Warning:
This wiki has been archived and is now read-only.
FinalReport
- Editors
- Harry Halpin, W3C and University of Edinburgh
- Mischa Tuffield, Garlik Ltd
- Authors
- Daniel Appelquist, Vodafone
- Dan Brickley, Vrije University Amsterdam
- Melvin Carvahlo
- Renato Iannella, Semantic Identity
- Alexandre Passant, DERI, NUI Galway
- Christine Perey, PEREY Research & Consulting
- Henry Story, Sun Microsystems
- Abstract
-
This document is the final report of the W3C Social Web Incubator Group. This report presents systems and technologies that are working towards enabling a Social Web, and is followed by a strategy for standardizing this work in order to ensure the Social Web is open, decentralized, and royalty-free. This report focuses on work that permits the description and identification of people, groups, organizations, as well as user-generated content in extensible and privacy-respecting ways. This report describes a common framework for the concepts behind the Social Web and the state of the art in 2010, including current technologies and standards. We conclude with an analysis of where future research and standardization will benefit users and the entire Social Web ecosystem's growth. We also suggest a strategy for the role of the W3C in the Social Web.
- Status of this Document
- Copyright © 2010 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Contents
- 1 Overview
- 2 State of the Social Web in 2010
- 3 Social Web Frameworks
- 4 Identity
- 5 Profiles
- 6 Social Media
- 7 Privacy
- 8 Activity
- 9 Accessibility Concerns
- 10 Decentralized Social Networking Projects
- 11 Business Considerations
- 12 Conclusions: A Strategy for the Social Web
- 13 Acknowledgements
- 14 References
Overview
The Social Web is a set of relationships that link together people over the Web. While the best known current social networking sites on the Web limit themselves to relationships between people with accounts on a single site, the Social Web should extend across the entire Web. Just as people can call each other no matter which telephone provider they belong to, just as email allows people to send messages to each other irrespective of their e-mail provider, and just as the Web allows links to any website, so the Social Web should allow people to create networks of relationships across the entire Web, while giving people the ability to control their own privacy and data.
The Social Web is not just about relationships, but about the applications and innovations that can be built on top of these relationships. Social-networking sites and other user-generated-content services on the Web have a potential to be enablers of innovation, but cannot achieve this potential without open and royalty-free standards for data portability, identity, and application development.
The Social Web Incubator Group (SWXG) was founded as an outcome of the W3C Workshop on the Future of the Social Networking to uncover and document existing technologies, software, and standards (both proposed and adopted) needed to enable a universal and distributed Social Web. The group also sought to identify gaps, conflicts, and other areas for future standardization and research to increase adoption of the Social Web.
Over the course of the SWXG’s activity the, approximately thirty, participants on the conference calls discussed a wide variety of topics and heard from over thirty invited guests from within and outside the W3C. We conclude that while the Social Web is a space of innovation, it is still not a "first-class" citizen of the Web: Social applications currently largely evolved as silos and thus implementations and integration are inconsistent, with little guarantees of privacy and enforcement of terms-of-service.
Further, the members of the XG conclude:
- The Social Web does not suffer from a lack of potential standards. A large number of diverse groups have evolved data models, communication protocols, and data formats at tangents to one another, addressing a large number of communities, each of which has its own terminology and viewpoint.
- While there has been a large amount of work done in this area, in terms of both current potential and standards, these tend to address basic issues around identity and portability, but do not address more complex and vital issues such as privacy, policy enforcement, and provenance. All of these issues are present scope for further research and the development of future standards.
- The creation of a decentralized and federated Social Web, as part of Web architecture, is a revolutionary opportunity to provide both increased social data portability and enhanced end-user privacy.
- One key to make ordinary users take advantage of a decentralized Social Web is to build identity and portability into the browser and other devices.
We respectfully recommend to the W3C areas of future work in which the W3C should play a pivotal role:
- Investigate how identity can become a central part of the Web by supporting solutions that would allow for a high-level of security, multiple identities, and that are decentralized in nature. The W3C can focus on the topic of identity in the browser initially and its work should be coordinated with existing identity work and communities.
- Define mappings between existing data-formats for profiles on a semantic level, making sure that a common core is available in a consistent manner across various syntactic serializations.
- Start work combining the Social Web with the Semantic Web to enable people to describe social media, with a focus describing terms-of-service agreements, licensing, and micropayment information using standardized vocabularies, which should be easy to find and use.
- Begin an over-arching privacy activity for the W3C, exploring the combination of technical and social approaches. All W3C Recommendations should be inspected for privacy concerns.
- Support the Federated Social Web effort by providing resources to the test-case driven development of a decentralized social web.
- Create a more "light-weight" and open process so that groups working on the Social Web are able to work with the W3C and
This work could form the basis of new Working Groups, improved liaising with non-W3C efforts and standardization bodies, and increased co-ordination and focus on the Social Web among existing W3C working groups.
State of the Social Web in 2010
2010 has been a tumultuous year for the Social Web. However, the Social Web is not a new phenomenon that has no precedent, but the result of a popularization of existing technologies. Many social features were available over the Internet before the Web, ranging from the blog-like features of Engelbart's "Journal" system in NLS (oN-Line System, the second node of the Internet), messaging via e-mail and IRC, the Well (1984), and the "Member Profiles" of AOL. The "list of friends", that is ubiquitous on the Social Web, existed in the hand-authored links on the earliest webpages. The Web has always been social. As shown by this diagram below by Tim Berners-Lee in his original 1989 proposal to create the World Wide Web, the Web from its inception was meant to include connections between not only hypertext documents, but the relationships between people.
What was missing was an easy-to-use interface to make finding people you know and sharing data with them easily accessible. A number of websites, ranging from Classmates.com (1995) to SixDegrees (1997), pioneered these features for ordinary users of the Web. Since the early days of the Web people that maintained their own homepages have been posting activity updates to their sites, and this has been pushed into the mainstream with the development of user friendly blogging software (from "web logs") such as LiveJournal and Blogger in 1999. Innovations in this space allowed the general public to become more and more apt at blogging, and independent news sites such as Indymedia (1999) pioneered the notion of user-generated content management. However, these services remained fairly experimental up until after the collapse of the initial "dot-com" bubble. After this a rash of social networking sites like Friendster (2002), LinkedIn (2003), MySpace (2003), Orkut (2004), and Facebook (2004) took off, and eventually became the most popular sites on the Web. Starting with Flickr (2004) and Youtube (2005), user-generated content took over this newly re-invigorated Social Web. The launch of Twitter (2007), a micro-blogging site, which propagated updates to users' social networks, via desktop and mobile devices, showed another dominant trend in the Social Web. It was around this time that the concept of the Social Web became associated both with the aforementioned companies and with the wider "Web 2.0" paradigm. Today, the Social Web is becoming part of corporate communication portfolios and Web 2.0 companies start commercializing data from and about their users.
