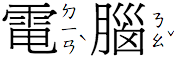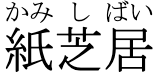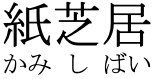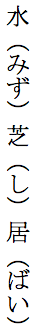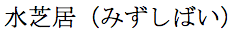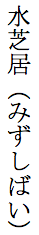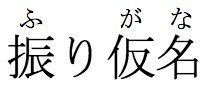Ruby is a name given to the small annotations, typically used in Japanese, Chinese and Traditional Mongolian content, that are rendered alongside base text, usually to provide a pronunciation guide, but sometimes to provide other information.
The term 'ruby' was adopted into Japanese typesetting after originally being used for British printing. In China these may be called 'interlinear annotations'. In this article we use the word 'ruby' to refer to the combination of 'base characters' plus their 'annotations'.
We will assume that you are familiar with ruby, and how you want it to look. (If not, see the short overview of how ruby works.)
This article will only discuss how to use CSS styling to affect the rendering of ruby content. For information about how to create the markup needed to support ruby, see Ruby Markup.
The draft of the CSS Ruby Layout Module Level 1 provides a number of initial properties for describing the placement of ruby text in relation to the base text. Later versions of the spec are expected to add more properties. Note that this specification is not yet finalized, so this page will aim to give you an idea of what to expect if it is fully implemented, as well as describing what is currently supported.
We won't simply reproduce the spec itself here, but rather provide guidance about how content authors can achieve key techniques. We will assume that your ruby content is marked up appropriately, so that the mapping between ruby bases and ruby text is correct.
Basic configurations
This section describes typical scenarios for Japanese and Chinese. The expected behavior is based on the layout requirements documents for Japanese (JLReq) and Chinese (CLReq). Only the more common configurations are described here; subsequent sections will explain how to produce these configurations, and how to tailor the results.
What follows assumes that you have used markup to map ruby text annotations to base characters appropriately, as described in the article Ruby Markup.
Japanese
Mono ruby is typically used to represent pronunciation of Japanese kanji characters. Each ideographic base character is mapped in markup to an annotation that indicates how to pronounce it (usually using hiragana).
As you can see in the following example, the annotations don't overlap adjacent kanji characters, and they are normally centred relative to the base character (in Japanese this is called nakatsuke). Lines can break between the base characters.
Typical Japanese ruby.
If the annotation doesn't fit over the base character you can expect one of the following things to happen.
If the character alongside is a kanji character, the base characters will be spaced a little wider so that the ruby text doesn't overlap.
If the character alongside is punctuation or kana, the annotation will overlap it up to a certain point.
If the base character is next to the line start or end, a little extra space will be added alongside the base character so that the annotation doesn't stick into the margin.
This behaviour is currently browser dependent, rather than specified using CSS.
A jukuji annotation occurs where a sequence of base characters has a different pronunciation from what you would expect by looking at the individual base characters, eg. 田舎 (pronounced いなか). Because the kana don't map to individual base characters, you will need to use group ruby: a single annotation is mapped in markup to a range of base characters. The kana annotation is normally spread across the base text evenly, with a little extra space at either end. If the annotation is in the Latin script, however, it is normally centred on the base text. Base characters in group ruby are not split across line breaks.
Jukugo ruby (note that this is a different term from jukuji!) is a term used to describe special treatment of annotations for compound nouns (jukugo in Japanese). Essentially the annotations for compound nouns can be spread across all of the base characters in the word, like group ruby, but a word can still be split at the end of a line, like mono ruby. Furthermore, the distribution of the annotations for a word may follow detailed rules with regards to allowable overlaps, so that they are not necessarily equally spaced as per group ruby. See some examples.
Sometimes ruby annotations appear on opposite sides of a base character at the same time. In such cases, the top/right annotation is typically phonetic and uses mono ruby, and the bottom/left annotation is most likely group ruby and provides additional information about the base text.
Annotations and base text may be aligned at the start in vertical text, but are usually centred on the base in horizontal text.
