"american express" the following semantic result value might be
returned:
"AMEX"
This ECMAScript string value "AMEX" would be assigned to the
"cardname" field that contains the grammar.
This assignment of the entire semantic result to a field would
also apply to a structured object. An example of such a
structured object might be a date, when the application treats
the date as a unit.
Issues:
- For the purposes of symmetry with the form-level case, it
might seem reasonable to support assignment of semantic results
to slots in field-level grammars when a slot is present, in a
similar fashion to the example in line 2 of the table above.
However, this would preclude the useful case where the form has
both a form-level grammar, using the slot attribute of a field to
select a slot from the form-level grammar, and a field level
grammar using simple tags to directly provide a field value
ignoring the slot parameter.
1. Mapping from NL semantics to ECMAScript: If the NL
Semantics Markup Language (NLSML) is used, a mapping needs to be
defined from the NLSML representation to ECMAScript objects.
Since both types of representation have similar nested
structures, this mapping is fairly straightforward. This mapping
is discussed in detail in the NL Semantics specification.
2. Transitioning semantic results from ASR to VoiceXML: The
result of processing the semantic tags of a W3C ASR grammar is
the value of the attribute of the root rule when all semantic
attachment evaluations have been completed. In addition, the root
rule (like all non-terminals) has an associated "text" variable
which contains the series of tokens in the utterance that is
governed by that non-terminal. In the process of making ASR
results available to VoiceXML documents, the VoiceXML platform is
not only responsible for filling in the VoiceXML fields based on
the value of the attribute of the root rule, as described above,
but also for filling in the shadow variables of the field. The
name$.utterance shadow variable of the field should be the same
as the "text" variable value for the ASR root rule. The platform
is also responsible for instantiating the value of the shadow
variable "name$.confidence" based on information supplied by the
ASR platform, as well as the value of "name$.inputmode" based on
whether DTMF or speech was processed. Finally, the platform is
responsible for making this same information available in the
"application.lastresult$" variable, defined in Section 5.1.5
(specifically, "application.lastresult$.utterance",
"application.lastresult$.inputmode",
"application.lastresult$.interpretation", and
"application.lastresult$.confidence").
3. Mismatches between semantic results and VoiceXML fields:
Mapping semantic results to VoiceXML depends on a tight
coordination between the ASR grammar and the VoiceXML markup.
Since in the current framework there's nothing that enforces
consistency between a grammar and the associated VoiceXML dialog,
mismatches can occur due to developer oversight. Since the
dialog's behaviour during these mismatches is difficult to
distinguish from certain normal situations, verifying consistency
of information is extremely important. Some examples of
mismatches:
- The semantic results contain extra information that doesn't
correspond to the VoiceXML fields.This could occur either due to
developer error or if a richer grammar is being used than is
required by the VoiceXML application. This extra information will
be ignored.
- The VoiceXML application expects information in the result
that isn't present. This could also be due to developer error, or
it may be that the user simply didn't supply a value for a
particular slot. In this case the normal FIA applies and the
missing value would be elicited from the user. If the problem was
in fact caused by a developer error, and the grammar is actually
incapable of recognizing the correct value, the FIA will keep
eliciting the missing value until it invokes whatever provisions
the platform and application have in place for repeated nomatch
failures.
- Finally, information might be present in both the VoiceXML
and the ASR result, but in inconsistent formats. For example, an
ASR grammar might provide a structured object for the drink which
includes the size and whether the drink is diet or non-diet, but
the VoiceXML form might only expect a string consisting of the
name of the drink. The system's behaviour in these situations
would depend on what is being done with the results. For example,
a structured object might be sent to a server side script that's
expecting a string, and the consequences of this would depend on
the server script.
In order to address these potential problems, the committee is
looking at various approaches to ensuring consistency between the
grammar and the VoiceXML.
The prompt element controls the output of synthesized speech
and prerecorded audio. Conceptually, prompts are instantaneously
queued for play, so interpretation proceeds until the user needs
to provide an input. At this point, the prompts are played, and
the system waits for user input. Once the input is received from
the speech recognition subsystem (or the DTMF recognizer),
interpretation proceeds.
Prompts have the following attributes:
| bargein |
Control whether a user can interrupt a prompt. Default is
true. |
| bargeintype |
Sets the type of bargein to be 'energy', 'speech', or
'recognition'. Default is platform-specific. |
| cond |
An expression telling if the prompt should be spoken. Default
is true. |
| count |
A number that allows you to emit different prompts if the
user is doing something repeatedly. If omitted, it defaults to
"1". |
| timeout |
The timeout that will be used for the following user input.
The default noinput timeout is platform specific. |
| xml:lang |
The language and locale type as defined in RFC 1766. If
omitted, it defaults to the value specified in the document's
"xml:lang" attribute. |
You’ve seen prompts in the previous examples:
<prompt>Please say your city.</prompt>
You can leave out the <prompt> ... </prompt>
if:
-
There is no need to specify a prompt attribute (like bargein),
and
-
The prompt consists entirely of PCDATA (contains no speech
markups) or consists of just an <audio> or <value>
element.
For instance, these are also prompts:
Please say your city.
<audio src="say_your_city.wav"/>
But in this example, the enclosing prompt elements are
required due to the embedded speech markups:
<prompt>Please <emphasis>say</emphasis> your city.</prompt>
VoiceXML uses the speech markup elements defined in the W3C Speech Synthesis
Markup Language.
Prompts can include special controls to affect how a speech
synthesis engine audibly renders text. Such controls are
pronunciation, rate, pitch, and other characteristics. For
example, emphasis and timing can be controlled as:
<prompt> This is <emphasis>computer-generated</emphasis> text.
<break size="medium"/> Do you like it? </prompt>
These controls, as well as language information, are inherited
down the document hierarchy.
The VoiceXML platform should be a Conforming Speech Synthesis
Markup Language Processor as defined in the W3C Speech Synthesis
Markup Language. While this requires a platform to process
documents with one or more "xml:lang" attributes defined, it does
not require that the platform must be multi-lingual. When an
unsupported language is encountered, the platform throws an
error.unsupported.language event which specifies the
language in its message variable.
Isssues:
- It is intended that synthesis elements described in this
document are synchronized with the Speech Synthesis Markup
Language. Where there are discrepanies during the W3C process,
definitions in the Speech Synthesis Markup Language take
precedence.
- A future version of this document may use a schema approach
which specifies synthesis elements by reference to a separate
namespace defined in the Speech Synthesis Markup Language.
Specifies a pause in the speech output. Attributes of
<break> are:
| time |
The absolute pause duration in seconds or milliseconds,
following the "time"
value format from the W3C Cascading Style Sheets,
level 2 CSS2 Specification. Examples of valid time values
include "250ms", "2.5s", or "3s". |
| size |
A relative pause duration. Possible values are: none, small,
medium or large. Actual pause duration depends upon variables
such as speaking rate and platform defaults. |
At most one of time and size must be specified. If neither are
specified, size="medium" is assumed.
Identifies the enclosed text as a paragraph, containing zero
or more sentences. For brevity, <p> is supported as an
equivalent of <paragraph>.
Attributes of <paragraph> and <p> are:
| xml:lang |
The language and locale type as defined in RFC 1766. If
omitted, it defaults to the value inherited down the document
hierarchy. |
Identifies the enclosed text as a sentence. For brevity,
<s> is supported as an equivalent of <sentence>.
Attributes of <sentence> and <s> are:
| xml:lang |
The language and locale type as defined in RFC 1766. If
omitted, it defaults to the value inherited down the document
hierarchy. |
Specifies that the enclosed text should be spoken with
emphasis. Attributes of <emphasis> are:
| level |
Specifies the level of emphasis. Possible values are: strong,
moderate (default), none or reduced. |
Specifies prosodic information for the enclosed text.
Attributes of prosody are:
| pitch |
Specifies the pitch. Values are: high, medium, low, or
default. |
| contour |
Sets the actual pitch contour for the contained text. |
| range |
Specifies pitch range. Values are: high, medium, low, or
default. |
| rate |
Specifies the speaking rate. Values are: fast, medium, slow
or default. |
| duration |
Specifies the duration in seconds or milliseconds for the
desired time to take to read the element contents. |
| volume |
Specifies the output volume. Values are: silent, soft,
medium, loud or default. |
Specifies the type of text construct contained within the
element. Attributes of <say-as> are:
| sub |
Defines substitute text to be spoken instead of the contained
text. |
| type |
Indicates the contained text construct. |
The values of "type" are a text type optionally followed by a
colon and format:
| acronym |
The contained text is an acronym to be pronounced as
individual characters. |
| number |
The contained text is number. Format values are "ordinal" and
"digits". |
| date |
The contained text is a date. Format values for dates are
"dmy", "mdy", "ymd", "ym", "my", "md", "y". |
| time |
The contained text is a time of day. Format values for time
are "hm", and "hms". |
| duration |
The contained text is a temporal duration. Format values for
duration are "hm", "hms", "ms", etc. |
| currency |
The contained text is a currency amount. Leading and trailing
currency symbols are ignored. |
| measure |
The contained text is a measurement. |
| telephone |
The contained text is a telephone number. |
| name |
The contained text is a proper name of a person,
organization, etc. |
| net |
The contained text is a internet handle. Format values for
net are "email", "url". |
| address |
The contained text is a postal address. |
For example:
<say-as type="date:ymd"> 2000/1/20 </say-as>
would be spoken as "January 20th two thousand".
Specifies a phonetic pronunciation for the contained text.
Attributes for <phoneme> are:
| ph |
This required attribute specifies the phonetic string. |
| alphabet |
This optional attribute specifies the alphabet to use from
one of: ipa
(International Phonetic Alphabet),
worldbet (Postscript) phonetic alphabet, or xsampa
phonetic alphabet. |
Specifies voice characteristics for the spoken text.
Attributes for <voice> are:
| gender |
Preferred gender of the voice to speak the contained text.
Values are "male", "female", or "neutral". |
| age |
Preferred age of the voice to speak the contained text. The
value is an integer. |
| category |
Preferred age category of the voice to speak the contained
text. The values are: "child", "teenager", "adult", or
"elder" |
| variant |
A variant of the other voice characteristics to speak the
contained text. The value is an integer. |
| name |
The name of a platform-specific voice name to speak the
contained text. The value may be a space-separated list of names
ordered from top preference down. |
This feature should be ignored by VoiceXML platforms.
Issues:
- The utility of this element, as well as how notifications
could be reported in VoiceXML, is being investigated.
Prompts can consist of any combination of prerecorded files,
audio streams, or synthesized speech:
<prompt>
Welcome to the Bird Seed Emporium.
<audio src="rtsp://www.birdsounds.example.com/thrush.wav"/>
We have 250 kilogram drums of thistle seed for
<say-as class="currency">$299.95</say-as>
plus shipping and handling this month.
<audio src="http://www.birdsounds.example.com/mourningdove.wav"/>
</prompt>
Audio can be played in any prompt. Typically it is specified
via a URI, but it can also be in an audio variable
previously recorded:
<prompt>
Your recorded greeting is
<value expr="greeting"/>
To rerecord, press 1.
To keep it, press pound.
To return to the main menu press star M.
To exit press star, star X.
</prompt>
The audio element can have alternate content in case the audio
sample is not available:
<prompt>
<audio src="welcome.wav">
<emphasis>Welcome</emphasis> to the Voice Portal.
</audio>
</prompt>
If the audio file cannot be played (e.g. unsupported format,
invalid URI, etc.), the content of the audio element is played
instead. The content may include text, speech markup, or another
audio element. If the audio file cannot be played and the content
of the audio element is empty, an appropriate error event will be
thrown.
If <audio> contains an 'expr' attribute evaluating to
null, then the element, including its alternate content, is
ignored. This allows a developer to specify <audio>
elements with dynamically assigned content which, if the element
is not required, can be ignored by assigning its 'expr' a null
value. For example, the following code shows how this could be
used to play back a hand of cards using concatenated audio
clips:
<form>
<!-- script contains the function sayCard(position,type) which returns
audio or textual description of the card in the specified position;
if there are no more cards, then returns null --!>
<script src="cardgame.js"/>
<field name="takecard" type="boolean">
<prompt>
<audio src="you_have.wav">You have the following cards: </audio>
<!-- maximum of hand of 5 cards is described --!>
<audio expr="sayCard(audio,1)"><value expr="sayCard(text,1)"/></audio>
<audio expr="sayCard(audio,2)"><value expr="sayCard(text,2)"/></audio>
<audio expr="sayCard(audio,3)"><value expr="sayCard(text,3)"/></audio>
<audio expr="sayCard(audio,4)"><value expr="sayCard(text,4)"/></audio>
<audio expr="sayCard(audio,5)"><value expr="sayCard(text,5)"/></audio>
<audio src="another.wav">Would you like another card?</audio>
</prompt>
<filled>
<if cond="takecard">
<script>takeAnotherCard()</script>
<clear/>
<else/>
<goto next="./make_bid.html"/>
</if>
</filled>
</field>
</form>
Attributes of <audio> include:
| src |
The URI of the audio prompt. See Appendix E for required audio file
formats; additional formats may be used if supported by the
platform. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| fetchhint |
See Section 6.1. This defaults to the
audiofetchhint property. |
| maxage |
See Section 6.1. This defaults to the
audiomaxage property. |
| maxstale |
See Section 6.1. This defaults to the
audiomaxstale property. |
| expr |
Dynamically determine the URI to fetch by evaluating this
ECMAScript expression. If a 'src' attribute is specified, it
takes precedence over the 'expr' attribute. |
Issues:
- A future revision of this document may add a boolean "stream"
attribute to <audio> indicating that the interpreter is to
begin processing the audio content as it arrives and not to wait
for full retrieval. This will give developers explicit control
over audio streaming. Until then, platforms may choose to stream
audio as an optimization.
The <value> element is used to insert the value of an
expression into a prompt. For example if n is 12, the prompt
<prompt>
<value expr="n*n"/> is the square of <value expr="n"/>.
</prompt>
will result in the text string "144 is the square of 12" being
passed to the speech synthesis engine.
When the 'expr' attribute in <value> specifies a
<record> field item variable, the recorded audio is played
back (see example in Section 2.3.6).
The manner in which the value attribute is played is
controlled by the surrounding speech synthesis markup. For
instance, a value can be played as a date in the following
example:
<var name="date" expr="'2000/1/20'"/>
<prompt>
<say-as type="date:ymd"> <value expr="date"> </say-as>
</prompt>
Evaluation of the 'expr' attrbute may return a string
containing speech synthesis markup (as defined by SSML). Thus it
may return any of the structures that can be contained within a
prompt element except another value element (which is not defined
within SSML).
The platform must perform the following steps to convert a
prompt containing values returning one or more SSML
expressions.
- Expand each value expression by replacing the value element
by the text produced by the expression. (Do not recursively
expand value elements.)
- Ensure that expanded prompt is a valid prompt structure. If
not, throw an error.semantic event.
Consider the following assignments to three ECMAScript
variables
e1 = "<voice gender='male' age='20'>";
e2 = "<paragraph>I want a <emphasis>large</emphasis> pizza with pepperoni</paragraph>"
e3 = "</voice>";
and the following prompt element containing a sequence of
value elements.
<prompt>
<value expr="e1"/>
<value expr="e2"/>
<value expr="e3"/>
</prompt>
After expansion and validation this prompt is equivalent to
the following prompt element. Note that e1 and e3 containing
matching opening and closing voice elements so that after
expansion the prompt remains well-formed XML.
<prompt>
<voice gender='male' age='20'>
<paragraph>I want a <emphasis>large</emphasis> pizza with pepperoni</paragraph>
</voice>
</prompt>
Issues:
- Issue 1: XML Special characters in prompt CDATA
Consider the following ECMAScript variable assignment
e1 = '<emphasis>$12345</emphasis>'
And the following VoiceXML fragment
<prompt>The price of AT&T is <value expr="e1"/>.</prompt>
The initial XML parse of the containing VoiceXML document turns
AT&T into AT&T. However, since '&' is a reserved
character in XML, it must be re-quoted by the VoiceXML
interpreter before re-parsing. This must result in the following
text being sent to the SSML interpreter:
The price of AT&T is <emphasis>$12345</emphasis>.
Implication: any XML special characters contained in CDATA within
the subtree of a prompt element must be handled specially by the
VoiceXML interpreter.
- Issue 2: XML Special characters returned in string of
value expression
Since the string returned by the expression of a value element
is re-parsed as XML, any XML special characters contained within
the string must be quoted by the VoiceXML application developer.
For example, when the following variable assignment
e1 = 'AT&T';
is referenced in a prompt element as
<prompt>The price of <value expr="e1"/> is $12345.</prompt>
this would result in the following text being sent to the SSML
parser. Note that the entity references are properly formatted
making it a well-formed XML fragment.
The price of AT&T is $1.
Negative example: The following is an example of an expected
mis-handling on entity references. This following is legal
ECMAScript however once the string is substituted into the prompt
the XML is no longer well-formed.
e1 = 'AT&T';
This is the same prompt element.