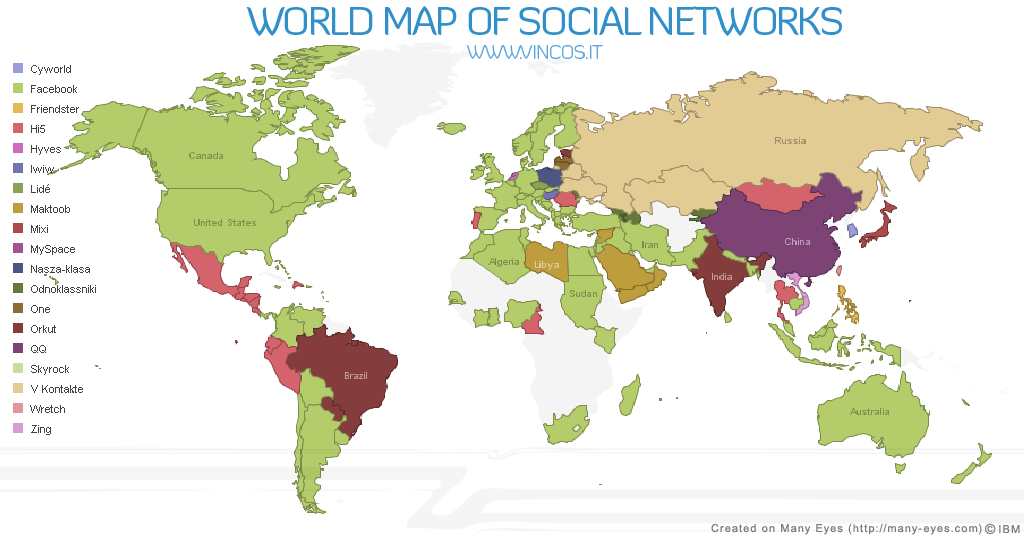
While the world remained incredibly geographically disparate over a number of these sites, as illustrated by this map, with many countries developing their own most popular social networking sites such as Hi5 in Japan and QQ in China, there has been an overall tendency towards users moving their profiles between services, such as users moving their profiles from Friendster to MySpace for example. This, in turn, led to a dismissive attitude by some that the most "popular" social networking sites would simply turn over every year or two. In a similar manner to how competition amongst search engines eventually led to the dominance of Google, Facebook rapidly rose to become a global leader in social networking. A number of major vendors began either purchasing social networking sites (such as the purchase of Blogger (2003) and Orkut (2007) by Google) and other companies like Yahoo! trying to roll their-own social networking sites like Yahoo! 360 (2005). Social Web features, such as comments and user-generated content, became intertwined with such phenomenon as Flickr for sharing photos and YouTube for sharing video. Today, it is a de-facto requirement for Web sites to have social features and for individuals and organizations to have a presence on popular social Web platforms. Yet the ways for web-sites to do so are currently fractured and have yet to be standardized.
{kind=link}
While empowered by the compelling user experience of these social networking sites, the real victim of these data-silos has been the end-users. Social networking sites encourage users to put their data into the given proprietary platform, and have tended to make the portability of the user's own data to another site or even their home computer difficult if not impossible. Architects of new Social Web services and user-advocacy groups began to ask for the ability of users to move their data from platform to platform. The first technology created specifically for a portable social graph was the Friend-of-a-Friend project for the Semantic Web (FOAF) in 2001, and in 2005, a biannual gathering of developers started the Internet Identity Workshop from which standards like OpenID emerged. Momentum took off after Brad Fitzpatrick (formerly of Livejournal)'s post on "Thoughts on the Social Graph", together with David Recordon, in 2007. There was quickly following a number of initiatives like the DataPortability initiative, the Data Liberation Front at Google, and lately, the Federated Social Web initiative. This momentum continued to attract interest, however, at the same time an open and decentralized Social Web still seems distant and few users have actually left these data-silos.
Many social networking sites considered privacy and portability to be contradictory, insofar as Facebook used to deny users the ability to let data be portable outside its system due to concerns over user privacy, as their terms of service in 2006 stated that "We understand you may not want everyone in the world to have the information you share on Facebook; that is why we give you control of your information." In one particularly infamous incident, in 2008 blogger Robert Scoble wanted to make their information portable by copying his contacts from Facebook, but had his account disabled by Facebook. However, in 2009 there seemed to be little concern about issues of privacy and portability except amongst those deeply immersed in designing social networking platforms, with only 20 percent of users listing privacy as a primary concern motivating their choice in Social networking sites. Whilst the market for online social networking remains competitive, privacy has yet to emerge as a competitive advantage. Today, privacy is a secondary argument to stimulate new sign-ups. Widespread usability problems impede users to exercise effective control over their personal information on social networking sites, where permissive defaults are another threat to privacy. While Scott McNealy of SUN infamously remarked that "You have zero privacy anyway," recent studies show that youth have "an aspiration for increased privacy" and are equally concerned about privacy as adults PEW.
As more people are adopting Web-enabled smartphones, with mobile users spending more minutes per day on social networking sites than the average PC user, in 2010 30% of smartphone users accessed social networks via mobile browsers, the mobile Social Web must not be ignored. Users seem attracted to mobile device access because they can consult with friends and quickly make decisions while remaining mobile, allowing users to use applications in a context such as the live-tracking of buses. Many popular social networks at the time of writing this report tend to offer both a Web-based version, and a dedicated application which can be downloaded for the given smartphone platform. These dedicated applications tend to be able to make much greater use of built in sensors, and applications found on these smartphones. As several mobile social networking sites allow users to both upload their location and see the location of their friends, a number of small groups have joined together to form the OSLO alliance (Open Sharing of Location-based Objects). OSLO includes many players in mobile social networking and location-based social software which have signed an agreement to enable their approximately 30 million users to share location information between mobile social networks, in essence supporting the portability of location information between services. However, this activity seems to have stalled and the W3C Device API WG is quickly filling the gap by standardizing a set of APIs to be implemented by mobile browsers to cater for access to device functionality, such as a user's address book, calendar, location, within a Web Application running inside a standard mobile browser. As more and more of Web usage goes mobile and data access speeds increase, one can expect the difference in capabilities between the Web and the mobile Web to diminish.
2010 was the year in which the issues of privacy on the Social Web grew beyond a niche concern and entered the popular consciousness. In December 2009, Facebook changed its privacy settings by defaulting certain privacy settings which in turn made part of a user's profile information public. Users were encouraged to use "privacy controls" to provide access control to their data, but many users found these controls to be confusing and the default settings led to revealing lists of friends. This sparked widespread outrage, even amongst the governments. The development of Facebook OpenGraphProtocol and other more distributed services led Facebook's Terms of Service to become even more open with users data, such as "When you connect with an application or website it will have access to General Information [which includes] your and your friends’ names, profile pictures, gender, user IDs, connections, and any content ... the default privacy setting for certain types of information you post on Facebook is set to everyone." Google long supported the general notion of portability, and its OpenSocial API (and Open Social Alliance) and Google FriendConnect starting to lay the ground for a distributed portable social platform. However, Google's attempt to transform their popular Gmail into a social networking platform via Google Buzz in 2010 also led to massive privacy concerns amongst users: Buzz users saw their most frequent communication partners exposed publicly and needed to opt-out to have them concealed. Overall, at this moment in 2010, privacy is returning as a major concern. Furthermore, none of the concerns about the portability of social data have been addressed in a manner that is widely implemented across social Web platforms, leading to a fragmentation of identity and a generalized lack of portability and privacy on the Social Web.
In 2009 the World Wide Web Consortium held a workshop on the "Future of Social Networking" in Barcelona, and, shortly thereafter, launched the Social Web Incubator Group to investigate future work in the area of the Social Web. Tim Berners-Lee proposed Socially Aware Cloud Computing, where he illustrated how the technologies required to have a decentralized socially aware Web were available and how it is but a matter of engineering to realize this forward. Overall interest still remains high as witnessed by the launch in 2010 of products like Vodafone's OneSocialWeb and the open-source Diaspora Project, and the first attempt at developing a common test-suite across differing standards-based social networking sites at the Federated Social Web Summit. At this point in history, the Social Web has became the dominant platform for communication, rapidly beginning to even eclipse the use of e-mail among youth. The next steps the companies and communities around the Social Web take will have real consequences on the future of the Web and communication itself.