The sections lower down this page indicate how you can change some of these basic styles.
Simplified Chinese
In Mainland China phonetic annotations normally consist of pinyin transcriptions, which are written in the Latin script. Content annotated with pinyin is usually only set horizontally. This is fortunate since Latin text would be set sideways in vertical text, making it harder to read.
There are two common approaches to phonetic annotation: character based and word based.
Character based annotations are common in text used for Chinese children, whereas word based annotations are often found in texts for those learning the Chinese language.
For character-based phonetic annotations, you will need to use markup to map each ideographic base character to an annotation which indicates the pronunciation. This is mono ruby. The annotations usually appear above the base text.
Character-based phonetic annotations using pinyin.
Word based phonetic annotations use group ruby, associating one annotation with more than one base character, and forbidding line breaks inside the annotation. Note how the top line in fig_chinese_group_ruby no longer breaks between the two parts of the word lizhi.
Word-based phonetic annotations using pinyin.
In both of these examples, the annotations are centred above the base text.
Annotations representing meaning or commentaries are common in light novels and translated works, and tend to describe phrases or words. They may contain casing, punctuation, and spaces, and may contain Chinese text explaining Latin base text, or vice versa, and they may appear on the opposite side of the base to phonetic annotations. Sometimes phonetic annotations are also placed below/left of the base.
Word-based phonetic annotations using pinyin placed below the base characters.
As for the Japanese section above, if the annotation doesn't fit over the base character you can expect one of the following things to happen.
Since the annotations are often long, compared to the width of the Han base character, care may need to be taken to ensure that long pinyin annotations don't run into each other. To accomodate this, the tracking of the base text is often increased, to provide additional room. Occasionally, the size of the annotation text may be reduced. There may be some cases where annotations slightly overlap adjacent bases, but only while preserving a minimum space between annotations.
If the annotation is longer than the base and is next to the line start or end, both the annotation and the base text can be aligned with line head or end. A little extra space will be added on the other side of the base character so that the annotation fits.
The syllabic nature of the script makes it fairly easy in most cases to spot the start and end of an annotation, but when adjacent annotations are longer than the base, they should ideally be separated by about a ¼em or ½em space.
In some cases, care may need to be taken to ensure that long pinyin annotations don't run into each other. This can be achieved by increasing the tracking of the hanzi characters or by reducing the size of the annotation text.
Traditional Chinese
In Traditional Chinese, bopomofo (zhùyīn fúhào) ruby nearly always appears to the right of the base character, whether the text is set horizontally or vertically. Furthermore, the bopomofo annotation is always set vertically and the tone marks (apart from the light tone) are displayed in an additional column to the right of the bopomofo characters. The tones are not combining marks, and the vertical position of the tone mark depends on the arrangement of the phonetic symbols in the previous column.
Bopomofo (zhùyīn fúhào) annotations alongside Traditional Chinese characters.
Find more information about Bopomofo usage in Traditional Chinese.
Positioning ruby relative to the base text
Here we look at how you make the ruby text appear above or below the ruby base text, or to the side for bopomofo ruby.
A later section will describe how to display the annotation inline, ie. alongside the base with equal-sized characters.
Positioning ruby text 'over' the base
By 'over' we mean above horizontal text and to the right of vertical text.
ruby-position set to over.
This is the default behavior, and you can expect browsers to produce this without CSS.
If you need to place the ruby explicitly in this position, use:
ruby { ruby-position: over; }
Output in your browser:
紙芝居
紙芝居
Positioning ruby text 'under' the base
To position the ruby text below horizontal base text or to the left of vertical text, use ruby-position: under.
ruby-position set to under.
This position is often used in Japanese for semantic information (as opposed to phonetic labelling). It is also used sometimes for pinyin annotations in Chinese. Here is an example from the moedict dictionary.
An example of ruby on more than one side of the base characters.