<prompt>The price of <value expr="e1"/> is $12345.</prompt>
Resulting in the followong ill-formed XML being sent to the SSML
parser:
The price of AT&T is $1.
We encourage reviewer comment on the trade-off between the
expressive power of a value expression returning SSML vs. the
potential for developer confusion.
Attributes of <value> are:
| expr |
The expression to render. |
If an implementation platform supports barge-in, the service
author can specify whether a user can interrupt, or "barge-in"
on, a prompt using speech or DTMF input. This speeds up
conversations, but is not always desired. If the application
author requires that the user must hear all of a warning, legal
notice, or advertisement, barge-in should be disabled. This is
done with the bargein attribute:
<prompt bargein="false"><audio src="legalese.wav"/></prompt>
Users can interrupt a prompt whose bargein attribute is true,
but must wait for completion of a prompt whose bargein attribute
is false. In the case where several prompts are queued, the
bargein attribute of each prompt is honored during the period of
time in which that prompt is playing. If bargein occurs during
any prompt in a sequence, all subsequent prompts are not played.
If the bargein attribute is not specified, then the value of the
bargein property is used if set.
When the bargein attribute is false, any DTMF input buffered
in a transition state is deleted from the buffer (Section 4.1.8 describes input collection
during transition states).
Note that not all speech recognition engines or implementation
platforms support barge-in. For a platform to support barge-in,
it must support at least one of the barge-in types described in
Section 4.1.5.1.
When barge-in is enabled, the bargeintype attribute can be
used to suggest the type of bargein the platform will perform.
Possible values for this attribute are:
| energy |
The prompt will be stopped if energy or a DTMF
tone is detected. |
| speech |
The prompt will be stopped if speech or a DTMF
tone is detected. |
| recognition |
The prompt will only be stopped if a speech or
DTMF grammar is successfully matched. If a grammar is not
matched, the recognizer will continue listening for input. |
If the bargeintype attribute is not specified, then the value
of the bargeintype property is used if set.
Implementations that claim to support barge-in are required to
support at least one of these three types. For each unsupported
type x, a platform is required to document which of the
other two types will be used when type x is requested.
Note that with energy and speech barge-in, the prompt is
stopped irrespective of whether the recognizer matches the
utterance/DTMF string or not. For the recognition type of
barge-in, a 'nomatch' event will never be generated.
Mixing these types within a single queue of prompts can result
in unpredictable behavior and is discouraged. Where possible,
platforms should attempt to behave in a reasonable manner.
Tapered prompts are those that may change with each
attempt. Information-requesting prompts may become more terse
under the assumption that the user is becoming more familiar with
the task. Help messages become more detailed perhaps, under the
assumption that the user needs more help. Or, prompts can change
just to make the interaction more interesting.
Each form item and each menu has an internal prompt counter
that is reset to one each time the form or menu is entered.
Whenever the system uses a prompt, its associated prompt counter
is incremented. This is the mechanism supporting tapered
prompts.
For instance, here is a form with a form level prompt and
field level prompts:
<form id="tapered">
<block>
<prompt bargein="false">
Welcome to the ice cream survey.
</prompt>
</block>
<field name="flavor">
<grammar mode="voice">
<rule id="root" scope="public">
<one-of>
<item>vanilla </item>
<item>chocolate</item>
<item>strawberry</item>
</one-of>
</rule>
</grammar>
<prompt count="1">What is your favorite flavor?</prompt>
<prompt count="3">Say chocolate, vanilla, or strawberry.</prompt>
<help>Sorry, no help is available.</help>
</field>
</form>
A conversation using this form follows:
C: Welcome to the ice cream survey.
C: What is your favorite flavor? (the
"flavor" field’s prompt counter is 1)
H: Pecan praline.
C: I do not understand.
C: What is your favorite flavor? (the
prompt counter is now 2)
H: Pecan praline.
C: I do not understand.
C: Say chocolate, vanilla, or strawberry. (prompt counter is 3)
H: What if I hate those?
C: I do not understand.
C: Say chocolate, vanilla, or strawberry. (prompt counter is 4)
H: ...
When it is time to select a prompt, the prompt counter is
examined. The child prompt with the highest count attribute less
than or equal to the prompt counter is used. If a prompt has no
count attribute, a count of "1" is assumed.
A conditional prompt is one that is spoken only if its
condition is satisfied. In this example, a prompt is varied on
each visit to the enclosing form.
<form id="another_joke">
<var name="r" expr="Math.random()"/>
<field name="another" type="boolean">
<prompt cond="r < .50">
Would you like to hear another elephant joke?
</prompt>
<prompt cond="r >= .50">
For another joke say yes. To exit say no.
</prompt>
<filled>
<if cond="another">
<goto next="#pick_joke"/>
</if>
</filled>
</field>
</form>
When a prompt must be chosen, a set of prompts to be queued is
chosen according to the following algorithm:
- Form an ordered list of prompts consisting of all prompts in
the enclosing element in document order.
- Remove from this list all prompts whose cond evaluates to
false.
- Find the "correct count": the highest count among the prompt
elements still on the list less than or equal to the current
count value.
- Remove from the list all the elements that don't have the
"correct count".
All elements that remain on the list will be queued for
play.
The timeout attribute specifies the interval of silence
allowed while waiting for user input after the end of the last
prompt. If this interval is exceeded, the platform will throw a
noinput event. This attribute defaults to the value specified by
the timeout property (see Section
6.3.4).
The reason for allowing timeouts to be specified as prompt
attributes is to support tapered timeouts. For example, the user
may be given five seconds for the first input attempt, and ten
seconds on the next.
The prompt timeout attribute determines the noinput timeout
for the following input:
<prompt count="1">
Pick a color for your new Model T.
</prompt>
<prompt count="2" timeout="120s">
Please choose color of your new nineteen twenty four
Ford Model T. Possible colors are black, black, or
black. Please take your time.
</prompt>
If several prompts are queued before a field input, the
timeout of the last prompt is used.
A VoiceXML interpreter is at all times in one of two
states:
- waiting for input in a field item (such as
<field>, <record>, or <transfer>),
or
- transitioning between field items in response to an
input (including spoken utterances, dtmf key presses, and
input-related events such as a noinput or nomatch event) received
while in the waiting state. While in the transitioning state no
speech input is collected, accepted or interpreted. Consequently
root and document level speech grammars (such as defined in
<link>s) may not be active at all times. However, DTMF
input (including timing information) should be collected and
buffered in the transition state.
The waiting and transitioning states are related to the phases
of the Form Interpretation Algorithm as follows:
- the waiting state is entered in the collect phase of a field
item, and
- the transitioning state encompasses the process and select
phases, and the collect phase for non-field items (such as
<block>s).
This distinction of states is made in order to greatly
simplify the programming model. In particular, an important
consequence of this model is that the VoiceXML application
designer can rely on all executable content (such as the content
of <filled> and <block> elements) being run to
completion, because it is executed while in the transitioning
state, which may not be interrupted by input.
While in the transitioning state various prompts are queued,
either by the <prompt> element in executable content or by
the <prompt> element in field items. In addition, audio may
be queued by the fetchaudio attribute. The queued prompts and
audio are played either
- when the interpreter reaches the waiting state, at which
point the prompts are played and the interpreter listens for
input that matches one of the active grammars, or
- when the interpreter begins fetching a resource (such as a
document) for which fetchaudio was specified. In this case the
prompts queued before the fetchaudio are played to completion,
and then, if the resouce actually needs to be fetched (i.e. it is
not unexpired in the cache), the fetchaudio is played until the
fetch completes. The interpreter remains in the transitioning
state and no input is accepted during the fetch.
Before the interpreter exits all queued prompts are played to
completion. The interpreter remains in the transitioning state
and no input is accepted while the interpreter is exiting.
It is a permissible optimization to begin playing prompts
queued during the transitioning state before reaching the waiting
state, provided that correct semantics are maintained regarding
processing of the input audio received while the prompts are
playing, for example with respect to bargein and grammar
processing.
The following examples illustrate the operation of these rules
in some common cases.
Case 1
Typical non-fetching case: field, followed by executable
content (such as <block> and <filled>), followed by
another field.
in document d0
<field name="f0"/>
<block>
executable content e1
queues prompts {p1}
</block>
<field name="f2">
queues prompts {p2}
enables grammars {g2}
</field>
As a result of input received while waiting in field f0 the
following actions take place:
- in transitioning state
- execute e1 (without goto)
- queue prompts {p1}
- queue prompts {p2}
- in waiting state, simultaneously
- play prompts {p1,p2}
- enable grammars {g2}
- wait for input
Case 2
Typical fetching case: field, followed by executable content
(such as <block> and <filled>) ending with a
<goto> that specifies fetchaudio, ending up in a field in a
different document that is fetched from a server.
in document d0
<field name="f0"/>
<block>
executable content e1
queues prompts {p1}
ends with goto f2 in d1 with fetchaudio fa
</block>
in document d1
<field name="f2">
queues prompts {p2}
enables grammars {g2}
</field>
As a result of input received while waiting in field f0 the
following actions take place:
- in transitioning state
- execute e1
- queue prompts {p1}
- simultaneously
- fetch d1
- play prompts {p1} to completion and then play fa until fetch
completes
- queue prompts {p2}
- in waiting state, simultaneously
- play prompts {p2}
- enable grammars {g2}
- wait for input
Case 3
As in Case 2, but no fetchaudio is specified.
in document d0
<field name="f0"/>
<block>
executable content e1
queues prompts {p1}
ends with goto f2 in d1 (no fetchaudio specified)
</block>
in document d1
<field name="f2">
queues prompts {p2}
enables grammars {g2}
</field>
As a result of input received while waiting in field f0 the
following actions take place:
- in transitioning state
- execute e1
- queue prompts {p1}
- fetch d1
- queue prompts {p2}
- in waiting state, simultaneously
- play prompts {p1, p2}
- enable grammars {g2}
- wait for input
VoiceXML variables are in all respects equivalent to
ECMAScript variables: they are part of the same variable space.
VoiceXML variables can be used in a <script> just as
variables defined in a <script> can be used in VoiceXML.
Declaring a variable using <var> is equivalent to using a
'var' statement in a <script> element. <script> can
also appear everywhere that <var> can appear.
The variable naming convention is as in ECMAScript, but names
beginning with the underscore character ("_") and names ending
with a dollar sign ("$") are reserved for internal use. VoiceXML
variables, including field item variables, must not contain
ECMAScript reserve words. They must also follow ECMAScript rules
for referential correctness. For example, variable names must be
unique and their declaration must not include a dot - "var x.y"
is an illegal declaration in ECMAScript. Variable names which
violate ECMAScript rules cause an 'error.semantic' event to be
thrown.
Variables are declared by <var> elements:
<var name="home_phone"/>
<var name="pi" expr="3.14159"/>
<var name="city" expr="'Sacramento'"/>
They are also declared by form items:
<field name="num_tickets" type="number">
<prompt>How many tickets do you wish to purchase?</prompt>
</field>
Variables declared without an explicit initial value are
initialized to the ECMAScript undefined value. Variables must be
declared before being used either in VoiceXML or ECMAScript.
Variables declared using "var" in ECMAScript can be used in
VoiceXML, just as declared VoiceXML variables can be used in
ECMAScript. ECMAScript allows the use of undeclared variables;
however, because these variables are global, they must not be
used from VoiceXML. (VoiceXML implementations are free to
restrict the use of undeclared variables, even from within
ECMAScript blocks like <script>.). Explicit <var>
declarations in VoiceXML aid readibility and application flow
analysis.
In a form, the variables declared by <var> and those
declared by form items are initialized when the form is entered.
The initializations are guaranteed to take place in document
order, so that this, for example, is legal:
<form id="test">
<var name="one" expr="1"/>
<field name="two" expr="one+1" type="number"></field>
<var name="three" expr="two+1"/>
<field name="go_on" type="boolean">
<prompt>Say yes or no to continue</prompt>
</field>
<filled>
<goto next="#tally"/>
</filled>
</form>
When the user visits this <form>, the form’s
initialization first declares the variable one and sets its value
to 1. Then it declares the field item variable two and gives it
the value 2. Then the initialization logic declares the variable
three and gives it the value 3. The form interpretation algorithm
then enters its main interpretation loop and begins at the go_on
field.
5.1.2
Variable Scopes
Variables can be declared in following scopes:
| session |
These are read-only variables that pertain to an entire user
session. They are declared and set by the interpreter context.
New session variables cannot be declared by VoiceXML documents.
See Section 5.1.4. |
| application |
These are declared with <var> elements that are
children of the application root document's <vxml> element.
They are initialized when the application root document is
loaded. They exist while the application root document is loaded,
and are visible to the root document and any other loaded
application leaf document. |
| document |
These variables are declared with <var> elements that
are children of the document’s <vxml> element. They
are initialized when the document is loaded. They exist while the
document is loaded, and are visible only within that
document. |
| dialog |
Each dialog (<form> or <menu>) has a dialog scope
that exists while the user is visiting that dialog, and which is
visible to the element of that dialog. Dialog variables are
declared by <var> child elements of <form> and by the
various form item elements. The child <var> elements of
<form> are initialized when the form is first visited. The
<var> elements inside executable content are initialized
when the executable content is executed. The form item variables
are initialized when the form item is collected. |
| (anonymous) |
Each <block>, <filled>, and <catch> element
defines a new anonymous scope to contain variables declared in
that element. |
The following diagram shows the scope hierarchy:
Figure 7: The scope hierarchy.
The curved arrows in this diagram show that each scope
contains a pre-defined variable whose name is the same as the
scope that refers to the scope itself. This allows you for
example in the anonymous, dialog, and document scopes to refer to
a variable X in the document scope using
document.X. As another example, a <filled>'s
variable scope is an anonymous scope local to the <filled>,
whose parent variable scope is that of the <form>.
It is not recommended to use "session", "application",
"document", and "dialog" as the names of variables and form
items. While they are not reserved words, using them hides the
pre-defined variables with the same name because of ECMAScript
scoping rules used by VoiceXML.
Variables are referenced in cond and expr attributes:
<if cond="city == 'LA'">
<assign name="city" expr="'Los Angeles'"/>
<elseif cond="city == 'Philly'"/>
<assign name="city" expr="'Philadelphia'"/>
<elseif cond="city =='Constantinople'"/>
<assign name="city" expr="'Istanbul'"/>
</if>
<assign name="var1" expr="var1 + 1"/>
<if cond="i > 1">
<assign name="i" expr="i-1"/>
</if>
The expression language used in cond and expr is precisely
ECMAScript. Note that the cond operators "<", "<=", and
"&&" must be escaped in XML (to "<" and so on).
For clarity, examples in this document do not use XML
escapes.
Variable references match the closest enclosing scope
according to the scope chain given above. You can prefix a
reference with a scope name for clarity or to resolve ambiguity.
For instance to save the value of a form field item variable for
use later on in a document:
<assign name="document.ssn" expr="dialog.ssn"/>
If the application root document has a variable x, it is
referred to as application.x in non-root documents, and either
application.x or document.x in the application root document.
- session.telephone.ani
- Automatic Number Identification. This variable
provides the result from the Automatic Number Identification
service that provides the receiver of a telephone call with the
number of the calling phone. This information is provided only if
the service is supported, and is undefined otherwise.
- session.telephone.dnis
- Dialed Number Identification Service. This variable
provides the result from the Dialed Number Identification Service
that identifies for the receiver of a call the number that the
caller dialed. This information is provided only if the service
is supported, and is undefined otherwise.
- session.telephone.iidigits
- Information Indicator Digits. This variable provides
information about the originating line (e.g. payphone, cellular
service, special operator handling, prison) of the caller.
Telecordia publishes the complete list of II digits in Section 1
of each volume of the "Local Exchange Routing Guide". This
information is provided only if the service is supported, and is
undefined otherwise.
- session.telephone.uui
- User to User Information. This variable returns
supplementary information provided as part of an ISDN call set-up
from a calling party. This information is provided only if the
service is supported, and is undefined otherwise.
- session.telephone.rdnis
- Redirect Dialed Number Information Service. This
variable provides the number from which a call diversion or
transfer was invoked. This variable is undefined if the number is
unavailable. For example, suppose person A subscribes to a voice
messaging service, and forwards all calls to a voice server.
Person B then calls A and gets routed to the voice server. A
VoiceXML application on the voice server should see RDNIS as A's
number, while DNIS is the number of the voice server, and ANI is
B's number.
- session.telephone.redirect_reason
- Redirect Reason. This variable is a string that
indicates the reason the call was redirected to this server. This
variable is always available if session.telephone.rdnis is
available. It is undefined if session.telephone.rdnis is
undefined. The following reason codes are defined: "unknown",
"user-busy", "no-answer", "unavailable", "unconditional",
"time-of-day", "do-not-disturb", "deflection", "follow-me",
"out-of-service", "away".
Issues:
-
The session.telephone variable space may be deprecated in a
future version of this document in favor of the connection
variable space defined below. The connection variable space has
the advantages that it provides an extensible attribute space for
protocol-specific information while providing a generic core of
information that will be available over all protocols. The core
object attributes are designed to be independent of whether the
call was received or placed.