Social Web Frameworks
The Problem of Walled Gardens
The importance of the Web has always been its open and distributed nature as a universal space of information. Until recently this space of information has been limited to hypertext web-pages without attention being paid to social interactions and relationships. This was not a particular fault of the Web, in fact but a result of a certain focus of the early Web on documents. However, these kinds of activities are currently restricted to particular social networking sites, where the identity of a user and their data can easily be entered, but only accessed and manipulated via proprietary interfaces, so creating a "wall" around connections and personal data, as illustrated in the picture below. This current dismal situation is analogous to the early days of hypertext before the World Wide Web, where various systems stored hypertext in proprietary and incompatible formats without the ability to use, globally link and access hypertext data across systems, a situation solved by the creation of URIs and HTML. A truly universal, open, and distributed Social Web architecture is needed.
The lack of such an architecture deeply impacts the everyday experience of the Web of many users. There are four major problems experienced by the end user:
- Portability: An ordinary user can not download their own data and share it how they like. Information stored on social networks could be useful for any number of applications, but the lack of portability of tediously entered social networking information causes users to continually re-enter and update their personal information, wasting their time.
- Identity: Not having a easy way to manage digital identity across digital networks leads to unsafe re-usage of passwords. Every time a user goes to a new site, they must not only create a new username and password, but re-find their friends and entice friends to move sites with them. Porting personal data from one network to another does not solve the problem of loosing one's friends if one moves.
- Linkability: Users have no way of being notified if they are being mentioned on a social networking site which they are not a member of. For example, if someone takes a photo of some friends at a party and wishes to publish it on the Web to share with those friends, but does not wish to make that publicly available, he must find a social network where each one of them is already a member, or simply not tell people that the photo has been uploaded.
- Privacy: A user cannot control how their information is viewed by others in different contexts by different social applications even on the same social networking site, which raises privacy concerns. Privacy means giving people control over their data, empowering people to they can communicate the way they want. This control is lacking if configuring data sharing is effectively impossible or data disclosure by others about oneself cannot be prevented or undone.
Participation is the life blood of social networks. If no one (or if too few people) participates, a social networking application dies. If social applications are to thrive and provide engaging and valuable services to users, they must be easy-to-use, and must support ways for people to connect with and manage their social interactions and connections across multiple sites. While we take a "user-centric" approach in this report, having a common set of Social Web standards is a "win-win" proposition for both industry and users. As portability issues prevent companies from accessing user-data held on third-party sites to build innovation and large social networking platforms themselves lack ways to easily share their data, in turn monetizing their assets.
The Social Web Vision
People express different aspects depending on context, thus giving themselves multiple profiles that enable them to maintain various relationships within and across different contexts: the family, the sporting team, the business environment, and so on. Equally so, in every context certain information is usually desired to be kept private. In the 'pre-Web world' people can usually sustain this multiplicity of profiles as they are physically constrained to a relatively small set of social contexts and interaction opportunities. In some ways, social dynamics on the Web resemble those outside the Web, but social interactions on the Web differ in a number of important ways:
- the kinds of profile exhibited by a single person are not controlled by the same constraints and so are less limited in scope, and so may include profiles for fictional personae.
- the set (number) of people with whom interactions are possible is not limited by distance or time. The Web allows for users to user connect with a vast number of people, which was inconceivable only a few years ago.
- a person can explicitly "manage" the relationships and access to information they wish to have with others and with the increasing convergence of the Web and the world outside the Web is also leading to increasing concerns about privacy as these worlds collide.
Anyone should be able to create and to organize one or more different profiles using a trusted social networking site of choice, including hosting their own site that they themselves run either on a server or locally in their browser. For example, a user might want to manage their personal information such as home address, telephone number, and best friends on their own personal "node" in a federated social network while their work-related information such as office address, office telephone number, and work colleagues is kept on a social network ran by work. Today current aggregator-based approach exemplified by FriendFeed are but a short-term solution akin to "screen scraping", that work over a limited number of social networking sites, are fragile to changes in the sites' HTML, and which are legally dubious.
The approach we endorse allows the user to own their own data and associate specific parts of their personal data directly to different social networking sites, as well as the ability to link to data and friends across different sites. For example, your Friends Profile can be exposed to MySpace and Twitter, whereas your Work Profile to Plaxo and LinkedIn, and links between data and friends should be possible across all these sites. Traditional services can utilize these features, so that your "health" profile can be exposed to health care providers and your "citizen" profile exposed to online government sites and services. In this world of portable social data, both large and small new players can then also interface to profiles and offer seamless personalized social applications.
Privacy is a complex topic, and we understand privacy as control over accessibility of social information in general, including security as an enabler (the authentication of digital identity and ownership of data). Privacy controls are often not well-understood by users and they do not stop data "leaking" from the social networking site itself, which may give user data to other companies or even governments for some kind of gain without alerting the user. Privacy should be controlled by the users themselves in an explicit contract with social networking sites and applications that lets privacy controls easy-to-use and understandable. As custodian of their own profiles, users can then decide which social applications can access which profile details via explicitly exposing personal data to that application provider, and retracting it as well, at an appropriate level of granularity. This in itself is one of the biggest challenges for the entire Web community, not just social networks, and needs a new "policy-oriented Web" architecture to support trust and privacy on the Web in the longer term. Whilst technical security is a mandatory enabler, users' effective ability to control the processing of their data is largely influenced by accessible controls, helpful user interface design with strong visual metaphors, and privacy-enhancing default settings regarding data sharing.
This Social Web architecture articulated here is not the invention of the Social Web Incubator Group, but of a long-standing community-based effort that has been running for multiple years, of which only a small fraction of have been explicitly interviewed and acknowledged by the Social Web Incubator Group. This report is dedicated to all the developers out there working to make this vision a reality.
The Terminology
As the Social Web is large and innovative space, the creation of new terms can not be avoided, but to be too loose with terminology may serve to cause confusion rather than build consensus. Building on existing work like the lexicon of Identity Commons IDLEXICON, we propose definitions for the following concepts in order to clarify our presentation:
| Concept | Definition | Graphical Representation |
| User | The user is a person, organization, or other agent that participates in online social interactions on the Web. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Identity | A single digital representation of a user. These are potentially unlimited and may coincide with different personae of the user such as a personal profile and work profile. This is a "personae" in the Identity Commons Lexicon. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Profile Attribute | Information about a user that is a component of the profile such as name, e-mail, status, photo, work phone, home phone, blog address, etc. | Error creating thumbnail: Unable to save thumbnail to destination . This is an "identity attribute" in the Identity Commons Lexicon.