To produce this effect, use:
ruby { ruby-position: under; }
Output in your browser:
紙芝居
紙芝居
Positioning bopomofo ruby
In Traditional Chinese, bopomofo (zhùyīn fúhào) ruby appears to the right of the base character, whether the text is set horizontally or vertically. Furthermore, the bopomofo annotation is always set vertically and the tone marks (apart from the light tone) are displayed in an additional column to the right of the bopomofo characters.
Bopomofo ruby is set to the right side, on a character by character basis.
What you have to do in CSS is indicate that this will be bopomofo ruby, so that the annotation doesn't appear 'over' or 'under' the base text. To do that, you need the inter-character value of ruby-position.
The vertical placement for the bopomofo and the relative position of the tone characters within the invisible column to the right of the Han base character rely on the browser, or possibly font information. You don't need to specify anything more in CSS.
ruby { ruby-position: inter-character; }
Output in your browser:
電腦
電腦
Positioning double-sided ruby
Occasionally, it is necessary to associate more than one annotation with the same base text. In this case, you need to specify which annotation goes where.
Ruby annotations on two sides of the same base text.
This is complicated a little by the fact that there are two possible ways to create markup for double-sided ruby (see the Ruby Markup article for more details).
If you use the 'tabular' model of markup, the styling is reasonably straightforward and involves setting ruby-position on the appropriate rtc element. Given markup such as the following:
When the ruby text annotation is longer than the ruby base it belongs to, or vice-versa, there can be several different ways of dealing with the extra space that is lying around. The CSS Ruby spec deals with this mostly through the use of the ruby-align property.
It's best to use this property on the ruby element.
If you are working with inter-character bopomofo ruby, none of this is relevant, since the positioning of the bopomofo characters and tone marks is fixed.
Most examples in this section use the following markup:
<ruby><rb>浮世絵<rt>うきよえ<rb>昔話<rt>むかしばなし</ruby>
Output in your browser with no CSS specified:
浮世絵
Aligning to one edge
If you want to align the edges of the annotation and the base, you can use the start value of ruby-align. (An older version of the Ruby CSS spec also included an end value, but that has been removed from the current version of the spec.)
This kind of alignment is mostly used for vertical Japanese text. (Horizontal Japanese text more often uses centering.)
Note, also, that applying this setting doesn't currently handle automatically certain requirements that may arise with regards to overflow and interaction with line edges in traditional printed text.
ruby { ruby-align: start; }
Output in your browser:
浮世絵昔話
浮世絵昔話
Centering shorter items of text
If you want the shorter of the ruby base or ruby text to be centered, with the characters set solid, rather than aligned with an edge, it will hardly come as a surprise to learn that you just need to set the value of ruby-align to center.
ruby { ruby-align: center; }
Output in your browser:
浮世絵昔話
浮世絵昔話
Applying justification to shorter items of text in group ruby
This section applies when both the bases and the annotation contain multiple characters – in other words, group ruby.
If you want to use up redundant space by stretching the shorter text, be it the annotation or the base, you have two choices: you can justify the shorter text from edge to edge of the longer one (space-between), or justify across a space that is slightly smaller than the full width available (space-around). Note, however, that the justification outcome differs according to what scripts are involved.
The default setting is space-between.
Justifying Japanese annotations
Let's look first at what happens if the characters in your ruby annotation are kanji characters and kana characters. This is likely to be the case for Japanese ruby, and will typically apply when dealing with jukuji or semantic annotations.
To widen the shorter text to exactly the same width as the longer text, stretching the inter-character spaces equally, use the space-between value of ruby-align.
ruby { ruby-align: space-between; }
Output in your browser:
浮世絵昔話
浮世絵昔話
Or you can stretch the text in the same way, but not quite so far, leaving half a character width of space on either side, as shown here. For this you use the space-around value.
ruby { ruby-align: space-around; }
Output in your browser:
浮世絵昔話
浮世絵昔話
Pinyin & other Latin script annotations
Here we look at what to expect if either the base or the annotation uses a script such as Latin for pinyin. For Chinese ruby that doesn't use bopomofo, this is the most likely case. Occasionally, Japanese may also use Latin annotations, in which case the same rules apply.