- session.connection.local.uri
- This variable is a URI which addresses the
local interpreter context device.
- session.connection.remote.uri
- This variable is a URI which addresses the
remote caller device. (For instance, a telephone device should be
addressed with a tel: URL syntax conforming to RFC 2806.)
- session.connection.protocol.name
- This variable is the name of the connection
protocol. The name also represents the subobject name for
protocol specific information. For instance, if
session.connection.protocol.name is 'q931',
session.connection.protocol.q931.uui might specify the
user-to-user information property of the connection.
-
session.connection.protocol.version
- This variable is the version of the connection
protocol.
Event names related to telephony (e.g.
telephone.disconnect.hangup, error.telephone.noauthorization) may
also be changed to be more agnostic to connection type.
- application.lastresult$
- This read-only variable holds information about the last
recognition to occur within this application. It is an array of
elements, where each element application.lastresult$[i]
represents a possible result through the following read-only
variables:
- application.lastresult$[i].confidence
- The confidence level for this interpretation from 0.0-1.0. A
value of 0.0 indicates minimum confidence, and a value of 1.0
indicates maximum confidence. More specific interpretation of a
confidence value is platform-dependent.
- application.lastresult$[i].utterance
- The raw string of words that were recognized for this
interpretation. The exact tokenization and spelling is
platform-specific (e.g. "five hundred thirty" or "5 hundred 30"
or even "530").
- application.lastresult$[i].inputmode
- For this interpretation,the mode in which user input was
provided: dtmf or voice.
- application.lastresult$[i].interpretation
- An ECMAscript variable containing the interpretation as
described in Section 3.1.5.
Interpretations are sorted by confidence score, from highest
to lowest. Different elements in application.lastresult$ will
always differ in their utterance, interpretation, or both.
The number of application.lastresult$ elements is guaranteed
to be greater than or equal to one and less than or equal to the
system property "maxnbest". If no results have been generated by
the system, then "application.lastresult$" shall be ECMAScript
undefined.
Additionally, application.lastresult$ itself contains the
properties confidence, utterance, inputmode, and interpretation
corresponding to those of the 0th element in the array.
All of the shadow variables described above are set
immediately after any recognition. When an application root
document is loaded, this variable is set to the value
undefined.
The following example show how application.lastresult$ can be
used in a field level <catch> to access a <link>
grammar recognition result and transition to different dialog
states depending on confidence:
<link event="menulinkevent">
<grammar src="./linkgrammar.grxml" type="application/grammar+xml"/>
</link>
<form>
...
<field>
...
<catch event="menulinkevent">
<if cond="application.lastresult$.confidence < 0.7">
<goto nextitem="confirmlinkdialog"/>
<else/>
<goto next="./main_menu.html"/>
</if>
</catch>
</field>
...
</form>
The platform throws events when the user does not respond,
doesn't respond intelligibly, requests help, etc. The interpreter
throws events if it finds a semantic error in a VoiceXML
document, or when it encounters a <throw> element. Events
are identified by character strings.
Each element in which an event can occur has a set of catch
elements, which include:
-
<catch>
-
<error>
-
<help>
-
<noinput>
-
<nomatch>
An element inherits the catch elements ("as if by copy") from
each of its ancestor elements, as needed. If a field, for
example, does not contain a catch element for nomatch, but its
form does, the form’s nomatch catch element is used. In
this way, common event handling behavior can be specified at any
level, and it applies to all descendents.
The "as if by copy" semantics for inheriting catch elements
implies that when a catch element is executed, variables are
resolved and thrown events are handled relative to the scope
where the original event originated, not relative to the scope
that contains the catch element. For example, consider a catch
element that is defined at document scope handling an event that
originated in a <field> within the document. In such a
catch element variable references are resolved relative to the
<field>'s scope, and if an event is thrown by the catch
element it is handled relative to the <field>. Similarly,
relative URL references in a catch element are resolved against
the active document and not relative to the document in which
they were declared.
The <throw> element throws an event. These can be the
pre-defined ones:
<throw event="nomatch"/>
<throw event="telephone.disconnect.hangup"/>
or application-defined events:
<throw event="com.att.portal.machine"/>
Attributes of <throw> are:
| event |
The event being thrown. |
| eventexpr |
An ECMAScript expression evaluating to the name of the event
being thrown. The 'event' attribute has precedence over
'eventexpr'. |
| message |
An message string providing additional context about the
event being thrown. For the pre-defined events thrown by the
platform, the value of the message is platform-dependent.
The message is available as the value of a variable within the
scope of the catch element, see below. |
| messageexpr |
An ECMAScript expression evaluating to the message string.
The 'message' attribute has precedence over 'messageexpr'. |
Unless explicited stated otherwise, VoiceXML does not specify
when events are thrown.
The catch element associates a catch with a document, dialog,
or form item. It contains executable content.
<form id="launch_missiles">
<field name="password">
<prompt>What is the code word?</prompt>
<grammar>
<rule id="root" scope="public">rutabaga</rule>
</grammar>
<help>It is the name of an obscure vegetable.</help>
<catch event="nomatch noinput" count="3">
<prompt>Security violation!</prompt>
<submit next="apprehend_felon" namelist="user_id"/>
</catch>
</field>
<block>
<goto next="#get_city"/>
</block>
</form>
The catch element's anonymous variable scope includes the
special variable _event which contains the name of the event that
was thrown. For example, the following catch element can handle
two types of events:
<catch event="event.foo event.bar">
<if cond="_event=='event.foo'">
<!-- Play this for event.foo events -->
<audio src="foo.wav"/>
<else/>
<!-- Play this for event.bar events -->
<audio src="bar.wav"/>
</if>
<!-- Continue with common handling for either event -->
</catch>
The _event variable is inspected to select the audio to play
based on the event that was thrown. The foo.wav file will be
played for event.foo events. The bar.wav file will be played for
event.bar events. The remainder of the catch element contains
executable content that is common to the handling of both event
types.
The catch element's anonymous variable scope also includes the
special variable _message which contains the value of the message
string from the corresponding <throw> element, or a
platform-dependent value for the pre-defined events raised by the
platform. If the thrown event does not specify a message, the
value of _message is ECMAScript undefined.
There are no inherent limitations on the executable context in
a <catch> element: execution proceeds as normal until the
interpreter exits. Consider the following example where the
application cleans up after a user hangup by submitting
information to a server:
<catch event="telephone.disconnect.hangup">
<submit namelist="myExit" next="http://mysite/exit.jsp"/>
</catch>
The document returned by the server is processed normally by
the interpreter until it reaches the first point in the document
when input or output is required. At that point, the interpreter
exits.
If a <catch> element contains a <throw> element
with the same event, then there may be an infinite loop:
<catch event="help">
<throw event="help"/>
</catch>
A platform could detect this situation and throw a semantic
error instead.
Attributes of <catch> are:
| event |
The event or events to catch. This may be an empty string
indicating that all events are to be caught. Alternatively, a
space-separated list of events may be specified, indicating that
this <catch> element catches all the events named in the
list. In such a case a separate event counter (see "count"
attribute) is maintained for each event. |
| count |
The occurrence of the event (default is 1). The count allows
you to handle different occurrences of the same event
differently. Each <form>, <menu> and form item
maintains a counter for each event that occurs while it is being
visited; these counters are reset each time the <menu> or
form item's <form> is re-entered. The form-level counters
are used in the selection of an event handler for events thrown
in a form-level <filled>. |
| cond |
An optional condition to test to see if the event may be
caught by this element. Defaults to true. |
The <error>, <help>, <noinput>, and
<nomatch> elements are shorthands for very common types of
<catch> elements.
The <error> element is short for <catch
event="error"> and catches all events of type error:
<error>
An error has occurred -- please call again later.
<exit/>
</error>
The <help> element is an abbreviation for <catch
event="help">:
<help>No help is available.</help>
The <noinput> element abbreviates <catch
event="noinput">:
<noinput>I didn't hear anything, please try again.</noinput>
And the <nomatch> element is short for <catch
event="nomatch">:
<nomatch>I heard something, but it wasn't a known city.</nomatch>
These elements take the attributes:
| count |
The event count (as in <catch>). |
| cond |
An optional condition to test to see if the event is caught
by this element (as in <catch>). Defaults to true. |
An element inherits the catch elements ("as if by copy") from
each of its ancestor elements, as needed. For example, if a
<field> element inherits a <catch> element from the
document
<catch event="event.foo">
<audio src="beep.wav"/>
</catch>
<form>
<field>
...
<nomatch>
<throw event="event.foo"/>
</nomatch>
</field>
</form>
then the <catch> element is implicitly copied into
<field> as if defined below:
<form>
<field>
...
<nomatch>
<throw event="event.foo"/>
</nomatch>
<catch event="event.foo">
<audio src="beep.wav"/>
</catch>
</field>
</form>
When an event is thrown, the scope in which the event is
handled and its enclosing scopes are examined to find the best
qualified catch element, according to the following
algorithm:
- Form an ordered list of catches consisting of all catches in
the current scope and all enclosing scopes (form item, form,
document, application root document, interpreter context),
ordered first by scope (starting with the current scope), and
then within each scope by document order.
- Remove from this list all catches whose event name does not
match the event being thrown or whose cond evaluates to
false.
- Find the "correct count": the highest count among the catch
elements still on the list less than or equal to the current
count value.
- Select the first element in the list with the "correct
count".
The name of a thrown event matches the catch element event
name if it is either an exact match or a prefix match. A prefix
match occurs when the catch element event attribute is a token
prefix of the name of the event being thrown, where the dot is
the token separator, all trailing dots are removed, and the empty
string matches everything. For example,
<catch event="telephone.disconnect">
will prefix match the event telephone.disconnect.transfer.
<catch event="com.example.myevent">
prefix matches com.example.myevent.event1.,
com.example.myevent. and com.example.myevent..event1 but not
com.example.myevents.event1. Finally,
<catch event="">
prefix matches all events.
Note that the catch element selection algorithm gives priority
to catch elements that occur earlier in a document over those
that occur later, but does not give priority to catch elements
that are more specific over those that are less specific.
Therefore is generally advisable to specify catch elements in
order from more specific to less specific. For example, it would
be advisable to specify catch elements for "error.foo" and
"error" in that order, as follows:
<catch event="error.foo">
...
</catch>
<catch event="error">
...
</catch>
If the catch elements were specified in the opposite order,
the catch element for "error.foo" would never be executed.
The interpreter is expected to provide implicit default catch
handlers for the noinput, help, nomatch, cancel, exit, and error
events if the author did not specify them.
The system default behavior of catch handlers for various
events and errors is summarized by the definitions below that
specify (1) whether any audio response is to be provided, and (2)
how execution is affected. Note: where an audio response is
provided, the actual content is platform dependent.
| Event Type |
Audio Provided |
Action |
| cancel |
no |
don’t reprompt |
| error |
yes |
exit interpreter |
| exit |
no |
exit interpreter |
| help |
yes |
reprompt |
| noinput |
no |
reprompt |
| nomatch |
yes |
reprompt |
| maxspeechtimeout |
yes |
reprompt |
| telephone.disconnect |
no |
exit interpreter |
| all others |
yes |
exit interpreter |
Specific platforms and locales will differ in the default
prompts presented.
There are pre-defined events and application-defined events.
Events are also subdivided into plain events (things that happen
normally), and error events (abnormal occurrences). The error
naming convention allows for multiple levels of granularity.
The pre-defined events are:
- cancel
- The user has requested to cancel playing of the current
prompt.
- telephone.disconnect.hangup
- The user has hung up.
- telephone.disconnect.transfer
- The user has been transferred unconditionally to another line
and will not return.
- exit
- The user has asked to exit.
- help
- The user has asked for help.
- noinput
- The user has not responded within the timeout interval.
- nomatch
- The user input something, but it was not recognized.
- maxspeechtimeout
- The user input was too long exceeding the 'maxspeechtimeout'
property.
The predefined errors are:
- error.badfetch
- The interpreter context throws this event when a fetch of a
document has failed and the interpreter context has
reached a place in the document interpretation where the fetch
result is required. Fetch failures result from missing
documents, malformed URIs, communications errors, timeouts,
security violations, or malformed documents.
- If the interpreter context has speculatively prefetched a
document and that document turns out not to be needed,
error.badfetch is not thrown. Likewise if the fetch of an
<audio> document fails and if there is a nested alternate
<audio> document whose fetch then succeeds, or if there is
nested alternate text, no error.badfetch occurs.
- When an interpreter context is transitioning to a new
document, and that document has been fetched but has syntax or
semantic errors, the interpreter context throws error.badfetch,
but again only at the point in time where the new document is
actually needed, not before.
- error.badfetch.http.<response code>
error.badfetch.protocol.<response code>
- In the case of a fetch failure, the interpreter context must
use a detailed event type telling which specific HTTP or other
protocol-specific response code was encountered. The value of the
response code for HTTP is defined in HTTP 1.1. This
allows applications to differentially treat a missing document
from a prohibited document, for instance. The value of the
response code for other protocols (such as HTTPS, RTSP, and so
on) is dependent upon the protocol.
- error.semantic
- A run-time error was found in the VoiceXML document, e.g. a
divide by 0, substring bounds error, or an undefined variable was
referenced.
- error.noauthorization
- The user is not authorized to perform the operation requested
(such as dialing an invalid telephone number, or one which the
user is not allowed to call).
- error.unsupported.format
- The requested resource has a format that is not supported by
the platform, e.g. an unsupported grammar format, audio file
format, object type, or media type.
- error.unsupported.language
- The platform does not support the language for either speech
synthesis or speech recognition.
- error.unsupported.element
- The platform does not support the given element. For
instance, if a platform does not implement <transfer>, it
must throw error.unsupported.transfer. This allows an author to
use event handling to adapt to different platform
capabilities.
Errors encountered during document loading, including
transport errors (no document found, HTTP status code 404, and so
on) and syntactic errors (no XML header, no <vxml> element,
etc) result in a badfetch error event raised in the calling
document, while errors after loading, such as semantic errors,
are raised in the document itself.
Application-specific error types should follow the following
format:
- error.com.mot.mix.noauth
- Access to personal profile information is not
authorized.
- error.com.ibm.portal.restricted
- The document tried to access a restricted resource.
Catches can catch specific events (cancel) or all those
sharing a prefix (error.unsupported).
Issues:
- The determination of a badfetch for all fetchable items
(grammars, prompts, VoiceXML documents, and objects) needs to be
clarified. For example, what is the behavior for grammar
documents? At which point is a grammar document considered
"fetched"? If it has a syntax error, is that a badfetch?
- if fetching takes place late, where is the error
handled?
- We are investigating methods of providing more information
about the badfetch in cases such as parse failures or
inappropriate retrievals (e.g. grammar document returned instead
of VoiceXML document). One method would be to encode further
information in the error name; for example
"error.badfetch.grammar.syntax". A limitation is that multiple
errors cannot be reported at the same time. An alternative method
we are investigating is to fill a session-level ECMAScript
variable with detailed error information.
Executable content refers to a block of procedural
logic. Such logic appears in:
-
The <block> form item.
-
The <filled> actions in forms and form items.
-
Event handlers (<catch>, <help>, et cetera).
This section covers the elements that can occur in executable
content.
This element declares a variable. It can occur in executable
content or as a child of <form> or <vxml>.
Examples:
<var name="phone" expr="6305551212"/>
<var name="y" expr="document.z+1"/>
If it occurs in executable content, it declares a variable in
the anonymous scope associated with the enclosing <block>,
<filled>, or catch element. This declaration is made only
when the <var> element is executed. If the variable is
already declared in this scope, subsequent declarations act as
assignments, as in ECMAScript.
If a <var> is a child of a <form> element, it
declares a variable in the dialog scope of the <form>. This
declaration is made during the form’s initialization phase
as described in Section 6.6.1. The <var> element is not a
form item, and so is not visited by the Form Interpretation
Algorithm’s main loop.
If a <var> is a child of a <vxml> element, it
declares a variable in the document scope. This declaration is
made when the document is initialized; initializations happen in
document order.
Attributes of <var> include:
| name |
The name of the variable that will hold the result. |
| expr |
The initial value of the variable (optional). If there is no
expr attribute, the variable retains its current value, if any.
Variables start out with the ECMAScript value undefined if they
are not given initial values. |
The <assign> element assigns a value to a variable:
<assign name="flavor" expr="'chocolate'"/>
<assign name="document.mycost" expr="document.mycost+14"/>
Attributes include:
| name |
The name of the variable being assigned to. |
| expr |
The new value of the variable. |
The <clear> element resets one or more form items.
Resetting includes:
Setting the form item variable to ECMAScript undefined.
Reinitializing the prompt counter and the event counters for
the form item.
For example:
<clear namelist="city state zip"/>
The attribute is:
| namelist |
The names of the form items to be reset. When not specified,
all form items in the current form are cleared. |
The <if> element is used for conditional logic. It has
optional <else> and <elseif> elements.