|
| Social Connection | Social connection are associations between a profile and a resource (or group of resources) and may include the type of the relationship (e.g. friend, colleague, spouse, likes etc) and may be either reciprocal ('friend') or uni-directional (following). The connection may be between different users or between a user and some social media (a video or an item the user likes). The collection of all connections of a profile is called the Social Graph of that profile. | Error creating thumbnail: Unable to save thumbnail to destination Error creating thumbnail: Unable to save thumbnail to destination
|
| Social Group | Social Groups are explicit named sets of social connections between resources. For example, My Football Team, Wine Club, My Favorite Movies, etc. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Social Platforms | Social platforms refer to a collection of features in which the user can interact with their social connections and social media, publish social media, and use social applications. The social platform is often centered on a single web site,a 'social networking site analogous to Facebook or LinkedIn, but may also be owned and controlled by the user. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Distributed Social Graph | A set of profiles and social connections between agents which may be hosted across different social platforms. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Social Applications | Social Applications are functions of a social platform such as real-time messaging and social games. Social applications may be bound to a particular social platform (Facebook and FBML, Twitter and Twitter OAuth) or capable of running across multiple social platforms (OpenSocial). Note that the difference between a social platform and a social application is often fuzzy, as some platforms do not allow third-party applications, and some platforms are indistinguishable from their applications. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Profile Association | A kind of social connection. A profile associations are used to indicate the link between a specific profile and a social platform. The social platform can then provide profile attributes for use to social applications. | Error creating thumbnail: Unable to save thumbnail to destination
|
| Social Interaction | A social interaction links a Social Web user and a social platform by providing all the necessary applications and profile information. | Error creating thumbnail: Unable to save thumbnail to destination
|
Social Web User and Profiles
Figure 1 below shows how a single user (one person) can have multiple profiles that share common attributes. A user can then associate his/her profile at the profile level with particular social applications, controlling them in some sort of aggregated view that the user may have on either a desktop application access via an aggregator. The profiles are exposed to and/or synchronized with different social platforms. In some cases, the social platform will update a profile property and this modified property will be reflected across all profile instances. The attributes included in a profile will depend greatly on the needs and desires of the user and context of each social application, including dynamic attributes that capture the evolving changes of a person’s context, such as geolocation attributes. In Figure 1, one profile is associated with the "light blue" and "red" social applications, one profile to the "grey" social application, and one profile to the "blue", "green", and "orange" social applications.
Single Distributed Social Graph
Attributes within a profile, including information about social connections, may be distributed. This means that the relevant attributes and social connections could be stored with a social application for use in the context of that application. For example, a work phone attribute is stored by my current employer's social platform, but another social platform (e.g., LinkedIn) may store my previous employer's information. Together, these two (distributed) attributes can be considered a distributed single "work" profile whose information I may want to combine in context of a social application (such as a job-hunting social application). Figure 2 below shows a profile that has two sets of two attributes at distributed sites each with two local attributes. The user is interacting with the profile through the "blue" social platform, which could be a node in a decentralized Social Web platform. For example, a profile management service that could be ran in the browser or via a third-party web-site would keep track of the distributed attributes and multiple profiles and allow the user to edit the attributes across multiple platforms.
Multiple Distributed Social Graphs
A profile is associated with one or more social platforms in which the user's social graph is formed and nurtured. The social platform is the context for how a user is connected to the profiles of others and will support the specific connection types (e.g. friend, colleague, likes, etc) that will typically serve the purpose of some social application. A core feature or service of a social application is to make, maintain, and expand these connections.
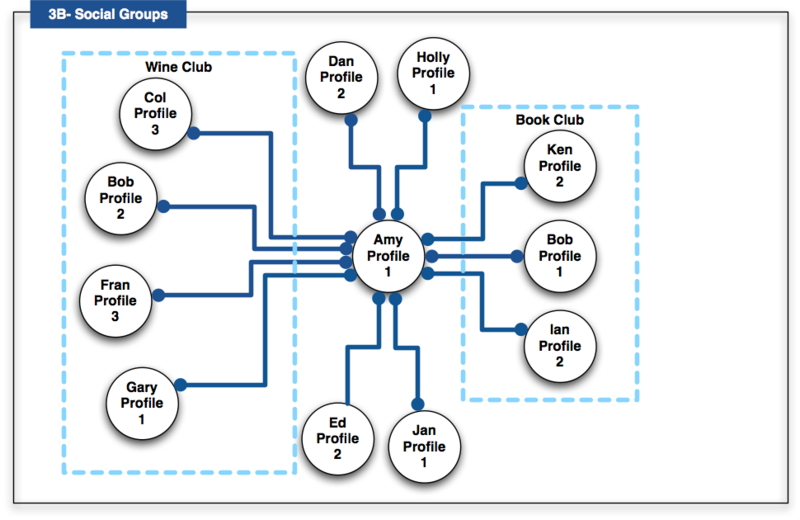
A user’s connections in a particular social platform should be portable. The user should be able to take them to another social platform, so it is not necessary to re-establish all connections again in another (new) social application. Note that Amy (Profile 1) in the "blue" social platform is connected twice to Bob via his Profile 1 and 2. This demonstrates that the same user can connect via different social platforms. The social platforms do not necessarily have to be controlled by any social platform, but could be links through the open Web. The lines between profiles are either uni-directional (such as Twitter) or bi-directional (such as Facebook) to capture where the connection is or one-way (following) or mutual (friendship). Two dots means that the connection is bi-directional. One dot means the connection or association it is not reciprocal.
Figure 3A shows an example of multiple distributed social graphs with a number of different users, profiles, and social platforms. For example:
- The blue social platform connects Amy (Profile#1) to Bob (Profile#2), Col (Profile#3), Dan (Profile#2), Bob (Profile#1).
- The green social platform connects Amy (Profile#1) to Fran (Profile#3), Gary (Profile#1), Ed (Profile#2).
- The orange platform connects Bob (Profile#1) to Amy (Profile#2), Fran (Profile#1), Ed (Profile#7).
- The red social platform connects Ed (Profile#7) to Dan (Profile#2).
Figure 3B shows an example of explicit groups. In this example, Amy has designated a number of her connections into two groups. These named groups then enable Amy to refer to the collection of connections in a single instance. For example, "allow my book reviews to be read by my Book Club members only", and with global digital identities and profile information, these groups could encompass users across many social platforms.
So far, an emphasis has been placed on the creation and management of profiles with their associated interwoven multiple social graphs. To be successful, the Social Web must include far more than distributed profile and social graph management. We propose an open conceptual system in which there are multiple interoperable frameworks (see Figure 4) covering different levels of complexity and use-cases.
In effect we depict a "meta-framework" within which there currently appears:
- Identity Framework,
- Profile Framework,
- Social Media Framework.
- Privacy Framework,
- Activity Framework, and
- Emerging Frameworks (Decentralized Social Networking)
At this point, we will assume the frameworks will be able to work together seamlessly via a combination and harmonization of standards in order to enable a wide variety of innovation across social platforms and applications. An evolving combination of interoperable frameworks will move the Social Web towards this overall objective without constraining developers to a single monolithic architecture.
The Case for Open Social Web Standards
However, a critical problem in realizing this vision of Social Web is the fact that any "distributed" social networking platform will become yet another walled garden unless it is based on open and royalty-free standards. Via open standards, multiple social networking platforms ranging from large vendors to simple personal websites should show interoperability. However, these standards are currently scattered across various communities and are at times even incompatible, so that producing a single overview of what technologies and standards is a difficult if not impossible task, as is guaranteeing implementers can develop them without being hit by a patent lawsuit.
Identity
Identity is the connection between a profile, a set of attributes, and a user. Some credentials or "proof" of identity may be required from the user to access or create a profile, which is the step of authentication. In particular, these credentials may take many forms as a password, a signed digital certificate, or some other log-in credentials. Identity providers make claims (at least one) by providing attributes and may or may not authenticate the identity of a user. One of the most important parts of any profile claim is the identifier (a URI, including an e-mail address) for a user, although making a claim does not always reveal an identifier. An identity may be de-coupled from all but the most minimal of profiles (a simple identifier) and make claims without revealing any identifier, and may be anonymized as to not include a user's true identity (i.e. legal name or other identifying characteristics).