You should expect the annotation to be centered, as shown below. Space is not distributed between each character, as it is when the annotation uses kana or han characters. If there are spaces in the shorter text, the annotation should still be centred, even if you are applying the space-between and space-around values of the ruby-align property.
Latin script annotations are centred relative to a longer base.
ruby { ruby-align: space-between; }
Output in your browser:
洗衣机周杰伦
There is no difference in styling for the two example words shown above – we simply removed the spaces from the pinyin on the left.
Working with jukugo ruby
The CSS Ruby specification describes a method of handling jukugo ruby using the ruby-merge property. This allows you to indicate, through styling, whether the annotations associated with a compound noun in Japanese should be applied like mono ruby, or spread across the whole word like group ruby. In the latter case, however, a line can be broken inside a compound noun, so it differs slightly from the normal group ruby in a way that jukugo handling typically works in Japanese.
In the latter case, the browser could specify more detailed rules about how to align the annotations across the compound bases. This allows rules of (internal) overlapping to be more fluid in jukugo ruby than in mono ruby.
Unfortunately, at the time of writing, the ruby-merge property is not supported by any of the major browser engines, so for now we will omit a description of how this works.
Rendering annotations inline
In some situations you may want the annotations to appear inline, after the base text. For example, the Ruby markup article describes how complicated kanji characters with ruby on top can create accessibility issues. In other cases you may want to do this because the user interface is too small for ruby text to be legible, or because you want to repurpose the content for another type of application, etc.
When both base text and annotation are side by side on the same line, it's important to be able to identify which is the annotation, and where it starts and ends.
The chief issue with all these approaches is that there isn't one set of CSS rules that can be applied to all content. If your page mixes the rp, interleaved, and tabular approaches, you'll need to use classes to indicate which set of CSS rules to apply to that particular ruby element.
Working with rp markup
If you use rp markup to specify what characters to use as delimiters and where to place them, you need to render the annotation inline and make the delimiters (which are invisible by default) visible.
You could use this, which changes the display value for the rt element and sets the font size to be the same as the base text (overriding the default size for the rt element set by the browser).
The rest of this section looks at how you can use CSS if your content doesn't have rp markup.
Working with interleaved markup
If you are quite happy for annotations to appear immediately after the base character(s) they are attached to, your content may be using the interleaved approach to ruby markup, and the expected outcome would be like this.
`
Expected inline display of ruby text using interleaved markup.
In addition to making the rt content display appropriately inline (as mentioned earlier), you will also need to surround each annotation with something, to set it off from the base text. Here we use the before and after pseudo-elements to surround it with parentheses.
If you want all the annotations for a given word to follow that word, grouped together as shown here, your content will use the tabular markup approach. This approach generally provides a more useful outcome than that produced by interleaved markup.
Expected inline display of the same text using tabular markup.
Producing inline annotations in this case is a little more complicated if you're not using rp markup.
You may want to attach ruby annotations to a word such as 振り仮名 (furigana) without adding the redundant り.
The word 'furigana' doesn't need a redundant hiragana character as an annotation, but is still treated as a single word when applying markup.
In the examples shown below we use interleaved markup, since that is better supported at the moment. The same principles should, however, apply if tabular markup is used.
One way to achieve this would be to simply leave a blank rt element, like this:
However, this is not ideal. In particular, this would pose a if you wanted to display the annotation inline and you are using the (generally preferable) tabular model of markup: instead of 振り仮名(ふりがな) you would see 振り仮名(ふがな). It can also present problems if you want to merge ruby annotations across a compound noun (something which may be introduced later).
The CSS spec proposes a solution for handling these unnecessary annotations: if the base text and corresponding annotation are identical, browsers should not show the annotation unless it is part of an inline sequence. So you could use the following code to produce this effect, without any special styling, if the browser supports it.