<if cond="total > 1000">
<prompt>This is way too much to spend.</prompt>
<throw event="com.xyzcorp.acct.toomuchspent"/>
</if>
<if cond="amount < 29.95">
<assign name="x" expr="amount"/>
<else/>
<assign name="x" expr="29.95"/>
</if>
<if cond="flavor == 'vanilla'">
<assign name="flavor_code" expr="'v'"/>
<elseif cond="flavor == 'chocolate'"/>
<assign name="flavor_code" expr="'h'"/>
<elseif cond="flavor == 'strawberry'"/>
<assign name="flavor_code" expr="'b'"/>
<else/>
<assign name="flavor_code" expr="'?'"/>
</if>
Prompts can appear in executable content, in their full
generality, except that the <prompt> count attribute is
meaningless. In particular, the cond attribute can be used in
executable content. Prompts may be wrapped with <prompt>
and </prompt>, or represented using PCDATA. Wherever
<prompt> is allowed, the PCDATA xyz is interpreted
exactly as if it had appeared as
<prompt>xyz</prompt>.
<nomatch count="1">
To open the pod bay door, say your code phrase clearly.
</nomatch>
<nomatch count="2">
<prompt>
This is your <emphasis>last</emphasis> chance.
</prompt>
</nomatch>
<nomatch count="3">
Entrance denied.
<exit/>
</nomatch>
The FIA expects a catch element to queue appropriate prompts
in the course of handling an event. Therefore, the FIA does not
generally perform the normal selection and queuing of prompts on
the next iteration following the execution of a catch element.
However, the FIA does perform normal selection and queueing of
prompts after the execution of a catch element (<catch>,
<error>, <help>, <noinput>, <nomatch>) in
two cases:
- if the catch element ends by executing a <goto> to
another dialog; in this case the new dialog needs to be
guaranteed that its initial prompt remains intact and cannot be
suppressed or replaced by a referring dialog; or
- if a <reprompt> is executed in the catch to request
that the subsequent prompts be played.
In these two cases, after the FIA selects the next form item
to visit, it performs normal prompt processing, including
selecting and queuing the form item's prompts and incrementing
the form item's prompt counter.
For example, this noinput catch expects the next form item
prompt to be selected and played:
<field name="want_ice_cream" type="boolean">
<prompt>Do you want ice cream for dessert?</prompt>
<prompt count="2">
If you want ice cream, say yes.
If you don’t want ice cream, say no.
</prompt>
<noinput>
I could not hear you.
<!-- Cause the next prompt to be selected and played. -->
<reprompt/>
</noinput>
</field>
A quiet user would hear:
C: Do you want ice cream for dessert?
H: (silence)
C: I could not hear you.
C: If you want ice cream, say yes. If you don’t want ice
cream, say no.
H: (silence)
C: I could not hear you.
C: If you want ice cream, say yes. If you don’t want ice
cream, say no.
H: No
If there were no <reprompt>, the user would instead
hear:
C: Do you want ice cream for dessert?
H: (silence)
C: I could not hear you.
H: (silence)
C: I could not hear you.
H: No
Note that a consequence of skipping the prompt selection phase
as described above is that the prompt counter of the form item
selected by the FIA after the execution of a catch element (that
does not execute a <reprompt> or <goto>) will not be
incremented.
Also note that the prompt selection phase following the
execution of a catch element (that does not execute a
<reprompt> or <goto>) is skipped even if the form
item selected by the FIA is different from the previous form
item.
The <goto> element is used to;
-
transition to another form item in the current form,
-
transition to another dialog in the current document, or
-
transition to another document.
To transition to another form item, use the nextitem
attribute, or the expritem attribute if the form item name is
computed using an ECMAScript expression:
<goto nextitem="ssn_confirm"/>
<goto expritem="(type==12)? 'ssn_confirm' : 'reject'"/>
To go to another dialog in the same document, use next (or
expr) with only a URI fragment:
<goto next="#another_dialog"/>
<goto expr="'#' + 'another_dialog'"/>
To transition to another document, use next (or expr) with a
URI:
<goto next="http://flight.example.com/reserve_seat"/>
<goto next="./special_lunch#wants_vegan"/>
The URI may be absolute or relative to the current document.
You may specify the starting dialog in the next document using a
fragment that corresponds to the value of the id attribute of a
dialog. If no fragment is specified, the first dialog in that
document is chosen.
Note that transitioning to another dialog in the current
document causes the old dialog’s variables to be lost, even
in the case where a dialog is transitioning to itself.
Transitioning to another document using an absolute or relative
URI will likewise drop the old document level variables, even if
the new document is the same one that is making the transition.
However, document variables are retained when transitioning to an
empty URI reference with a fragment identifier. For example, the
following statements behave differently in a document with the
URI http://someco.example.com/index.vxml:
<goto next="#foo"/>
<goto next="http://someco.example.com/index.vxml#foo"/>
According to RFC
2396, the fragment identifier (the part after the '#') is not
part of a URI and transitioning to empty URI references plus
fragment identifiers should never result in a new document fetch.
Therefore "#foo" in the first statement is an empty URI reference
with a fragment identifier and document variables are retained.
In the second statement "#foo" is part of a relative URI and the
document variables are lost. If you want data to persist across
multiple documents, store data in the application scope.
Attributes of <goto> are:
| next |
The URI to which to transition. |
| expr |
An ECMAScript expression that yields the URI. The 'next'
attribute has precedence over 'expr'. |
| nextitem |
The name of the next form item to visit in the current form.
'next' and 'expr' attributes have precedence over
'nextitem'. |
| expritem |
An ECMAScript expression that yields the name of the next
form item to visit. The 'nextitem' attribute has precedence over
'expritem'. |
| fetchaudio |
See Section 6.1. This defaults to the
fetchaudio property. |
| fetchhint |
See Section 6.1. This defaults to the
documentfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
documentmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
documentmaxstale property. |
The <submit> element is similar to <goto> in that
it results in a new document being obtained. Unlike <goto>,
it lets you submit a list of variables to the document server via
an HTTP GET or POST request. For example, to submit a set of form
items to the server you might have:
<submit next="log_request" method="post"
namelist="name rank serial_number"
fetchtimeout="100s" fetchaudio="audio/brahms2.wav"/>
Attributes of <submit> include:
| next |
The URI to which the query is submitted. |
| expr |
Like next, except that the URI is dynamically determined by
evaluating the given ECMAScript expression. One of next or expr
is required. |
| namelist |
The list of variables to submit. By default, all the named
field item variables are submitted. If a namelist is supplied, it
may contain individual variable references which are submitted
with the same qualification used in the namelist. Declared
VoiceXML and ECMAScript variables can be referenced. |
| method |
The request method: get (the default) or post. |
| enctype |
The media encoding type of the submitted document. The
default is application/x-www-form-urlencoded. Interpreters must
also support multipart/form-data and may support additional
encoding types. |
| fetchaudio |
See Section 6.1. This defaults to the
fetchaudio property. |
| fetchhint |
See Section 6.1. This defaults to the
documentfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
documentmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
documentmaxstale property. |
If an ECMAScript object o is the target of a submit then all
its (ECMAScript) fields f1, f2, ... are submitted using the names
o.f1, o.f2, etc.
If a <submit> contains a variable which references
recorded audio but does not contain an ENCTYPE of
multipart/form-data, the behavior is not specified. It is
probably inappropriate to attempt to URL-encode large quantities
of data.
Returns control to the interpreter context which determines
what to do next.
<exit/>
This element differs from <return> in that it terminates
all loaded documents, while <return> returns from a
<subdialog> invocation. If the <subdialog> caused a
new document (or application) to be invoked, then <return>
will cause that document to be terminated, but execution will
resume after the <subdialog>.
Note that once <exit> returns control to the interpreter
context, the interpreter context is free to do as it wishes. It
may play a top level menu for the user, drop the call, or
transfer the user to an operator, for example.
Attributes include:
| expr |
A return expression (e.g. "0", or "'oops!'"). |
| namelist |
Variable names to be returned to interpreter context. The
default is to return no variables; this means the interpreter
context will receive an empty ECMAScript object. |
The <exit> element does not throw an "exit" event.
Return ends execution of a subdialog and returns control and
data to a calling dialog. The attributes are:
| event |
Return, then throw this event. |
| namelist |
Variable names to be returned to calling dialog. The default
is to return no variables; this means the caller will receive an
empty ECMAScript object. |
In returning from a subdialog, an event can be thrown at the
invocation point, or data is returned as an ECMAScript object. A
return element that is encountered when not executing as a
subdialog throws a semantic error. The example below shows an
event propagated from a subdialog to its calling dialog when the
subdialog fails to obtain a recognizable result. It also shows
data returned under normal conditions.
<form>
<subdialog name="result" src="#getssn">
<nomatch>
<!-- a no match event that is returned by the
subdialog indicates that a valid social security
number could not be matched. -->
<goto next="http://myservice.example.com/ssn-problems.vxml"/>
</nomatch>
<filled>
<submit namelist="result.ssn"
next="http://myservice.example.com/cgi-bin/process"/>
</filled>
</subdialog>
</form>
Subdialog to get social security number
<form id="getssn">
<field name="ssn">
<grammar src="http://grammarlib/ssn.grxml"
type="application/grammar+xml"/>
<prompt> Please say social security number.</prompt>
<nomatch count=3>
<return event="nomatch"/>
</nomatch>
<filled>
<return namelist="ssn"/>
</filled>
</field>
</form>
The subdialog event handler for <nomatch> is triggered
on the third failure to match; when triggered, it returns from
the subdialog, and includes the nomatch event to be thrown in the
context of the calling dialog. In this case, the calling dialog
will execute its <nomatch> handler, rather than the
<filled> element, where the resulting action is to execute
a <goto> element. Under normal conditions, the
<filled> element of the subdialog is executed after a
recognized social security number is obtained, and then this
value is returned to the calling dialog, and is accessible as
result.ssn.
Causes the interpreter context to disconnect from the user. As
a result, the interpreter context will throw a
telephone.disconnect.hangup event, which may be caught to do
cleanup processing, e.g.
<disconnect/>
A <disconnect> differs from an <exit> in that it
forces the interpreter context to drop the call.
The <script> element allows the specification of a block
of client-side scripting language code, and is analogous to the
HTML <SCRIPT> element. For example, this document has a
script that computes a factorial.
<?xml version="1.0"?>
<vxml version="2.0">
<script> <![CDATA[
function factorial(n)
{
return (n <= 1)? 1 : n * factorial(n-1);
}
]]> </script>
<form id="form">
<field name="fact" type="number">
<prompt>
Tell me a number and I'll tell you its factorial.
</prompt>
<filled>
<prompt>
<value expr="fact"/> factorial is
<value expr="factorial(fact)"/>
</prompt>
</filled>
</field>
</form>
</vxml>
A <script> element may occur in the <vxml> and
<form> elements, or in executable content (in
<filled>, <if>, <block>, <catch>, or the
short forms of <catch>). Scripts in the <vxml>
element are evaluated just after the document is loaded, along
with the <var> elements, in document order. Scripts in the
<form> element are evaluated once in document order, along
with <var> elements and form item variables, when execution
moves into the <form> element. A <script> element in
executable content is executed, like other executable elements,
as it is encountered.
The <script> element has the following attributes:
| src |
The URI specifying the location of the script, if it is
external. |
| charset |
The character encoding of the script designated by src. UTF-8
and UTF-16 encodings of 10646 must be supported (as in XML) and other encodings, as defined in the IANA
character set registry, may be supported. The default value
is UTF-8. |
| fetchhint |
See Section 6.1. This defaults to the
scriptfetchhint property. |
| fetchtimeout |
See Section 6.1. This defaults to the
fetchtimeout property. |
| maxage |
See Section 6.1. This defaults to the
scriptmaxage property. |
| maxstale |
See Section 6.1. This defaults to the
scriptmaxstale property. |
The VoiceXML <script> element (unlike the HTML
<script> element) does not have a type attribute;
ECMAScript is the required scripting language for VoiceXML. Each
<script> element is executed in the scope of its containing
element; i.e., it does not have its own scope.
Here is a time-telling service with a block containing a
script that initializes time variables in the dialog scope of a
form:
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<var name="hours"/>
<var name="minutes"/>
<var name="seconds"/>
<block>
<script>
var d = new Date();
hours = d.getHours();
minutes = d.getMinutes();
seconds = d.getSeconds();
</script>
</block>
<field name="hear_another" type="boolean">
<prompt>
The time is <value expr="hours"/> hours,
<value expr="minutes"/> minutes, and
<value expr="seconds"/> seconds.
</prompt>
<prompt>Do you want to hear another time?</prompt>
<filled>
<if cond="hear_another">
<clear/>
</if>
</filled>
</field>
</form>
</vxml>
The content of a <script> element is evaluated in the
same scope as a <var> element (see 5.1.2 Variable Scopes and 5.3.1 VAR).
The ECMAScript scope chain (see section 10.1.4 in http://www.ecma.ch/ecma1/STAND/ECMA-262.htm)
is set up so that variables declared either with <var> or
inside <script> are put into the scope associated with the
element in which the <var> or <script> element
occurs. For example, the variable declared in a <script>
element under a <form> element has a dialog scope, and can
be accessed as a dialog scope variable as follows:
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<script>
var now = new Date(); <!-- this has a dialog scope-->
</script>
<var name="seconds" expr="now.getSeconds()"/> <!-- this has a dialog scope-->
<block>
<var name="now" expr="new Date()"/> <!-- this has an anonymous scope -->
<script>
var current = now.getSeconds(); <!-- "now" in the anonymous scope -->
var approx = dialog.now.getSeconds(); <!-- "now" in the dialog scope -->
</script>
</block>
</form>
</vxml>
All variables must be declared before being referenced by
ECMAScript scripts, or by VoiceXML elements.
The <log> element allows an application to generate a
debug message which a developer can use to help in application
development.
The <log> element may contain any combination of text
and <value> elements. The generated message consists of the
concatenation of the text and the string form of the value of the
"expr" attribute of the <value> elements.
The manner in which the message is displayed or logged is
platform-dependent. Platforms are not required to preserve white
space or formating controls.
ECMAScript expressions in <log> must be evaluated in
document order. The use of the <log> element should have no
other side-effects on interpretation.
<log>The card number was <value expr="card_num"/>?</log>
The <log> element has the following attributes:
| label |
A string which may be used, for example, to indicate the
purpose of the log. It is added as a separate message following
document order. |
| expr |
An ECMAscript expression evaluating to a string. The string
is added as a separate message following document order. |
A VoiceXML interpreter context needs to fetch VoiceXML
documents, and other resources, such as audio files, grammars,
scripts, and objects. Each fetch of the content associated with a
URI is governed by the following attributes:
| fetchtimeout |
The interval to wait for the content to be returned before
throwing an error.badfetch event. If not specified, a value
derived from the innermost fetchtimeout property is used. |
| fetchhint |
Defines when the interpreter context should retrieve content
from the server. prefetch indicates a file may be downloaded when
the page is loaded, whereas safe indicates a file that should
only be downloaded when actually needed. If not specified, a
value derived from the innermost relevant *fetchhint property is
used. |
| maxage |
Indicates that the document is willing to use content whose
age is no greater than the specified time in seconds. The
document is not willing to use stale content, unless maxstale is
also provided. If not specified, a value derived from the
innermost relevant *maxage property, if present, is used. |
| maxstale |
Indicates that the document is willing to use content that
has exceeded its expiration time. If maxstale is assigned a
value, then the document is willing to accept content that has
exceeded its expiration time by no more than the specified number
of seconds. If not specified, a value derived from the innermost
relevant *maxstale property, if present, is used. |
When content is fetched from a URI, the fetchtimeout attribute
determines how long to wait for the content (starting from the
time when the resource is needed), and the fetchhint attribute
determines when the content is fetched. The caching policy for a
VoiceXML interpreter context utilizes the maxage and maxstale
attributes and is explained in more detail below.
The fetchhint attribute, in combination with the various
fetchhint properties, is merely a hint to the interpreter context
about when it may schedule the fetch of a resource. Telling
the interpreter context that it may prefetch a resource does not
require that the resource be prefetched; it only suggests that
the resource may be prefetched. However, the interpreter
context is always required to honor the safe fetchhint.
When transitioning from one dialog to another, through either
a <subdialog>, <goto>, <submit>, <link>,
or <choice> element, there are additional rules that affect
interpreter behavior. If the referenced URI names a document
(e.g. "doc#dialog") or query data is provided (through POST or
GET), then a new document is obtained (either from a local cache
or from a server). When it is obtained, the document goes through
its initialization phase (i.e., obtaining and initializing a new
application root document if needed, initializing document
variables, and executing document scripts). The requested dialog
(or first dialog if none is specified) is then initialized and
execution of the dialog begins. If the referenced URI names only
a fragment (e.g. "#dialog") then no document is obtained, and no
initialization of the document is performed. The requested dialog
is processed as before.