Using an identity selector, a user may want to select amongst multiple profiles (each of which could be a personae) and their attendant set of attributes. Each of these set of claims could be hosted by different providers. A user should be able to have multiple identities as well as multiple profiles. A user should be able to revoke an identity if it becomes compromised or for any other reason.
Problem: Usernames and Passwords are Insecure
Username and password combinations are currently the most prevalent identification technology on the Web. They are easy to understand, but suffer from a number of technical and economic drawbacks, including phishing threats. Web users are excessively requested to create password-backed accounts across various Web sites, leading to password-reuse with growing insecurity of each account. Passwords that are manually generated are often insecure, and automatically generated ones are difficult to remember. Widespread technical negligence in implementing password systems securely further undermine the security of password systems on the Web, and can partially attributed to lacking practical advice or standards on how to implement good password schemes. Approaches like Facebook Connect and Google FriendConnect at this point rely on user-name and password-based authentication for sharing personal social data.
Use-case: No more passwords (or only one)
Social Web user Alice wants to access her Social Web platforms Twitbook for her friends and BizLink for job contacts. She wants to keep the two identities separate, and access these platforms from multiple devices. Unfortunately, Alice uses so many social platforms and other web-sites that she currently just repeats the same password and username combination over and over again, which is insecure and may lead to identity theft. Luckily, using a distributed and secure identity framework, she can verify her identity by associating herself to a profile using some proof like self-signed certificates on her favorite devices like her laptop and mobile phone. Furthermore, as sometimes she may want to access her social platforms using an Internet cafe while traveling, so she finds a trusted third-party passphrase-based identity provider called SocialAggregator. It should be noted that if the SocialAggregator is developed on top of open standards, people would be able to implement their own version of such a service, allowing them to host it where they wished. As both Twitbook and Bizlink support her standardized identity authentication mechanism, whether it is used via her browser on her mobile phone and laptop or via a third-party identity provider, Alice no longer has to remember passwords when she uses any of social platforms on her trusted everyday devices, and has to use a passphrase only when not using a trusted device.
Identity Standards
This section will list a number of online identity providers which are currency deployed or in development on the Web. We will include both identity standards, as well as authentication and discovery standards that rely on a notion of digital identity.
Browser-based Password Management
Browsers now make it easier for users to create different passwords for each website by remembering them for the user, as is currently implemented by Mozilla. The Weave project of Mozilla aims to make password based authentication more integrated in the browser by allowing the browser to create and update passwords automatically across the Web. Instead of trapping the user within the browser, Mozilla's Sync plugin could allow the user to copy passwords, browser preferences and bookmarks from one browser and device to another in a secure manner by storing these preferences cryptographically encrypted on a server. The end user then only needs to remember this URL and the one password for its contents, to be able to retrieve it in any other device that knows how to decrypt and read the content. While currently browser based approaches do not track social connections, these could be addressed future work. However, even then it would not address the ability make and use connections across different social networking sites.
OAuth
OAuth (Open Authorization) OAUTH is an IETF standard (OAuth 2 is currently a draft IETF standard, and OAuth 1.0a is a standard) lets users share their private resources on a resource-hosting site with another third-party site without having to give the third-party their credentials for the site and so access to all their personal data on the social site. OAuth is a standard for granting data authorization to third parties, allowing people to grant access to private resources after authenticating themselves via their online identity. This standard essentially defeats the dangerous practice of many early social networking sites of accessing for the username and password of an e-mail account in order to populate a list of friends. Instead, OAuth allows an authorized handshake to happen between an resource-hosting site and a third-party, which then lets the third-party to redirect the user to authorize the transaction explicitly on the original site. If the transaction is explicitly authorized, then OAuth generates a duration-limited token for the third party that grants access to the resource-hosting site for specific resource. OAuth's tokens establish a unique ID and shared secret for the client making the request, the authorization request, and the access grant. To its huge advantage, this approach works securely over ordinary HTTP requests, as client generates a signature on every API call by encrypting a unique information using the token secret, and the token secrets never leave the sites. However, a session-fixation attack was discovered in the original specification that allowed a malicious party to save the authorization request and then convince a victim to authorize it, giving the malicious party access to the victim's resources, but this was fixed by having the third-party register with the resource-hosting site, as given in an update of OAuth. Recently there has also been a timing attack (using the difference of time in "bad" and correct digital signature verification to figure out tokens), but this has been addressed by having digital signature verification use a constant time.
While OAuth 1.0 is highly successful, the creation of the cryptographic work needed to produce correct signatures and the managing of various tokens was considered too difficult by many developers, so the IETF draft standard OAuth 2.0 simplifies the process by relying on TLS and breaks apart the various use-cases around getting tokens such that each is simpler. OAuth 2.0 requires that the resource-hosting site use HTTPS rather than HTTP and is therefore backwards incompatible with OAuth 1.0, i.e. OAuth 2.0 requires SSL. In OAuth 2.0 SSL is required to generate tokens, so signatures are no longer required for both token generation and API calls. Decreasing complexity, OAuth 2.0 has just a single security token and no signature is required. This has led to wider adoption across social networking sites like Twitter and Facebook.
OpenID
OpenID centralises the authentication step at an identity provider, so that a user can identify themselves with one site (an OpenID identity provider) and share their profile data with another site, the relying party. A user need only remember one globally unique identity, which in OpenID 1.0 was a URI. In the initial OpenID 1.0 specification OpenID1, the identity provider was discovered by following links of a HTML page accessed by the OpenID 1.0 URI, and OpenID 2.0 also allowed the use of the XRD format. One of the primary findings of the OpenID effort was that users were uanble to use URIs to identify themselves, and so approaches like Webfinger Webfinger even just an e-mail address, as enabled by the Webfinger were developed to allow e-mail addresses to be used as identifiers.
Once the OpenID provider is discovered, a shared secret is established in between the provider and the relying party, allowing them to share data. This is primarily done via an attribute exchange protocol OpenID-Attr, that allows the user to specify what personal data should be sent to the relying party. Note that this attribute exchange protocol is constrained by the information that can be placed as attribute-value pairs inside a URI, which is practically limited to a maximum of 2000 characters. OpenID is currently deployed by AOL, Facebook, the LiveJournal codebase, Microsoft, MySpace, Google (including Blogger), WordPress and Yahoo! (including Flickr). However, many larger sites expose themselves as OpenID identity providers but do not function as OpenID relying parties, i.e. do not allow users to log-in to their site using user credentials from another site.
As a server-side solution, OpenID and successor technologies have the advantage of only relying on server-side HTTP redirects, and so in general works independent of browsers. OpenID does not specify the credentials needed by the authentication mechanism, and very few OpenID providers provide authentication based on certificates or other kinds of credentials today, generally utilizing username-password authentication. As with all traditional username-password authentication processes, which represent the majority of all web-based authentication processes today, a possibility for phishing using redirection to "fake" identity providers exists. Thus far there have been no significant reported OpenID related incidents and secondary forms of authentication (i.e. certificates, challenge questions, biometrics, one time passwords, etc.) can be utilized to minimize the threat, as with traditional username/password authentication processes. Many OpenID providers including Google, Verisign, and Janrain offer various kinds of secondary authentication. Additionally, most major OpenID providers have implemented sophisticated backend policies and analytic tools to ensure the security of their users and services, in much the same way credit card issuers utilize analytics to detect and prevent unusual or fraudulent behavior. In this way, OpenID-based authentication can be more secure and reliable than traditional username/password authentication since OpenID identity providers have dedicated teams and capabilities well beyond what most independent website operators provide.
Some developers view the technology as complex, requiring up to 7 HTTPS connections in the workflow. OpenID supporters feel that past and future enhancements continue to drive ease of deployment and adoption of the technology. There are also a number of third party solutions and plug-ins that facilitate deployment. Additionally, given the similarities between the workflow of OpenID and the success of OAuth with developers, the OpenID Foundation is pursuing a new version of OpenID, known as OpenID-Connect, being built on top of OAuth. Due to the existence of OAuth 2.0, OpenID Connect is designed to be a thin layer on top of OAuth. One of the major things this brings to OAuth is true decentralization in terms of not needing to pre-register consumer keys and secrets with a given service. It will also standardize some basic profile attributes that are commonly available across providers. OpenID-Connect will offer an alternative to the OpenID 2.0 with Attribute Exchange and Artifact Binding approach also in development. As each of these initiatives progresses, the market will determine the appropriate applications and use cases for each approach.
WebID
WebID, originally foaf+ssl, uses TLS and client-side certificates for identification and authentication.To authenticate a user requesting an access-controlled resource over HTTPS, the "verifying agent" controlling the resource needs to request an X.509 certificate from the client. Inside this certificate, in addition to the public key there is a "Subject Alternative Name" field which contains a URI identifying the user (the "WebID"). Using standard TLS mutual-authentication, the user agent confirms they know the private key matching the public key in the certificate. A single HTTPS cacheable lookup on the WebID should retrieve a profile. If the semantics of the profile specifies that the user named by that URI is whoever knows the private key of the public-key sent in the X.509 certificate this will confirm that the user is indeed named by the WebID, allowing the authenticating agent to make an access control decision based on the position of the WebID in a web of trust.
The user does not need to remember any identifier or even password and the protocol uses exactly the same TLS stack as is used for global commercial transactions and is not vulnerable to phishing. As it is widely known that certificate authorities can be impersonated (although with a lot of work), instead of relying on widely known Certification Authorities, the client side certificates may be self signed. Such certificates can be generated in the browser in a one click operation. Disabling a certificate is as simple as removing the public keys from the personal profile.
However, there are a number of problems with this approach. First, certificate management and selection in browsers still has a lot of room for improvement on desktop browsers, and is a lot less widely supported on mobile devices, although there exists WebID implementations that are written in Javascript as to be completely de-coupled from the browser. Furthermore, it is often thought that by tying identity to a certificate in a browser, users are tied to the device on which their certificate was created. In fact a user profile can publish a number of keys for each browser, and certificates are cheap to create. Some people see that this can be enhanced by uses of protocol such as Nigori that requires only a single password to access "secrets" like certificates on a server, and so WebID could be integrated into a Firefox Sync-style identity management system.
InfoCard
Infocard is a user-centered identity technology based on three interrelated concepts: the card metaphor, active client software, and the OASIS IMI protocol for identity authentication INFOCARD. As such, it is a multi-layered integrated approach and infrastructure in of itself. Active client software integrated with the local browser acts as a local digital wallet for the user. Each card in this wallet supports a set of profile attributes called claims. Personal cards can be created directly by the user and hold self-asserted claims and values. Managed cards, on the other hand, are issued by identity provider websites that act as the authority for the claims supported by that card. The interactions between the active client and external services are defined by the IMI protocol OASIS IMI standard IMI.
Under IMI, an Infocard-compatible relying party website, usually via HTML extensions passively expresses its policy: the set of claim URIs that it requires, the card issuer it trusts, etc. When the user clicks on an HTML button, extensions with the browser trigger the invocation of the active client which displays a set of cards that support the claims required. If a managed card is selected by the user, the user authenticates and the client fetches a security token from the card issuer site using IMI protocols, and POSTs it to the relying website where it can be validated and the claim values extracted. Thus Infocards eliminates the need for per-site passwords, allows minimum disclosure, and provider stronger levels of assurance if the verification is done locally. Microsoft's Cardspace, is built into Vista and Windows 7 and open-source projects include Novell's Digital Me, OpenInfocard, and Eclipse Higgins.
However, its main disadvantage is the perceived complexity of interlocking standards and technology needed to support the architecture, so current work is on driving adoption via focus on applications in the government sector, as it does offer a higher level of assurance than browser-redirect-based identity technologies. Also, cards are too tied to a single device, so work is underway to incorporate Web services to at the least provide "card roaming" across browsers and devices as well as making Infocards more compatible with other technology stacks.
XAuth
XAuth allows multiple identity providers to update an XAuth provider (currently only xauth.org) so that third parties can authenticate a given user's identity [XAUTH]. When a user signs-on to an account on an XAuth-enabled identity provider, the identity provider notifies xauth.org. When a site is encountered that needs authentication, the site can use some simple embedded Javascript to ask xauth.org which identity providers the user is logged in on, and then uses the cookies stored locally on the browser to help the user authenticate with the third-party site. This approach easily allows logging out (as XAuth-enabled identity providers can tell xauth.org that the user's session has ended) and lets users enable or block identity providers. However, this approach has been heavily criticized. First, xauth.org is controlled by a singe entity (currently Meebo), and as a result is XAuth is heavily centralized. Although this could be fixed (i.e. letting xauth.org redirect to a local host, as suggested), it still reveals to third-parties the identity providers a user employs without their authentication, which can be enough information to identify them for malicious purposes. Google and Meebo deploy XAuth.
SAML
SAML (Security Assertion Markup Language) is an OASIS standard for the exchange of authentication and privacy between identity providers and service providers using an XML-based data format, tackling the single-sign on problem amongst many others. SAML allows one to make assertions that include the subject making the asssertion, the time of the assertion, any conditions to the assertion, and the resource to be accessed. An identity provider that can verify these assertions using a number of means by the identity provider, such as SSL, and make an authorization decision. SAML is often embedded in SOAP messages. In addition to the SAML protocol itself, SAML metadata supports the communication of identity provider and relying party information across multiple federations and so can be leveraged by federation providers and the majority of higher education institutions around the world as well as by other protocols such as InfoCard, WS-FED, and OpenID.
Examples of SAML deployment include universities, Google, SalesForce.com, Cisco, and WebEx. Unlike many other identity technologies, SAML is able to provide security solutions in banking and government web portal. In 2010 SAML was certified by the US Government for use by external identity provider at Identity Level of Assurance 1 through 3 for accessing specified government resources. SAML is, however, often viewed as being more complex than is necessary to support implementations requiring low levels of assurance. This has driven many developers to deploy simpler technologies like OpenID in low assurance scenarios.
Kantara Initiative's Trust Framework
The Kantara Initiative's emerging Trust Framework model enables interoperability and trust in identity authentication systems through certified credentials. This framework is composed of policy, privacy, and protocol deployment criteria to enable trust across all actors in a transaction, from end-users to identity providers and federation operators.
Kantara Initiative has developed an Identity Assurance Framework (IAF) as the criteria for interoperability amongst identity providers. The IAF when certified in combination with privacy and protocol profiles provides the Trust Framework. The Kantara Initiative IAF is technology agnostic and available to be profiled (specific to jurisdictions and verticals). Kantara Initiative also currently operates an Accreditation and Certification Program to accredit auditors to perform assessments and certify identity providers. The US Government has fostered some of the first deployments of this model. Kantara is contining to refine the model with other stakeholders across the globe.