Elements that fetch VoiceXML documents also support the
following additional attribute:
| fetchaudio |
The URI of the audio clip to play while the fetch
is being done. If not specified, the fetchaudio property is used,
and if that property is not set, no audio is played during the
fetch. The fetching of the audio clip is governed by the
audiofetchhint, audiomaxage, audiomaxstale, and fetchtimeout
properties in effect at the time of the fetch. The playing of the
audio clip is governed by the fetchaudiodelay, and
fetchaudiominimum properties in effect at the time of the
fetch. |
The fetchaudio attribute is useful for enhancing a user
experience when there may be noticeable delays while the next
document is retrieved. This can be used to play background music,
or a series of announcements. When the document is retrieved, the
audio file is interrupted if it is still playing.
The VoiceXML interpreter context, like HTML visual browsers,
can use caching to improve performance in fetching documents and
other resources; audio recordings (which can be quite large) are
as common to VoiceXML documents as images are to HTML pages. In a
visual browser it is common to include end user controls to
update or refresh content that is perceived to be stale. This is
not the case for the VoiceXML interpreter context, since it lacks
equivalent end user controls. Thus enforcement of cache refresh
is at the discretion of the document through appropriate use of
the maxage, and maxstale attributes.
The caching policy used by the VoiceXML interpreter context
must adhere to the cache correctness rules of HTTP 1.1 (RFC2616). In
particular, the Expires and Cache-Control headers must be
honored. The following algorithm summarizes these rules and
represents the interpreter context behavior when requesting a
resource:
- If the resource is not present in the cache, fetch it from
the server using get.
- If the resource is in the cache,
- If a maxage value is provided,
- If age of the cached resource <= maxage,
- If the resource has expired,
- Otherwise, use the cached copy.
- Otherwise, fetch it from the server using get.
- Otherwise,
- If the resource has expired,
- Otherwise, use the cached copy.
The "maxstale check" is:
- If maxstale is provided,
- If cached copy has exceeded its expiration time by no more
than maxstale seconds, then use the cached copy.
- Otherwise, fetch it from the server using get.
- Otherwise, fetch it from the server using get.
Note: it is an optimization to perform a "get if modified" on
a document still present in the cache when the policy requires a
fetch from the server.
While the maxage and maxstale attributes are drawn from and
directly supported by HTTP 1.1, some resources may be addressed
by URIs that name protocols other than HTTP. If the protocol does
not support the notion of resource age, the interpreter context
shall compute a resource's age from the time it was received. If
the protocol does not support the notion of resource staleness,
the interpreter context shall consider the resource to have
expired immediately upon receipt.
6.1.2.1 Controlling the Caching Policy
VoiceXML allows the author to control the caching policy for
each use of each resource.
Each resource-related element may specify maxage and maxstale
attributes. Setting maxage to a non-zero value can be used to get
a fresh copy of a resource that may not have yet expired in the
cache. A fresh copy can be unconditionally requested by setting
maxage to zero.
Using maxstale enables the author to state that an expired
copy of a resource, that is not too stale (according to the rules
of HTTP 1.1), may be used. This can improve performance by
eliminating a fetch that would otherwise be required to get a
fresh copy. It is especially useful for authors who may not have
direct server-side control of the expiration dates of large
static files.
Prefetching is an optional feature that an interpreter context
may implement to obtain a resource before it is needed. A
resource that may be prefetched is identified by an element whose
fetchhint attribute equals "prefetch". When an interpreter
context does prefetch a resource, it must ensure that the
resource fetched is precisely the one needed. In particular, if
the URI is computed with an expr attribute, the interpreter
context must not move the fetch up before any assignments to the
expression's variables. Likewise, the fetch for a <submit>
must not be moved prior to any assignments of the namelist
variables.
The expiration status of a resource must be checked on each
use of the resource, and, if its fetchhint attribute is
"prefetch", when it is prefetched. The check must follow the
caching policy specified in Section 6.1.2.
The "http" URI protocol must be supported by VoiceXML
platforms, the "https" protocol should be supported and other URI
protocols may be supported.
The <meta> element specifies meta-data, as in HTML,
which is data about the document rather than the document’s
content. There are two types of <meta>. The first type
specifies a meta-data property of the document as a whole. For
example to specify the maintainer of a VoiceXML document:
<?xml version="1.0"?>
<vxml version="2.0">
<meta name="maintainer" content="jpdoe@anycompany.example.com"/>
...
</vxml>
The interpreter could use this information, for example, to
compose and email an error report to the maintainer.
VoiceXML does not specify required meta-data properties, but
the following are recommended:
| author |
Information describing the author. |
| copyright |
A copyright notice. |
| description |
A description of the document for search
engines. |
| keywords |
Keywords describing the document. |
| maintainer |
The document maintainer’s email
address. |
| robots |
Directives to search engine web robots. |
The second type of <meta> specifies HTTP response
headers. In the following example, the first <meta> element
sets an expiration date that prevents caching of the document;
the second <meta> element sets the Date header.
<?xml version="1.0"?>
<vxml version="2.0">
<meta http-equiv="Expires" content="0"/>
<meta http-equiv="Date" content="Thu, 12 Dec 2000 23:27:21 GMT"/>
...
</vxml>
Attributes of <meta> are:
| name |
The name of the meta-data property. |
| content |
The value of the meta-data property. |
| http-equiv |
The name of an HTTP response header. Either name
or http-equiv must be specified, not both. |
The <property> element sets a property value. Properties
are used to set values that affect platform behavior, such as the
recognition process, timeouts, caching policy, etc.
Properties may be defined for the whole application, for the
whole document at the <vxml> level, for a particular dialog
at the <form> or <menu> level, or for a particular
form item. Properties apply to their parent element and all the
descendants of the parent. A property at a lower level overrides
a property at a higher level. Properties specified in the
application root document provide default values for properties
in every document in the application; properties specified in an
individual document override property values specified in the
application root document.
In some cases, <property> elements specify default
values for element attributes, such as timeout or bargein. For
example, to turn off bargein by default for all the prompts in a
particular form:
<form id="no_bargein_form">
<property name="bargein" value="false"/>
<block>
<prompt>
This introductory prompt cannot be barged into.
</prompt>
<prompt>
And neither can this prompt.
</prompt>
<prompt bargein="true">
But this one <emphasis>can</emphasis> be barged into.
</prompt>
</block>
...
</form>
An interpreter context is free to provide platform-specific
properties. For example, to ensure that one second of
silence is prepended in front of each recording made by a
particular document:
<?xml version="1.0"?>
<vxml version="2.0">
<property name="com.example.acme.endpointing.record_init_silence" value="1s"/>
... dialogs that make recordings go here ...
</vxml>
Platform-specific properties introduce
incompatibilities. To minimize them, the following
interpreter context guidelines are strongly recommended:
The generic speech recognizer properties mostly are taken from
the Java Speech API (see
http://
www.javasoft.com/products/java-media/speech/index.html):
| confidencelevel |
The speech recognition confidence level, a float value in the
range of 0.0 to 1.0. Results are rejected (a nomatch event is
thrown) when the engine’s confidence in its interpretation
is below this threshold. A value of 0.0 means minimum confidence
is needed for a recognition, and a value of 1.0 requires maximum
confidence. The default value is 0.5. |
| sensitivity |
Set the sensitivity level. A value of 1.0 means that it is
highly sensitive to quiet input. A value of 0.0 means it is least
sensitive to noise. The default value is 0.5. |
| speedvsaccuracy |
A hint specifying the desired balance between speed vs.
accuracy. A value of 0.0 means fastest recognition. A value of
1.0 means best accuracy. The default is value 0.5. |
| completetimeout |
The length of silence required following user speech before
the speech recognizer finalizes a result (either accepting it or
throwing a nomatch event). The complete timeout is used when the
speech is a complete match of an active grammar. By
contrast, the incomplete timeout is used when the speech is an
incomplete match to an active grammar.
A long complete timeout value delays the result completion and
therefore makes the computer's response slow. A short complete
timeout may lead to an utterance being broken up inappropriately.
Reasonable complete timeout values are typically in the range of
0.3 seconds to 1.0 seconds. The default is
platform-dependent. See Appendix D.
|
| incompletetimeout |
The required length of silence following user speech after
which a recognizer finalizes a result. The incomplete
timeout applies when the speech prior to the silence is an
incomplete match of all active grammars. In this case, once
the timeout is triggered, the partial result is rejected (with a
nomatch event).
The incomplete timeout also applies when the speech prior to
the silence is a complete match of an active grammar, but where
it is possible to speak further and still match the
grammar. By contrast, the complete timeout is used when the
speech is a complete match to an active grammar and no further
words can be spoken.
A long incomplete timeout value delays the result completion
and therefore makes the computer's response slow. A short
incomplete timeout may lead to an utterance being broken up
inappropriately.
The incomplete timeout is usually longer than the complete
timeout to allow users to pause mid-utterance (for example, to
breathe). See Appendix D.
|
| maxspeechtimeout |
The maximum duration of user speech. If this time elapsed
before the user stops speaking, the event "maxspeechtimeout" is
thrown. The default duration is platform-dependent.
|
Several generic properties pertain to DTMF grammar
recognition:
| interdigittimeout |
The inter-digit timeout value to use when
recognizing DTMF input. The default is platform-dependent. See Appendix D. |
| termtimeout |
The terminating timeout to use when recognizing
DTMF input. The default value is "0s". Appendix D. |
| termchar |
The terminating DTMF character for DTMF input
recognition. The default value is "#". See Appendix D. |
These properties apply to the fundamental platform prompt and
collect cycle:
| bargein |
The bargein attribute to use for prompts. Setting
this to true allows barge-in by default. Setting it to false
disallows barge-in. The default value is "true". |
| bargeintype |
Sets the type of bargein to be energy, speech, or
recognition. Default is platform-specific. See Section 4.1.5.1. |
| timeout |
The time after which a noinput event is thrown by
the platform. The default value is platform-dependent. See Appendix D. |
These properties pertain to the fetching of new documents and
resources:
| audiofetchhint |
This tells the platform whether or not it can
attempt to optimize dialog interpretation by pre-fetching audio.
The value is either safe to say that audio is only fetched when
it is needed, never before; or prefetch to permit, but not
require the platform to pre-fetch the audio. The default value is
prefetch. |
| audiomaxage |
Tells the platform the maximum acceptable age, in
seconds, of cached audio resources. The default is
platform-specific. |
| audiomaxstale |
Tells the platform the maximum acceptable
staleness, in seconds, of expired cached audio resources. The
default is platform-specific. |
| documentfetchhint |
Tells the platform whether or not documents may
be pre-fetched. The value is either safe (the default), or
prefetch. |
| documentmaxage |
Tells the platform the maximum acceptable age, in
seconds, of cached documents. The default is
platform-specific. |
| documentmaxstale |
Tells the platform the maximum acceptable
staleness, in seconds, of expired cached documents. The default
is platform-specific. |
| grammarfetchhint |
Tells the platform whether or not grammars may be
pre-fetched. The value is either prefetch (the default), or
safe. |
| grammarmaxage |
Tells the platform the maximum acceptable age, in
seconds, of cached grammars. The default is
platform-specific. |
| grammarmaxstale |
Tells the platform the maximum acceptable
staleness, in seconds, of expired cached grammars. The default is
platform-specific. |
| objectfetchhint |
Tells the platform whether the URI contents for
<object> may be pre-fetched or not. The values are prefetch
(the default), or safe. |
| objectmaxage |
Tells the platform the maximum acceptable age, in
seconds, of cached objects. The default is
platform-specific. |
| objectmaxstale |
Tells the platform the maximum acceptable
staleness, in seconds, of expired cached objects. The default is
platform-specific. |
| scriptfetchhint |
Tells whether scripts may be pre-fetched or not.
The values are prefetch (the default), or safe. |
| scriptmaxage |
Tells the platform the maximum acceptable age, in
seconds, of cached scripts. The default is
platform-specific. |
| scriptmaxstale |
Tells the platform the maximum acceptable
staleness, in seconds, of expired cached scripts. The default is
platform-specific. |
| fetchaudio |
The URI of the audio to play while waiting for a
document to be fetched. The default is not to play any audio
during fetch delays. There are no fetchaudio properties for
audio, grammars, objects, and scripts. The fetching of the audio
clip is governed by the audiofetchhint, audiomaxage,
audiomaxstale, and fetchtimeout properties in effect at the time
of the fetch. The playing of the audio clip is governed by the
fetchaudiodelay, and fetchaudiominimum properties in effect at
the time of the fetch. |
|
fetchaudiodelay
|
The time interval to wait at the start of a fetch delay before
playing the fetchaudio source. The default interval is
platform-dependent, e.g. "2s". The idea is that when a
fetch delay is short, it may be better to have a few seconds of
silence instead of a bit of fetchaudio that is immediately cut
off.
|
|
fetchaudiominimum
|
The minimum time interval to play a fetchaudio source, once
started, even if the fetch result arrives in the meantime.
The default is platform-dependent, e.g., "5s". The idea is
that once the user does begin to hear fetchaudio, it should not
be stopped too quickly.
|
| fetchtimeout |
The timeout for fetches. The default value is
platform-dependent. |
| inputmodes |
This property determines which input modality to
use. The input modes to enable: dtmf and voice. On platforms that
support both modes, inputmodes defaults to "dtmf voice". To
disable speech recognition, set inputmodes to "dtmf". To disable
DTMF, set it to "voice". One use for this would be to turn off
speech recognition in noisy environments. Another would be to
conserve speech recognition resources by turning them off where
the input is always expected to be DTMF. |
|
universals
|
Production-grade applications often need to define their own
universal command grammars, e.g., to increase application
portability or to provide a distinctive interface.
They specify new universal command grammars with <link>
elements. They turn off the default grammars with this
property. Default catch handlers are not affected by this
property.
The value "none" is the default, and means that all platform
default universal command grammars are disabled. The value "all"
turns them all on. Individual grammars are enabled by listing
their names separated by spaces. For instance "cancel exit help"
is equivalent to "all".
|
|
maxnbest
|
This property controls the maximum size of the
"application.lastresult$" array; the array is constrained to be
no larger than the value specified by 'maxnbest'. This property
has a minimum value of 1. The default value is 1.
|
Our last example shows several of these properties used at
multiple levels.
<?xml version="1.0"?>
<vxml version="2.0">
<!-- set default characteristics for page -->
<property name="caching" value="safe"/>
<property name="audiofetchhint" value="safe"/>
<property name="confidence" value="0.75"/>
<form>
<!-- override defaults for this form only -->
<property name="confidence" value="0.5"/>
<property name="bargein" value="false"/>
<grammar src="address_book.grxml" type="application/grammar+xml"/>
<block>
<prompt> Welcome to the Voice Address Book </prompt>
</block>
<initial name="start">
<!-- override default timeout value -->
<property name="timeout" value="5s"/>
<prompt> Who would you like to call? </prompt>
</initial>
<field name="person">
<prompt>
Say the name of the person you would like to call.
</prompt>
</field>
<field name="location">
<prompt>
Say the location of the person you would like to call.
</prompt>
</field>
<field name="confirm" type="boolean">
<!-- Use actual utterances to playback recognized words,
rather than returned slot values -->
<prompt>
You said to call <value expr="person$.utterance"/>
at <value expr="location$.utterance"/>.
Is this correct?
</prompt>
<filled>
<if cond="confirm">
<submit namelist="person location"
next="http://www.messagecentral.example.com/voice/make_call" />
</if>
<clear/>
</filled>
</field>
</form>
</vxml>
The <param> element is used to specify values that are
passed to subdialogs or objects. It is modeled on the HTML
<PARAM> element. Its attributes are:
| name |
The name to be associated with this parameter
when the object or subdialog is invoked. |
| expr |
An expression that computes the value associated
with name. |
| value |
Associates a literal string value with name. |
| valuetype |
One of data or ref, by default data; used to
indicate to an object if the value associated with name is data
or a URI (ref). This is not used for <subdialog>. |
| type |
The media type of the result provided by a URI if
the valuetype is ref; only relevant for uses of <param> in
<object>. |
Exactly one of expr or value must be present. The use of
valuetype and type is optional in general, although they may be
required by specific objects. When <param> is contained in
a <subdialog> element, the values specified by it are used
to initialize dialog <var> elements in the subdialog that
is invoked. When <param> is contained in an <object>,
the use of the parameter data is specific to the object that is
being invoked, and is outside the scope of the VoiceXML
specification.
Below is an example of <param> used as part of an
<object>. In this case, the first two <param>
elements have expressions (implicitly of valuetype="data"), the
third <param> has an explicit value, and the fourth is a
URI that returns a media type of text/plain. The meaning of this
data is specific to the object.
<object name="debit"
classid="method://credit_card/gather_and_debit"
data="http://www.recordings.example.com/prompts/credit/jesse.jar"/>
<param name="amount" expr="document.amt"/>
<param name="vendor" expr="vendor_num"/>
<param name="application_id" value="ADC5678-QWOO"/>
<param name="authentication_server"
value="http://auth_svr.example.com"
valuetype="ref"
type="text/plain"/>
</object>
The next example illustrates <param> used with
<subdialog>. In this case, two expressions are used to
initialize variables in the scope of the subdialog form.