Profiles
The Profile framework contains those applications which can be used to access attributes and the distributed access to such information. Users in this stage should also be able to find, discover, add and delete connections in order to update their profile. Using an identity selector, a user may want to select amongst multiple profiles (each of which could be a personae) and their attendant set of attributes. Each of these set of claims could be hosted by different providers. It should be possible for a user to control multiple profiles across multiple social networking sites, and synchronize the updates to their identity providers. In this manner, social applications should be able to share profile information, but on an as needed basis ("capability-based"), so that only the information needed in a particular context is revealed. Users can then be able to import their connections to new social applications and platforms so they do not have to find and confirm all contacts "from scratch" over and over again. Furthermore, a user should be able to export all their profile information and delete all profile information from an identity provider.
Problem: Can Not Describe Yourself
Today, when users create profiles they are often constrained in how they describe themselves and have to manually re-find their friends. Worse, some social networking sites constrain preferences, such as gender and religion preferences, that can be very sensitive. Also, many users may wish to have different names and profiles on different kinds of sites, and on some sites anonymity is a must. Furthermore, a near fatal problem with the uptake of new social networking sites and applications is that not only do users have to re-enter all their information to conform to what the new site wants, but then they have to re-locate all their friends on the new site or re-invite them.
Use-case: Keep Your Profile and Friends Across Networks
Alice has gotten bored of her social platforms, and wants to move to the new and increasingly popular augmented social reality gaming platform Fazer. However, she does not want to re-enter her old information and find her friends again. She authenticates herself using her browser-based ID and then accesses Fazer, and selects her "personal" identity as to not let her work colleagues about her game-playing identity. Since Fazer is a "real-world" augmented reality social game, she does not create a completely fictional profile (although she could) but instead opts to use an existing profile. In the account creation process, she is not required to complete all the profile attributes, but has them auto-completed, and she even creates a few new (custom) fields in a profile, and this new updated personal profile information is automatically synchronized between Twitbook and Fazer. She also explicitly agrees to share her geolocation with Fazer, which she has never done with Twitbook. Her various settings, such as avatars, presence, mood indicators, time-of-day and geolocation context are also automatically synchronized. Then using her set of social connections, her existing friends are automatically discovered on Fazer and she is given the option to add each of them or invite them if they are not on Fazer. A few months later she quickly gets tired of Fazer after having made some new friends in the process of playing various augmented reality games, and she decides to completely remove her profile from Fazer. However, as Fazer supports portability, Alice is able to download her own data to her profile manager at SocialAggregator and not lose touch with her friends, including downloading their numbers automatically to her mobile phone and backing her valuable data up locally.
Profile Standards
A number of standards exist for profile and relationship information on the Web. One distinction among them is what data format (plaintext, XML, RDFa) the profile is in and whether or not they are easily extensible. Even more importantly, there are differences in how, given a digital identity, any particular application can then try to discover and access the profile data and other capabilities that the digital identity may implement. While some profiles mention these discovery and use techniques explicitly and others do not, these common or standardized discovery techniques will be mentioned in context with each profile data format.
XRD
XRD (Extensible Resource Description), formerly YADIS and XRD-Simple (XRD-S), is a XML file format for discovering what capabilities a particular profile provider may have [XRD]. For example, is it also an OpenID identity provider or does it provide PortableContacts information? The XRD format provides this for arbitrary resources via the use of types and typed links describing URIs (URI templates) given in the XML format that can then be queried by a user-agent. The work around XRD has led to a number of innovations for locating XRD besides the W3C-style use of content negotiation, including the use of the IETF draft standards [.host-meta] and more generic .well-known WELL-KNOWN subdirectories from any URI. Furthermore, the XRD file (or other metadata format) can be discovered to via possibly a combination of markup directly in the document (such as a Link element in HTML), HTTP Link Headers in response codes, and then generic directories like .host-meta. The priority can be determined by the IETF LRDD (Link-based Resource Descriptor Discovery) informational document LRDD, which has now been subsumed by the host-meta draft specification. The IETF Web Linking specification specifies an IETF standard for Link Registries WEB-LINKING.
Overall, XRD seems useful and offers only modifications to XRDS (XRD Simple), and is similar to earlier W3C-inspired efforts using HTML and XLink like RDDL. Despite the fact that XRD was originally developed in 2004 by the OASIS XRI (Extensible Resource Identifier) Technical Committee as the resolution format for XRIs is seemingly rid of the use of XRIs, which are custom URI-like identifiers for people and organizations. Due to technical concerns and the use of at least previously patented technology for XRIs, this is a step forward. There is also movement in the specification, as it seems developers want a JSON specification of XRD, tentatively called JRD (although there is no RDF serialization of XRD). The general discovery management also needs to be integrated with content negotiation, but Web Linking and related specifications provide a much needed clarification of how to retrieve metadata about resources on the Web.
VCard
The IETF standard vCard [VCARD] is the oldest and most widespread format for personal address-book data, the kind of information typically found on a business card, such as name, address. Therefore, this format serves in general as the common core of most data-formats, except for FOAF (leading to a the definition of vCard 3.0 in RDF [VCARD-RDF]). However, vCard 3.0 in general lacked the ability to describe social relationships and was serialized in a ASCII text format, so the VCard 4.0 activity at IETF [VCARD4] has provided improved semantics for properties about people and organisations (such as the ability to express groups of users, e.g. "Wine Club members") and direct relationships between users ("friendship") and mechanisms to extend these terms. Syntactically, vCard can be expressed in its native format similar to VCard 3.0 and in a new XML format [VCARD4-XML] similar to the PortableContacts XML format. VCard import and export is supported by most mail programs like Thunderbird, Microsoft Exchange, and Apple Mail.
Based on vCard 3.0, profiles can also be embedded in HTML pages using the hCard microformat specification from the microformats process. One extension of hCard used by the microformat community is the XFN (XHTML Friends Microformat), which embeds its own idiosyncratic social contact relationships directly into HTML links using the rel attribute, and provides a set of finite attributes to define which kind of relationships exist between individuals (friend, co-worker, met). This kind of contact information based on hCard is currently deployed by sites such as Slideshare, dopplr, and Twitter to express social networks and can be converted to formats like RDF via GRDDL [GRDDL]. Overall, despite debates on alignment vCard 4.0 promises to be a stable core set of terms for the Social Web.
FOAF
The first project that used standards to describe distributed, decentralized social networks was the FOAF project (Friend-of-a-Friend) [FOAF]. FOAF however only attempts to address descriptive challenges, rather than the entire problem space. FOAF provides an extensible and open-ended approach to modeling information about people, groups, organizations and associated entities, and is designed to be used alongside other descriptive vocabularies. The FOAF project also established the practice of linking together RDF documents, prompting the Linked Data design note from Tim Berners-Lee that kick-started the Linked Open Data movement. Despite these innovations, FOAF itself does not provide for "social networking" functionality. It assumes other tools and techniques will be used alongside it, and does not itself specify authentication, syndication or update mechanisms. Today the vast majority of data expressed in FOAF is exported from large "social network" sites. However when FOAF began, most of these sites (except LiveJournal) did not exist, and the conceptual model for FOAF was the personal homepage.
FOAF profiles can be used to describe both attributes of one's user as well as one's social network the foaf:knows property). The discovery of FOAF information currently supports that information being simply accessed via RDFa or Linked Data over HTTP, and for private profile data authenticated using an identity provider before access. Current applications natively export FOAF profiles of their users, including hi5, status.net, Drupal7, and SMOB. Various exporters have been created by the community to enable FOAF export of major Websites (Twitter, Flickr, Facebook, and last.fm.