<form>
<subdialog name="result" src="http://another.example.com/#getssn">
<param name="firstname" expr="document.first"/>
<param name="lastname" expr="document.last"/>
<filled>
<submit namelist="result.ssn"
next="http://myservice.example.com/cgi-bin/process"/>
</filled>
</subdialog>
</form>
Subdialog in http://another.example.com
<form id="getssn">
<var name="firstname"/>
<var name="lastname"/>
<field name="ssn">
<grammar src="http://grammarlib/ssn.grxml"
type="application/grammar+xml"/>
<prompt>
Please say social security number.
</prompt>
<filled>
<if cond="validssn(firstname,lastname,ssn)">
<assign name="status" expr="true"/>
<return namelist="status ssn"/>
<else/>
<assign name="status" expr="false"/>
<return namelist="status"/>
</if>
</filled>
</field>
</form>
Using <param> in a <subdialog> is a convenient way
of passing data to a subdialog without requiring the use of
server side scripting.
Time designations follow those used in W3C's Cascading Style
Sheet recommendation (http://www.w3.org/TR/REC-CSS2/syndata.html#q20). They consist of an unsigned
integer number
followed by an optional time unit identifier. The time unit
identifiers are:
Examples include: "500", "3s", "850ms", and "+1.5s".
Negative time designations are not permitted.
active grammar- A speech or DTMF grammar that is currently active. This is
based on the currently executing element, and the scope elements
of the currently defined grammars.
application- A collection of VoiceXML documents that are tagged
with the same application name attribute.
ASR- Automatic speech recognition.
author- The creator of a VoiceXML document.
catch element- A <catch> block or one of its abbreviated forms.
Certain default catch elements are defined by the VoiceXML
interpreter.
CSS W3C Cascading Style Sheet specification.- See http://www.w3.org/TR/REC-CSS2/syndata.html#q20
dialog- An interaction with the user specified in a VoiceXML
document. Types of dialogs include forms and
menus.
ECMAScript- A standard version of JavaScript backed by the European
Computer Manufacturer’s Association. See http://www.ecma.ch/ecma1/STAND/ECMA-262.htm
event- A notification "thrown" by the implementation
platform, VoiceXML interpreter context, VoiceXML
interpreter, or VoiceXML code. Events include exceptional
conditions (semantic errors), normal errors (user did not say
something recognizable), normal events (user wants to exit), and
user defined events.
executable content- Procedural logic that occurs in <block>,
<filled>, and event handlers.
field item- A form item whose purpose is to input a field item
variable. Field items include <field>, <record>,
<object>, <subdialog>, and <transfer>.
form- A dialog that interacts with the user in a
highly flexible fashion with the computer and the user
sharing the initiative.
form item- An element of <form> that can be visited during form
execution: <initial>, <block>, <field>,
<record>, <object>, and <transfer>.
form item variable- A variable, either implicitly or explicitly defined,
associated with each form item in a form. If the
form item variable is undefined, the form interpretation
algorithm will visit the form item and use it to interact with
the user.
implementation platform- A computer with the requisite software and/or hardware to
support the types of interaction defined by VoiceXML.
link- A set of grammars that when matched by something the
user says or keys in, either transitions to a new dialog
or document or throws an event in the current form item.
menu- A dialog presenting the user with a set of
choices and takes action on the selected one.
mixed initiative- A computer-human interaction in which either the computer or
the human can take initiative and decide what to do next.
JSGF- Java API Speech Grammar Format. A proposed standard for
representing speech grammars. See
http://www.javasoft.com/products/java-media/speech/forDevelopers/JSGF
JSML- Java API Speech Markup Language. A proposed standard for
speech markups. See
http://www.javasoft.com/products/java-media/speech/forDevelopers/JSML
object- A platform-specific capability with an interface available
via VoiceXML.
request- A collection of data including: a URI specifying a document
server for the data, a set of name-value pairs of data to be
processed (optional), and a method of submission for processing
(optional).
SABLE- A consortium seeking to develop standards for speech markup.
See http://www.bell-labs.
com/project/tts/sable.html
script- A fragment of logic written in a client-side scripting
language, especially ECMAScript, which is a scripting
language that must be supported by any VoiceXML
interpreter.
session- A connection between a user and an implementation
platform, e.g. a telephone call to a voice response system.
One session may involve the interpretation of more than one
VoiceXML document.
subdialog- A VoiceXML dialog (or document) invoked from the current
dialog in a manner analogous to function calls.
tapered prompts- A set of prompts used to vary a message given to the human.
Prompts may be tapered to be more terse with use (field
prompting), or more explicit (help prompts).
throw- An element that fires an event.
TTS- Text-To-Speech; speech synthesis.
user- A person whose interaction with an implementation
platform is controlled by a VoiceXML interpreter.
URI- Uniform Resource Indicator.
URL- Uniform Resource Locator.
VoiceXML document- An XML document conforming to the VoiceXML
specification.
VoiceXML interpreter- A computer program that interprets a VoiceXML document
to control an implementation platform for the purpose of
conducting an interaction with a user.
VoiceXML interpreter context- A computer program that uses a VoiceXML interpreter to
interpret a VoiceXML Document and that may also interact
with the implementation platform independently of the
VoiceXML interpreter.
W3C- World Wide Web Consortium http://www.w3.org/
This section is Normative.
<!--
VoiceXML 2.0 DTD
version 20010525
Copyright (c) 2001 W3C (MIT, INRIA, Keio)
All Rights Reserved.
This DTD is the merger of
VoiceXML 1.0
Speech Synthesis Markup Language 1.0
Speech Recognition Grammar Format
with changes, additions, deletions to each noted.
-->
<!ENTITY % audio
"#PCDATA | audio | enumerate | value" >
<!ENTITY % bargeintype "(energy | speech | recognition)" >
<!ENTITY % boolean "(true|false)" >
<!ENTITY % content.type "CDATA">
<!ENTITY % duration "CDATA" >
<!ENTITY % event.handler "catch | help | noinput | nomatch | error" >
<!ENTITY % event.name "NMTOKEN" >
<!ENTITY % event.names "CDATA" >
<!ENTITY % executable.content
"%audio; | assign | clear | disconnect | exit | goto | if | log | prompt |
reprompt | return | script | submit | throw | var " >
<!ENTITY % expression "CDATA" >
<!ENTITY % field.name "NMTOKEN" >
<!ENTITY % field.names "CDATA" >
<!ENTITY % integer "CDATA" >
<!ENTITY % item.attrs
"name %field.name; #IMPLIED
cond %expression; #IMPLIED
expr %expression; #IMPLIED " >
<!ENTITY % uri "CDATA" >
<!ENTITY % cache.attrs
"fetchhint (prefetch|safe) #IMPLIED
fetchtimeout %duration; #IMPLIED
maxage %integer; #IMPLIED
maxstale %integer; #IMPLIED" >
<!ENTITY % next.attrs
"next %uri; #IMPLIED
expr %expression; #IMPLIED " >
<!ENTITY % submit.attrs
"method (get|post) 'get'
enctype %content.type; 'application/x-www-form-urlencoded'
namelist %field.names; #IMPLIED" >
<!ENTITY % sentence-elements
"break | emphasis | mark | phoneme | prosody | say-as | voice" >
<!ENTITY % allowed-within-sentence " %audio; | %sentence-elements; " >
<!ENTITY % structure "paragraph | p | sentence | s">
<!ENTITY % phoneme-string "CDATA" >
<!ENTITY % phoneme-alphabet "CDATA" >
<!ENTITY % tts "%sentence-elements; | %structure;" >
<!ENTITY % variable "block | field | var" >
<!--================================= Root ================================-->
<!ELEMENT vxml
(%event.handler; | form | link | menu | meta |
property | script | var)+ >
<!ATTLIST vxml
application %uri; #IMPLIED
base %uri; #IMPLIED
xml:lang NMTOKEN #IMPLIED
version CDATA #REQUIRED >
<!ELEMENT meta EMPTY >
<!ATTLIST meta
name NMTOKEN #IMPLIED
content CDATA #REQUIRED
http-equiv NMTOKEN #IMPLIED >
<!--================================= Dialogs =============================-->
<!ENTITY % input "grammar" >
<!ENTITY % scope "(document | dialog)" >
<!ELEMENT form
(%input; | %event.handler; | filled | initial | object | link | property |
record | script | subdialog | transfer | %variable;)* >
<!ATTLIST form
id ID #IMPLIED
scope %scope; 'dialog' >
<!ENTITY % accept.attrs
"accept (exact | approximate) 'exact'" >
<!ELEMENT menu
(%audio; | choice | %event.handler; | prompt | property)* >
<!ATTLIST menu
id ID #IMPLIED
scope %scope; 'dialog'
%accept.attrs;
dtmf %boolean; 'false' >
<!ELEMENT choice (%audio; | grammar | %tts;)* >
<!ATTLIST choice
%cache.attrs;
%accept.attrs;
dtmf CDATA #IMPLIED
event %event.name; #IMPLIED
fetchaudio %uri; #IMPLIED
%next.attrs; >
<!--================================ Prompts ==============================-->
<!ELEMENT prompt (%audio; | %tts;)* >
<!ATTLIST prompt
bargein %boolean; #IMPLIED
bargeintype %bargeintype; #IMPLIED
cond %expression; #IMPLIED
count %integer; #IMPLIED
xml:lang NMTOKEN #IMPLIED
timeout %duration; #IMPLIED >
<!ELEMENT enumerate (%audio; | %tts;)*>
<!ELEMENT reprompt EMPTY >
<!--================================ Fields ===============================-->
<!ELEMENT field
(%audio; | %event.handler; | filled | %input; | link | option | prompt | property)* >
<!ATTLIST field
%item.attrs;
type CDATA #IMPLIED
slot NMTOKEN #IMPLIED
modal %boolean; 'false' >
<!ELEMENT option (#PCDATA) >
<!ATTLIST option
dtmf CDATA #IMPLIED
value CDATA #IMPLIED >
<!ELEMENT var EMPTY >
<!ATTLIST var
name %field.name; #REQUIRED
expr %expression; #IMPLIED >
<!ELEMENT initial (%audio; | %event.handler; | link | prompt | property)* >
<!ATTLIST initial
%item.attrs; >
<!ELEMENT block (%executable.content;)* >
<!ATTLIST block
%item.attrs; >
<!ELEMENT assign EMPTY >
<!ATTLIST assign
name %field.name; #REQUIRED
expr %expression; #REQUIRED >
<!ELEMENT clear EMPTY >
<!ATTLIST clear
namelist %field.names; #IMPLIED >
<!ELEMENT value EMPTY >
<!ATTLIST value
expr %expression; #REQUIRED >
<!--================================== Events =============================-->
<!ENTITY % event.handler.attrs
"count %integer; #IMPLIED
cond %expression; #IMPLIED" >
<!ELEMENT catch (%executable.content;)* >
<!ATTLIST catch
event %event.names; #REQUIRED
%event.handler.attrs; >
<!ELEMENT error (%executable.content;)* >
<!ATTLIST error
%event.handler.attrs; >
<!ELEMENT help (%executable.content;)* >
<!ATTLIST help
%event.handler.attrs; >
<!ELEMENT link (grammar)* >
<!ATTLIST link
%cache.attrs;
%next.attrs;
fetchaudio %uri; #IMPLIED
dtmf CDATA #IMPLIED
event %event.name; #IMPLIED >
<!ELEMENT noinput (%executable.content;)* >
<!ATTLIST noinput
%event.handler.attrs; >
<!ELEMENT nomatch (%executable.content;)* >
<!ATTLIST nomatch
%event.handler.attrs; >
<!ELEMENT throw EMPTY >
<!ATTLIST throw
event %event.name; #IMPLIED
eventexpr %expression; #IMPLIED
message CDATA #IMPLIED
messageexpr %expression; #IMPLIED >
<!--============================== Audio Output ===========================-->
<!ELEMENT audio (%audio; | %tts;)* >
<!ATTLIST audio
src %uri; #IMPLIED
expr %expression; #IMPLIED
%cache.attrs; >
<!ELEMENT paragraph (%allowed-within-sentence; | sentence | s)*>
<!ATTLIST paragraph
xml:lang NMTOKEN #IMPLIED >
<!ELEMENT p (%allowed-within-sentence; | sentence | s)*>
<!ATTLIST p
xml:lang NMTOKEN #IMPLIED >
<!ELEMENT sentence (%allowed-within-sentence;)*>
<!ATTLIST sentence
xml:lang NMTOKEN #IMPLIED >
<!ELEMENT s (%allowed-within-sentence;)*>
<!ATTLIST s
xml:lang NMTOKEN #IMPLIED >
<!-- The flexible container elements can occur within paragraph -->
<!-- and sentence but may also contain these structural elements. -->
<!ENTITY % voice-name "CDATA">
<!ELEMENT voice (%allowed-within-sentence; | %structure;)*>
<!ATTLIST voice
gender (male|female|neutral) #IMPLIED
age %integer; #IMPLIED
category (child|teenager|adult|elder) #IMPLIED
variant %integer; #IMPLIED
name CDATA #IMPLIED >
<!ELEMENT prosody (%allowed-within-sentence; | %structure;)*>
<!ATTLIST prosody
pitch CDATA #IMPLIED
contour CDATA #IMPLIED
range CDATA #IMPLIED
rate CDATA #IMPLIED
duration CDATA #IMPLIED
volume CDATA #IMPLIED >
<!-- These basic container elements can contain any of the -->
<!-- within-sentence elements, but neither sentence or paragraph. -->
<!ELEMENT emphasis (%allowed-within-sentence;)*>
<!ATTLIST emphasis
level (strong|moderate|none|reduced) 'moderate' >
<!-- This basic container element can contain data or value -->
<!ELEMENT say-as (#PCDATA|value)>
<!ATTLIST say-as
type CDATA #REQUIRED
sub CDATA #IMPLIED >
<!-- This basic container element can contain only data -->
<!ELEMENT phoneme (#PCDATA)>
<!ATTLIST phoneme
ph %phoneme-string; #REQUIRED
alphabet %phoneme-alphabet; #IMPLIED >
<!-- Definitions of the basic empty elements -->
<!ELEMENT break EMPTY>
<!ATTLIST break
size (large|medium|small|none) 'medium'
time %duration; #IMPLIED >
<!ELEMENT mark EMPTY>
<!ATTLIST mark
name CDATA #REQUIRED >
<!--============================= Audio Input =============================-->
<!ENTITY % key "CDATA" >
<!ENTITY % grammar.attrs
"%cache.attrs;
version CDATA '1.0'
xml:lang NMTOKEN #IMPLIED
root IDREF #IMPLIED
mode (voice | dtmf) 'voice'
scope %scope; #IMPLIED
src %uri; #IMPLIED
type CDATA #IMPLIED
weight CDATA #IMPLIED " >
<!ENTITY % rule-expansion "#PCDATA | token | ruleref
| item | one-of | count " >
<!ELEMENT ruleref EMPTY>
<!ATTLIST ruleref
uri CDATA #IMPLIED
import CDATA #IMPLIED
special CDATA #IMPLIED
xml:lang NMTOKEN #IMPLIED
tag CDATA #IMPLIED>
<!ELEMENT token (#PCDATA)>
<!ATTLIST token
lexicon CDATA #IMPLIED
xml:lang NMTOKEN #IMPLIED>
<!ELEMENT one-of (item)*>
<!ATTLIST one-of
tag CDATA #IMPLIED
xml:lang NMTOKEN #IMPLIED>
<!ELEMENT item ( %rule-expansion; )*>
<!ATTLIST item
weight NMTOKEN #IMPLIED
tag CDATA #IMPLIED
xml:lang NMTOKEN #IMPLIED>
<!ELEMENT count ( %rule-expansion; )*>
<!ATTLIST count
number CDATA #IMPLIED
tag CDATA #IMPLIED
xml:lang NMTOKEN #IMPLIED>
<!ELEMENT rule ( %rule-expansion; | example )*>
<!ATTLIST rule
id ID #REQUIRED
scope (private | public) "private">
<!ELEMENT example (#PCDATA)>
<!ELEMENT import EMPTY>
<!ATTLIST import
uri CDATA #REQUIRED
name CDATA #REQUIRED>
<!ELEMENT grammar (#PCDATA | import | rule )* >
<!ATTLIST grammar
%grammar.attrs; >
<!ELEMENT record
(%audio; | %event.handler; | filled | grammar | prompt | property)* >
<!ATTLIST record
%item.attrs;
type CDATA #IMPLIED
beep %boolean; 'false'
dest %uri; #IMPLIED
maxtime %duration; #IMPLIED
modal %boolean; 'true'
finalsilence %duration; #IMPLIED
dtmfterm %boolean; 'true' >
<!--============================ Call Control ============================-->
<!ELEMENT disconnect EMPTY >
<!ELEMENT transfer
(%audio; | %event.handler; | filled | grammar | prompt | property)* >
<!ATTLIST transfer
%item.attrs;
dest %uri; #IMPLIED
destexpr %expression; #IMPLIED
bridge %boolean; 'false'
connecttimeout %duration; #IMPLIED
maxtime %duration; #IMPLIED
transferaudio %uri; #IMPLIED >
<!--============================ Control Flow ============================-->
<!ENTITY % if.attrs
"cond %expression; #REQUIRED" >
<!ELEMENT if (%executable.content; | elseif | else)* >
<!ATTLIST if
%if.attrs; >
<!ELEMENT elseif EMPTY >
<!ATTLIST elseif
%if.attrs; >
<!ELEMENT else EMPTY >
<!ELEMENT exit EMPTY >
<!ATTLIST exit
expr %expression; #IMPLIED
namelist %field.names; #IMPLIED >
<!ELEMENT filled (%executable.content;)* >
<!ATTLIST filled
mode (any|all) "all"
namelist %field.names; #IMPLIED >
<!ELEMENT goto EMPTY >
<!ATTLIST goto
%cache.attrs;
%next.attrs;
fetchaudio %uri; #IMPLIED
expritem %expression; #IMPLIED
nextitem %field.name; #IMPLIED >
<!ELEMENT param EMPTY >
<!ATTLIST param
name NMTOKEN #REQUIRED
expr %expression; #IMPLIED
value CDATA #IMPLIED
valuetype (data|ref) 'data'
type CDATA #IMPLIED >
<!ELEMENT return EMPTY >
<!ATTLIST return
namelist %field.names; #IMPLIED
event %event.name; #IMPLIED >
<!ELEMENT subdialog
(%audio; | %event.handler; | filled | param | prompt | property)* >
<!ATTLIST subdialog
%item.attrs;
src %uri; #REQUIRED
%cache.attrs;
fetchaudio %uri; #IMPLIED
%submit.attrs; >
<!ELEMENT submit EMPTY >
<!ATTLIST submit
%cache.attrs;
%next.attrs;
fetchaudio %uri; #IMPLIED
%submit.attrs; >
<!--========================== Miscellaneous ==============================-->
<!ELEMENT log (#PCDATA | value)* >
<!ATTLIST log
label CDATA #IMPLIED
expr %expression; #IMPLIED >
<!ELEMENT object
(%audio; | %event.handler; | filled | param | prompt | property)* >
<!ATTLIST object
%item.attrs;
%cache.attrs;
classid %uri; #IMPLIED
codebase %uri; #IMPLIED
data %uri; #IMPLIED
type CDATA #IMPLIED
codetype CDATA #IMPLIED
archive %uri; #IMPLIED >
<!ELEMENT property EMPTY >
<!ATTLIST property
name NMTOKEN #REQUIRED
value CDATA #REQUIRED >
<!ELEMENT script (#PCDATA) >
<!ATTLIST script
src %uri; #IMPLIED
charset CDATA #IMPLIED
%cache.attrs; >
The form interpretation algorithm (FIA) drives the interaction
between the user and a VoiceXML form or menu. A menu can be
viewed as a form containing a single field whose grammar and
whose <filled> action are constructed from the
<choice> elements.
The FIA must handle:
-
Form initialization.
-
Prompting, including the management of the prompt counters
needed for prompt tapering.
-
Grammar activation and deactivation at the form and form item
levels.
-
Entering the form with an utterance that matched one of the
form’s document-scoped grammars while the user was visiting
a different form or menu.
-
Leaving the form because the user matched another form, menu,
or link’s document-scoped grammar.
-
Processing multiple field fills from one utterance, including
the execution of the relevant <filled> actions.
-
Selecting the next form item to visit, and then processing
that form item.
-
Choosing the correct catch element to handle any events thrown
while processing a form item.
First we define some terms and data structures used in the
form interpretation algorithm:
active grammar set- The set of grammars active during a VoiceXML interpreter
context’s input collection operation.
utterance- A summary of what the user said or keyed in, including the
specific grammar matched, and a dictionary of slot name/slot
value pairs. An example utterance might be: "grammar 123 was
matched, and the slots are from_city = ‘chicago’,
to_city = ‘new orleans’, and flight_num = 2233".
execute- To execute executable content – either a block, a
filled action, or a set of filled actions. If an event is thrown
during execution, the execution of the executable content is
aborted. The appropriate event handler is then executed, and this
may cause control to resume in a form item, in the next iteration
of the form’s main loop, or outside of the form. If a
<goto> is executed, the transfer takes place immediately,
and the remaining executable content is not executed.
Here is the conceptual form interpretation algorithm. The FIA
can start with no initial utterance, or with an initial utterance
passed in from another dialog:
//
// Initialization Phase
//
foreach ( <var> and form item variable, in document order )
Declare the variable, initializing it to the value of
the "expr" attribute, if any, or else to undefined.
foreach ( field item )
Declare a prompt counter and set it to 1.
if ( there is an initial item )
Declare a prompt counter and set it to 1.
if ( user entered form by speaking to its
grammar while in a different form )
{
Enter the main loop below, but start in
the process phase, not the select phase:
we already have a collection to process.
}
//
// Main Loop: select next form item and execute it.
//
while ( true )
{
//
// Select Phase: choose a form item to visit.
//
if ( the last main loop iteration ended
with a <goto nextitem> )
Select that next form item.
else if (there is a form item with an
unsatisfied guard condition )
Select the first such form item in document order.
else
Do an <exit/> -- the form is full and specified no transition.
//
// Collect Phase: execute the selected form item.
//
// Queue up prompts for the form item.
unless ( the last loop iteration ended with
a catch that had no <reprompt> )
{
Select the appropriate prompts for the form item.
Queue the selected prompts for play prior to
the next collect operation.
Increment the form item’s prompt counter.
}
// Activate grammars for the form item.
if ( the form item is modal )
Set the active grammar set to the form item grammars,
if any. (Note that some form items, e.g. <block>,
cannot have any grammars).
else
Set the active grammar set to the form item
grammars and any grammars scoped to the form,
the current document, the application root
document, and then elements up the <subdialog>
call chain.
// Execute the form item.
if ( a <field> was selected )
Collect an utterance or an event from the user.
else if ( a <record> was chosen )
Collect an utterance (with a name/value pair
for the recorded bytes) or event from the user.
else if ( an <object> was chosen )
Execute the object, setting the <object>’s
form item variable to the returned ECMAScript value.
else if ( a <subdialog> was chosen )
Execute the subdialog, setting the <subdialog>’s
form item variable to the returned ECMAScript value.
else if ( a <transfer> was chosen )
Do the transfer, and (if wait is true) set the
<transfer> form item variable to the returned
result status indicator.
else if ( the <initial> was chosen )
Collect an utterance or an event from the user.
else if ( a <block> was chosen )
{
Set the block’s form item variable to a defined value.
Execute the block’s executable context.
}
//
// Process Phase: process the resulting utterance or event.
//
// Process an event.
if ( the form item execution resulted in an event )
{
Find the appropriate catch for the event
starting in the scope of the current form item.
Execute the catch (this may leave the FIA).
continue
}
// Must have an utterance: process ones from outside grammars.
if ( the utterance matched a grammar from outside the form )
{
if ( the grammar belongs to a <link> element )
Execute that link’s goto or throw.
if ( the grammar belongs to a menu’s <choice> element )
Execute the choice’s goto or throw, leaving the FIA.
// The grammar belongs to another form (or menu).
Transition to that form (or menu), carrying the utterance
to the other form (or menu)’s FIA.
}
// Process an utterance spoken to a grammar from this form.
// First copy utterance slot values into corresponding
// form item variables.
Clear all "just_filled" flags.
foreach ( slot in the user’s utterance )
{
if ( the slot corresponds to a field item )
{
Copy the slot value into the field item’s
form item variable.
Set this field item’s "just_filled" flag.
}
}
// Set <initial> form item variable if any field items are filled.
if ( any field item variable is set as a result of the user utterance )
Set the <initial> form item variable.
// Next execute any <filled> actions triggered by this utterance.
foreach ( <filled> action in document order )
{
// Determine the form item variables the <filled> applies to.
N = the <filled>’s "namelist" attribute.
if ( N equals "" )
{
if ( the <filled> is a child of a form item )
N = the form item’s form item variable name.
else if ( the <filled> is a child of a form )
N = the form item variable names of all the field
items in that form.
}
// Is the <filled> triggered?
if ( any form item variable in the set N was "just_filled"
AND ( the <filled> mode is "all"
AND all variables in N are filled
OR the <filled> mode is "any"
AND any variables in N are filled) )
Execute the <filled> action.
If an event is thrown during the execution of a <filled>,
event handler selection starts in the scope of the <filled>,
which could be a form item or the form itself.
}
}
The various timing properties for speech and DTMF recognition
work together to define the user experience. The ways in which
these different timing parameters function are outlined in the
timing diagrams below. In these diagrams, the start for wait of
DTMF input, or user speech both occur at the time that the last
prompt has finished playing.
DTMF grammars use timeout, interdigittimeout, termtimeout and
termchar to tailor the user experience. The effects of these are
shown in the following timing diagrams.
timeout, No Input Provided
The timeout parameter determines when the <noinput>
event is thrown because the user has failed to enter any DTMF
(Figure 8).
Figure 8: Timing diagram for timeout when no input provided.
interdigittimeout, Grammar is Not Ready to
Terminate
In Figure 9, the interdigittimeout determines when the nomatch
event is thrown because a DTMF grammar is not yet recognized, and
the user has failed to enter additional DTMF.
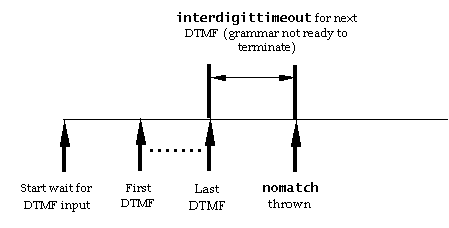
Figure 9: Timing diagram for interdigittimeout, grammar is not
ready to terminate.
interdigittimeout, Grammar is Ready to
Terminate
The example below shows the situation when a DTMF grammar
could terminate, or extend by the addition of more DTMF input,
and the user has elected not to provide any further input.
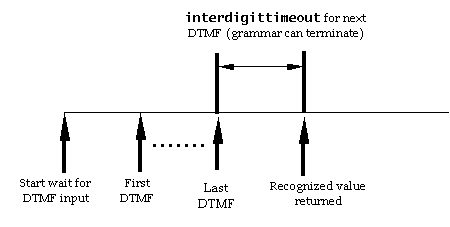
Figure 10: Timing diagram for interdigittimeout, grammar is ready
to terminate.
termchar and interdigittimeout, Grammar Can
Terminate
In the example below, a termchar is non-empty, and is entered
by the user before an interdigittimeout expires, to signify that
the users DTMF input is complete; the termchar is not included as
part of the recognized value.
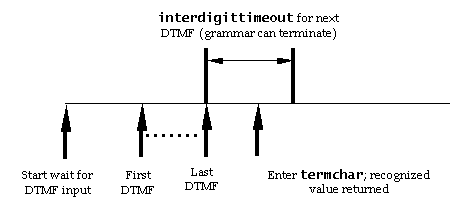
Figure 11: Timing diagram for termchar and interdigittimeout,
grammar can terminate.
termchar Empty When Grammar Must
Terminate
In the example below, the entry of the last DTMF has brought
the grammar to a termination point at which no additional DTMF is
expected. Since termchar is empty, there is no optional
terminating character permitted, thus the recognition ends and
the recognized value is returned.

Figure 12:Timing diagram for termchar empty when grammar must
terminate.
termchar Non-Empty and termtimeout When
Grammar Must Terminate
In the example below, the entry of the last DTMF has brought
the grammar to a termination point at which no additional DTMF is
allowed by the grammar. If the termchar is non-empty, then the
user can enter an optional termchar DTMF. If the user fails to
enter this optional DTMF within termtimeout, the recognition ends
and the recognized value is returned. If the termtimeout is 0s
(the default), then the recognized value is returned immediately
after the last DTMF allowed by the grammar, without waiting for
the optional termchar.
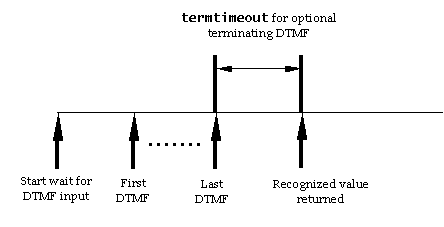
Figure 13: Timing diagram for termchar non-empty and termtimeout
when grammar must terminate.
termchar Non-Empty and termtimeout When
Grammar Must Terminate
In this last DTMF example, the entry of the last DTMF has
brought the grammar to a termination point at which no additional
DTMF is allowed by the grammar. Since the termchar is non-empty,
the user enters the optional termchar within termtimeout causing
the recognized value to be returned (excluding the termchar).
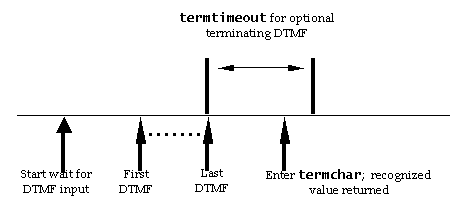
Figure 14: Timing diagram for termchar non-empty when grammar
must terminate.
Speech grammars use timeout, completetimeout, and
incompletetimeout to tailor the user experience. The effects of
these are shown in the following timing diagrams.
timeout When No Speech Provided
In the example below, the timeout parameter determines when
the noinput event is thrown because the user has failed to
speak.
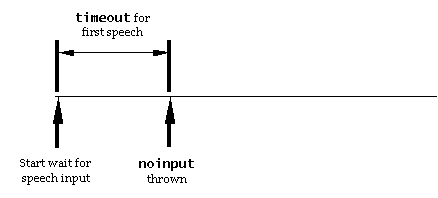
Figure 15: Timing diagram for timeout when no speech
provided.
completetimeout With Speech Grammar
Recognized
In the example above, the user provided a utterance that was
recognized by the speech grammar. After a silence period of
completetimeout has elapsed, the recognized value is
returned.
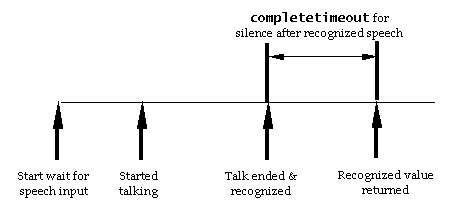
Figure 16: Timing diagram for completetimeout with speech grammar
recognized.
incompletetimeout with Speech Grammar
Unrecognized
In the example above, the user provided a utterance that is
not as yet recognized by the speech grammar but is the prefix of
a legal utterance. After a silence period of incompletetimeout
has elapsed, a nomatch event is thrown.
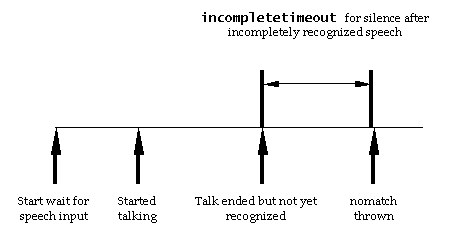
Figure 17: Timing diagram for incompletetimeout with speech
grammar unrecognized.
VoiceXML requires
that a platform support the playing and recording audio formats
specified below.
| Audio Format |
Media Type |
| Raw (headerless) 8kHz 8-bit mono mu-law [PCM] single channel.
(G.711) |
audio/basic (from http://www.ietf.org/rfc/rfc1521.txt) |
| Raw (headerless) 8kHz 8 bit mono A-law [PCM] single channel.
(G.711) |
audio/x-alaw-basic |
| WAV (RIFF header) 8kHz 8-bit mono mu-law [PCM] single
channel. |
audio/wav |
| WAV (RIFF header) 8kHz 8-bit mono A-law [PCM] single
channel. |
audio/wav |
The 'audio/basic' mime type is commonly used with the 'au'
header format as well as the headerless 8-bit 8Khz mu-law format.
If this mime type is specified for recording, the mu-law format
must be used. For playback with the 'audio/basic' mime type,
platforms must support the mu-law format and may support the 'au'
format.
Issues:
- The mime types do not uniquely identify the
audio and file encodings for the required audio formats. At
present, there are no offical mime types which are more precise
than these. The ITU is currently developing a more precise set.
When available, the ITU mime types may be adopted by a future
revision of this document.
This section is Normative.
A document is a Conforming VoiceXML Document if:
- it is an XML document.
- (relative to XML) is well-formed.
- conforms to the following W3C Recommendations:
- its root element is a vxml element.
The root element of the document designates the vxml namespace
using the "xmlns" attribute (Namespaces in
XML). The namespace for vxml is defined to be
"http://www.w3.org/2001/vxml".
- if all non-VoiceXML namespace elements and attributes and all
xmlns attributes which refer to
non-VoiceXML namespace elements are removed from the given
document, and if an appropriate XML declaration (i.e.,
<?xml...?>) is included at the top of the document, and if
an appropriate document type declaration (i.e., <!DOCTYPE vxml
... >) which points to the VoiceXML DTD is included
immediately thereafter, the result is a valid XML
document.
The VoiceXML language or these conformance criteria provide no
designated size limits on any aspect of VoiceXML documents. There
are no maximum values on the number of elements, the amount of
character data, or the number of characters in attribute
values.
A VoiceXML processor is a program that can parse and process
Conforming VoiceXML documents.
In a Conforming VoiceXML Processor, the XML parser
must be able to parse and process all well-formed XML constructs
defined within XML 1.0
and XML
Namespaces. It is not required that a Conforming VoiceXML
processor use a validating parser.
A Conforming VoiceXML Processor must be a Conforming Speech
Synthesis Markup Language Processor and a Conforming XML
Grammar Processor except for differences described in this
document. If a syntax error is detected processing a grammar
document, then an "error.badfetch" event must be thrown.
A Conforming VoiceXML Processor must support the
syntax and semantics of all VoiceXML elements as described in
this document. Consequently, a Conforming VoiceXML
Processor must not throw an
'error.unsupported.<element>' for any VoiceXML element
which must be supported when processing a Conforming VoiceXML
Document.
When a Conforming VoiceXML Processor encounters a Conforming VoiceXML Document
with non-VoiceXML elements or attributes which are propriety,
defined only in earlier versions of VoiceXML, or defined in a
non-VoiceXML namespace, and which cannot be processed, then it
must throw an "error.unsupported.<element>" event.
There is, however, no conformance requirement with respect to
performance characteristics of the VoiceXML Processor.
Determination of whether a given platform is a Conforming
VoiceXML Processor will be carried out by the VoiceXML Forum.
VoiceXML is an application of XML 1.0 and thus supports
Unicode
which defines a standard universal character set.
Additionally, VoiceXML provides a mechanism for precise
control of the input and output languages via the use of
"xml:lang" attribute. This facility provides:
- the ability to specify the input and output language
overriding the VoiceXML Processor default language
- The ability to produce multi-language output
- The ability to interpret input in a language different from
the output language(s)
This appendix explains how accessibility guidelines published
by W3C's Web Accessibility Initiative (WAI) apply to
VoiceXML.
- The Web
Content Accessibility Guidelines 1.0 explains how authors can
create Web content that is accessible to people with
disabilities. VoiceXML only addresses content which is aimed at
the aural modality. To support content accessibility, a service
developer should provide the same content via other channels
which support other modalities; for example, HTML, WML, etc.
- The Authoring Tool
Accessibility Guidelines 1.0 explains how developers can
design accessible authoring tools. VoiceXML authoring tools are
not addressed in this specification.
- The User Agent
Accessibility Guidelines 1.0 explains how developers can
design accessible user agents. Since VoiceXML explicitly
addresses the aural modality and DTMF input, VoiceXML User Agents
will not conform to the UAAG.
A future revision of this document may specify criteria by
which a VoiceXML Processor safeguards the privacy of personal
data.
The following is a summary of the differences between VoiceXML
2.0 and VoiceXML
1.0.
Developers of VoiceXML 1.0 applications should pay particular
attentions to the changes incompatible with VoiceXML 1.0
specified in Obsolete Elements
and Incompatibly Modified
Elements.
- <log> to specify a debug message (5.3.13)
- changed "lang" to "xml:lang" in <vxml> (1.5.1).
- added "accept" attribute to <menu> and <choice>
(2.2)
- removed "modal" attribute of <subdialog> (2.3.4)
- removed "fetchaudio" attribute from <object>(2.3.5)
- removed notational equivalence between <filled> in a
field and a form-level <filled> triggering on that field
(2.4)
- TTS content in <choice>, <prompt>,
<enumerate>, and <audio> replaced with definition in
Speech Synthesis Markup Language (4.1.2)
- removed "class", "mode" and "recsrc" attributes from
<value> (4.1.4)
- changed standard session variable "session.uui" to
"session.telephone.uui" (5.1.4)
- removed "caching" attribute (6.1)
- added "maxage" and "maxstale" attributes (6.1)
- removed 'stream' as value of fetchhint property (6.1.1, 6.3.5)
- removed "caching" from fetching properties (6.3.5).
- added "dest" attribute to <record>; added "maxtime" and
"dest" shadow variables (2.3.6)
- added "transferaudio" attribute to <transfer>; added
"maxtimedisconnect", and "unknown" as values of bridge transfers;
added more error.telephone events (2.3.7)
- added 'dtmf' attribute to <link> (2.5).
- the XML Form of
the W3C Speech Recognition Grammar Format, must be supported
in <grammar> (3.1).
- added "weight", "mode", "xml:lang", "root" and "version"
attributes to <grammar> (3.1).
- added "xml:lang" attribute to <prompt> (4.1).
- added "bargeintype" attribute to <prompt> (4.1).
- added "expr" attribute to <audio> element (4.1.3)
- "bargeintype" attribute on <prompt> (4.1.3)
- added standard session variables "session.telephone.rdnis"
and "session.telephone.redirect_reason" (5.1.4)
- added application variable "application.lastresult$"
describing last recognition result, including n-best (5.1.5).
- added "event", "eventexpr", "message" and "messageexpr" as
attributes of <throw> (5.2.1).
- added "_event" variable to <catch> (5.2.2).
- added "error.badfetch.http.nnn" as pre-defined error type (5.2.6)
- added "errrobadfetch.protocol.<response code>" as
pre-defined error type (5.2.6)
- added "maxspeechtimeout" event (5.2.6)
- added "error.unsupported.language" pre-defined error type (5.3.6)
- added required support for "multipart/form-data" value as
"enctype" of <submit> (5.3.8)
- <script> can occur in <form> element (5.3.12)
- HTTP is mandatory (6.1.4)
- added "maxspeechtimeout" property (6.3.2)
- added "bargeintype" property (6.3.4)
- added "fetchaudiodelay" and "fetchaudiominimum" to fetch
properties (6.3.5)
- added "maxnbest" session property (6.3.6)
- added "universals" property (with default "none") (6.3.6).
- Added defaults for fetching attributes, as well as "maxage"
and "maxstale" fetching attributes to: <choice>,
<subdialog>, <object>, <link>, <grammar>,
<audio>, <goto>, <submit> and
<script>
- definitions of, and transitions between, root and leaf
document (1.5.2).
- referencing application root document and its grammars (1.5.2).
- <subdialog> transferring control to another
<subdialog> and to another dialog via <goto> (1.5.3).
- behaviour when executing unsupported <object> instances
(2.1.2.1, 2.3.5).
- scope specified on individual form grammars takes precedence
over the default grammar scope in a <form> (2.1).
- effect of <goto nextitem> on form item (2.1.5).
- no variables, conditions or counters are reset when using
< goto nextitem> (2.1.5).
- behaviour of <transfer>, <subdialog> and
<object> with audio playback in collect phase (2.1.6).
- enumerated executable context elements which cause execution
to terminate (2.1.6.1).
- event handler selection in FIA process phase and
<filled> (2.1.6.2).
- <reprompt> does not terminate the FIA (2.1.6.2.3).
- use of <enumerate> (2.2, 2.3.1)
- precedence of <choice> "next" attribute over "expr"
attribute and precedence of "next" and "expr" over "event"
attribute (2.2).
- specification of approximate grammar generation in
<menu> and <choice> (2.2)
- <grammar> overrides automatically generated grammars in
<choice> (2.2).
- <choice> expr evaluates to URI to transition to (2.2).
- <choice> event handler without control transition,
causes menu to be re-executed (2.2).
- assignment of field variable when DTMF attribute defined (2.3.1).
- explanatory notes on portable use of builtins and expected
platform dependence (2.3.1.1).
- field item variable names must respect ECMAScript variable
naming conventions (2.3.1, 5.1).
- result value returned from "number" builtin type (2.3.1.1).
- Currency code not specified if not spoken (2.3.1.1)
- precedence of grammar "src" attribute over inline grammar (2.3.1.2)
- string returned when DTMF input when no "value" or CDATA
specified in <option> (2.3.1.3).
- <option> and <grammar> can be used simultaneously
to specify grammars in a <field> (2.3.1.3).
- use of builtin DTMF and speech grammars (2.3.1.4).
- handling of contradictory parameters to digits builtin (2.3.1.5).
- parameterization of builtin DTMF and speech grammars (2.3.1.5).
- scope of variables in <subdialog> (2.3.4).
- <subdialog> context is independent of its calling
context (variable instances are not shared) but its context
follows normal scoping rules for grammars, events, and variables
(2.3.4).
- in <subdialog> use "expr" attribute to set variable if
no corresponding <param> specified (2.3.4).
- user hangup during recording terminates recording normally;
data recorded prior to hangup can be returned to server (2.3.6).
- interpretation of grammars in <record> (2.3.6).
- field variable in <record> is a reference to recorded
audio. When submitting recorded data to a server, the "enctype"
of <submit> should be set to "multipart/form-data" (2.3.6, 5.3.8).
- termination of <tranfer> by speech or DTMF returns
near_end_disconnect status (2.3.7).
- value of "dest" attribute on <transfer> (2.3.7).
- the form item variable of <transfer> is undefined for
blind transfer (2.3.7).
- <link>s may have no grammars (2.5).
- events throw by a <link> are handled by the best
qualified <catch> in active scope (2.5).
- "xml:lang" attribute in <grammar> does not require
multi-lingual support from platform (3.1)
- unsupported grammar language results in
error.unsupported.language event being thrown (3.1.1)
- unsupported language lists can be indicated in the message
variable of a <throw> (3.1.1).
- 'number' results as a string which ECMAScript will
automatically convert to a number in a numerical expression;
string must not use a leading zero (3.1.1)
- "src" attribute takes precedence over an inline grammar
within the same element (3.1.1.3).
- implicit grammars (such as options) do not support weights
(3.1.1.4).
- <grammar> "mode" attribute conflict with grammar mode
(3.1.1.5).
- ongoing work on semantic attachments within <grammar>
(3.1.5)
- enclosing <prompt> required if text contains speech
synthesis markup (4.1.1).
- "xml:lang" attribute in <prompt> does not require
multi-lingual support from platform (4.1.2)
- unsupported synthesis language results in
error.unsupported.language event being thrown (4.1.2).
- 'alternate content' in <audio> (4.1.3).
- in <audio> "src" has precedence over "expr" attribute
(4.1.3).
- <audio> element ignored if "expr" evaluates to null (4.1.3).
- Issue note that audio streaming is currently a platform
optimization and a "stream" attribute may be added to
<audio> to give developer explicit control over audio
streaming (4.1.3).
- stand-alone <value> element is legal outside
<prompt> (4.1.4).
- TTS expression on <value> may return SSML fragment (4.1.4).
- <value> can playback audio data when "expr" specifies a
<record> field name (4.1.4).
- buffered DTMF input is deleted when "bargein" is false on
<prompt> (4.1.5).
- relationship between prompt queueing and input collection (4.1.8).
- VoiceXML and ECMAScript variables are part of the same
variable space;variables declared in ECMAScript can be used
directly in VoiceXML (5.1).
- VoiceXML variable names, including field names, must follow
ECMAScript naming rules; variable name declarations cannot
contain a dot; the field name "a.b" is illegal (5.1).
- implicit ECMAScript variables are not accessible in VoiceXML
(5.1.1).
- scope of variables (5.1.2).
- only some cond operators need to be escaped (5.1.3).
- evaluation of relative URLs against active document (5.2).
- VoiceXML does not generally specify when events are thrown
(5.2.1).
- definition of "event" and "count" attributes of <catch>
(5.2.2).
- no inherent limitations on <catch> in, for example,
case of user hangup (5.2.2).
- <catch>'s event may be an empty string indicating that
all events are to be caught (5.2.2).
- "as if by copy" catch inheritance (5.2,
5.2.4).
- catch element selection algorithm (5.2.4).
- defined prefix match as token match rather than string match
(5.2.4).
- "error.badfetch" pre-defined error type (5.2.6)
- HTTPS is not the same protocol as HTTP (5.2.6)
- effect of <reprompt> in catch elements (5.3.6)
- behaviour of <reprompt> when in <catch> with
final <goto> (5.3.6)
- effect of URI in <goto> on document variables (5.3.7)
- precedence defined between <goto> "next", "expr",
"nextitem" and "expritem" attributes (5.3.7)
- variables declared in VoiceXML or ECMAScript can be submitted
(5.3.8).
- <exit> does not throw an "exit" event (5.3.9)
- no "type" attribute of <script> (5.3.12).
- <script> evaluated along with <var> elements and
field item variables in <form> (5.3.12)
- definition of "charset" in <script> (5.3.12)
- revised prefetch (6.1)
- effect of "fetchhint" attribute (6.1.1)
- caching policy selection (6.1.2)
- caching follows HTTP 1.1 cache correctness rules (6.1.2)
- format of platform-specific properties (6.3.1)
- definitions of "completetimeout" and "incompletetimeout"
speech recognizer properties (6.3.2)
- definition of time designation values (6.5)
- Using tentative media types (e.g. "application/grammar+xml")
submitted to IETF for approval
- language specifies set of required audio formats for
<audio> and <record> (1.2.4).
- capabilities of conforming VoiceXML platform with respect to
speech and dtmf grammars, audio, TTS, record, and transfer
support (1.2.5).
- platforms should identify themselves with User-Agent HTTP
header (1.2.5).
- description of how semantic interpretations are mapped to
form variables (3.1.6).
- reserved the variable namespace "_$" for internal use (5.1).
- use of variables and form items with names "session",
"application", "document", and "dialog" not recommended (5.1.2).
- revised definition of Conforming VoiceXML Processor,
including requirement to support syntax and semantics of all
elements described in this document (Appendix F).
- set of required audio formats (Appendix E).
- reusability appendix (Appendix
K).
K.1 Reusable dialog components
Definition: A packaged application fragment designed to
be invoked by arbitrary applications or other Reusable Dialog
Components. A Reusable Dialog Component (RDC) encapsulates the
code for an interaction with the caller.
Reusable dialog components provide pre-packaged functionality
"out-of-the-box" that enables developers to quickly build
applications by providing standard default settings and behavior.
They shield developers from having to worry about many of the
intricacies associated with building a robust speech dialog,
e.g., confidence score interpretation, error recovery mechanisms,
prompting, etc. This behavior can be customized by a developer if
necessary to provide application-specific prompts, vocabulary,
retry settings, etc.
In this version of VoiceXML, the only authentic reusable
component calling mechanisms are <subdialog> and
<object>. Components called this way follow a model similar
to subroutines in programming languages: the component is
configured by a well-defined set of parameters passed to the
component, the component has a relatively constrained interaction
with the calling application, the component returns a
well-defined result, and control returns automatically to the
point from which the component was called. This has all the
significant advantages of modularity, reentrancy, and easy reuse
provided by subroutines. Of the two kinds of components, only
<subdialog> components are guaranteed to be as portable as
VoiceXML itself. On the other hand, <object> components may
be able to package advanced, reusable functionality that has not
yet been introduced into the standard.
K.2 Templates and samples
Although reusable dialog components have the advantages of
modularity, reentrancy, and easy reuse as described above, the
disadvantage of such components is that they must be designed
very carefully with an eye to reuse, and even with the most
careful of designs it is possible that the application developer
will encounter situations for which the component cannot be
easily configured to handle the application requirements. In
addition, while the constrained interaction of a component with
its calling environment makes it possible for the component
designer to create a component that works predictably in
disparate environments, it also may make the user's interaction
with the component seem disconnected from the rest of the
application.
In such situations the application developer may wish to reuse
VoiceXML source code in the form of samples and templates -
samples designed for easy customizability. Such code is more
easily tailored for and integrated into a particular application,
at the expense of modularity and rentrancy.
Such templates and samples can be created by separating
interesting VoiceXML code from a main dialog and then
distributing that code by copy for use in other dialogs. This
form of reusability allows the user of the copied VoiceXML code
to modify it as necessary and continue to use their modified
version indefinitely.
VoiceXML facilitates this form of reusability by preserving
the separation of state between form elements. In this regard,
VoiceXML and HTML are similar. An HTML table can be copied from
one HTML page to another because the table can be displayed
regardless of the context before or after the table element.
Although parameterizability, modularity, and maintainability
may be sacrificed with this approach, it has the advantage of
being simple, quick, and eminently customizable.
This W3C specification is based upon VoiceXML 1.0 submitted by
the VoiceXML Forum in May 2000. The VoiceXML Forum authors were:
Linda Boyer, IBM; Peter Danielsen, Lucent Technologies; Jim
Ferrans, Motorola; Gerald Karam, AT&T; David Ladd, Motorola;
Bruce Lucas, IBM; Kenneth Rehor, Lucent Technologies.
This version was written with the participation of members of
the W3C Voice Browser Working Group.The following have
significantly contributed to writing this specification:
- Dan Burnett, Nuance Communications
- Deborah Dahl, Unisys
- Peter Danielsen, Lucent
- Martin Dragomirecky, Cisco
- Jim Ferrans, Motorola
- Andrew Hunt, SpeechWorks International
- Gerald Karam, AT&T
- Dave Ladd, Dynamicsoft
- Paul Lamere, Sun Microsystems
- Bruce Lucas, IBM
- Scott McGlashan, PipeBeach
- Mitsuru Oshima, General Magic
- Brad Porter, Tellme
- Ken Rehor, Nuance Communications
- Steph Tryphonas, Tellme
The Working Group would like to thank Dave Raggett and Jim
Larson for their invaluable management support.