FOAF is well-suited to enable a decentralized Social Web due to its the use of URIs and Web-scale linking. For instance, a URI like http://example.org/alice#me can be used as Alice's identifier and Bob can state he knows Alive on his website by re-using this URI in either HTML or a RDF file. Like other RDF vocabularies, FOAF can be easily extended in a decentralized manner, as done by the SIOC vocabulary does as regards user-profiles and user-generated content, the Online Presence Ontology and the relationship vocabulary. However, while FOAF was created to demonstrate the decentralized nature of distributed vocabularies, it's historic divergence from vCard and PortableContacts makes it difficult to use with current Social Web applications, along with the general perceived complexity of RDF and lack of adequate RDF tooling. The FOAF project does not propose FOAF as the format that should be adopted for decentralized social networking; rather it is offered as a representational model that can find middle-ground between the semantics from diverse initiatives ranging from digital libraries and cultural heritage to those used in the Social Web. Recent changes to the FOAF specification have brought parts of it into closer alignment with the Portable Contacts work, and further such convergence is needed if FOAF is to be seen as a modern component of the technology landscape.
PortableContacts
An increasingly popular profile standard is PortableContacts, which is derived from vCard, and is serialized as XML or, more commonly, JSON. It contains a vast amount of profile attributes, such as the "relationshipStatus" property, that map easily to common profiles on the Web like the Facebook Profile [PORT]. More than a profile standard, the PortableContacts profile scheme is designed to give users a secure way to permit applications to access their contacts, depending on XRDS for discovery of PortableContact end-points and OAuth for delegated authorization. It provides a common access pattern and contact scheme as well as authentication and authorization requirements for access to private contact information. It has support from Google, Hi5, Plaxo and others, and is a subset of the contact schema used by OpenSocial, so every valid OpenSocial provider is also a PortableContacts profile provider.
Originally as VCard 3.0 did not have an XML format, PortableContacts was the first realistic contact schema with an XML format. It is also a proper super-set of vCard 3.0 [VCARD3] and is very close to mapping on to VCard 4.0, as co-ordination work in the DAP group shows. Ideally, PortableContacts and VCard 4.0 could converge or gain an easy-to-understand super-set or subset relationship with each other, as to reduce the friction between various profile data formats.
OpenSocial
OpenSocial is a collection of Javascript APIs, controlled by the OpenSocial Foundation, that allow Google Gadgets (a proprietary portable Javascript application) to access profile data, as well as other necessary tasks such as persistence and data exchange [OPENSOCIAL]. It allows developers to easily embed social data into their Gadgets. The profile data it uses is a superset of the PortableContacts and vCard 3.0 data formats. It does not require access to Google servers to run, but instead can run-off the open-source Shindig implementation and so positions itself as an "open" alternative to the Facebook Platform, and has been supported by a number of vendors, such as Google, MySpace, Yahoo!, IBM, and Ning.
There is a rather unfortunate mismatch between OpenSocial Gadgets and W3C Widgets from the Web App WG, given that both are primarily based on top of HTML and Javascript. Currently there is work being undertaken by Apache Wookie project to provide interoperability between Widgets and Gadgets, although ideally in the future the W3C Widgets would either be adopted or work more closely with major vendors in the iteration. Also, W3C Working Groups like WebApps and DAP (Device Access Policy) are also producing APIs that involve contact information and so should ideally maintain some baseline compatibility with OpenSocial.
Social Media
The Social Web is not only the connections between people, but the connections between people and arbitrary resources, including messages like blog posts, audio, photos, videos, and other resources. So social media is any resource that is used in a social relationship with a user. A user should also be capable of having connections to "non-Web" resources like locations and items. For example, a user may "like" a particular musical style or "review" a particular album. The Social Web should offer a way to avoid having identical user content stored in different social platforms. Users should be able to create, link to, and annotate social media with multiple social applications to aggregate their social media together in designated social platforms, as well as being given the option to save the data to local storage (e.g. in their browser). This is an extension of what is called by Berners-Lee "Linked Data" where links (connections) should be possible between arbitrary resources (anything identified with a URI), not just hypertext web-pages. One of the most important features that will support the generation of media on the Social Web is provenance. Provenance information should support the tracking of social media identifying when and how it came to be posted on a given social platforms and/or application on the Web. Any such provenance information should be capable of answering questions such as "When was it originally posted?", "Where does it originate from?", and "Who posted it?".
Problem: Fined for Consuming Social Media
Increasingly users and social platforms find themselves consuming social media, but not knowing if it is trustworthy or whether or not they can consume such social media without a monetary fine, i.e. whether their usage breaks the content's copyright! Not knowing this information can lead to disaster. People who are often downloading and re-using social media can now be fined for huge amounts of money, but many of them are unaware that the data was under copyright in the first place. So many users would like to have mechanisms to automatically determine whether a Web document or resource can be used, based on the original source of the content, the licensing information associated with the resource, and any usage restrictions on that content. Without any provenance (the information about who created the data and how has it changed over time), users can not trust social media. This applies to social applications themselves, whose reputation can be dependent on verifying sources, such as verifying the person or organization who created a news story in order to credit the original source in its site, which most real-world social applications would like to do automatically for thousands of sites a day. With the increase in fines related to social media consumption, users will want to be exceptionally well-informed about the social media they consume.
Use-case: Safely Drag-and-Drop Social Media Across Multiple Platforms
Alice enjoys taking photographs about penguins and would like to share them as widely as possible with her friends. Using an image processor on her laptop, she fine-tunes her photos and publishes these to her personal blog using a graphical drag-and-drop interface that lets her just drop the photo into her blog and automatically update social networking sites she uses. Since she controls not only her profile but her social media, she can easily attach a Creative Commons with attribution non-Commercial license and ask for a small fee of 10 cents for commercial use. As Alice explores social media, she even finds herself even paying for some social media she finds useful, and she uses a simple micropayment policy that allows her to consume up to five dollars in social media a week without having to worry about fines. She finds herself automatically paying tiny amounts of money for some social media to help support her friends and creators she likes and she finds herself collecting micropayments for her penguin photos, allowing her to turn her hobbies into a way to help sustain herself. Also, not only can she drag-and-drop social media safely, she can remove social media. When she discovers she has accidentally sent a message on Twitbook that spread a false rumor about an oil spill threatening penguins, she retracts it immediately so she does not cause a panic. Not only is the message removed from Twitbook, but it's removed from other sites as that aggregated it as well!
Social Media Standards
Content
SIOC - Semantically-Interlinked Online Communities - aims at developing a standard vocabulary for representing user-generated content on the Web, using Semantic Web technologies. The SIOC ontology (a W3C member submission, still evolving) consists in a core vocabulary (with classes such as sioc:UserAccount and sioc:Item) and several modules, in particular a Types one, providing classes for finer-grained content description (sioct:Wiki, sioct:WikiArticle, etc.). SIOC has strong ties with FOAF, so that it can be used to represent user-generated content of a person defined by the FOAF data format, and so that the content can be distributed over the Web, following the decentralized Social Web vision. In addition to the vocabulary, various tools have been designed, ranging from APIs to produce SIOC data, to systems identifying, crawling or consuming it. Also, SIOC is supported by Yahoo! SearchMonkey, and is used in Drupal7 as one of the core vocabularies used to expose machine-readable data about a given website's to the Open Web.
Tagging
Tagging is a powerful and massively deployed means of categorizing content on the Web, as deployed for bookmarks (Delicious, photos (Flickr), videos (YouTube), and blog posts. Unlike more complex categorization methods, the simplicity and ease of entering natural language keywords appeals to users. However, there are problems with interoperability. The two general approaches have been towards a common API for tagging via the currently inactive TagCommons effort and an approach using some sort of common data-model based on RDF. There is also the rel:tag microformat is used to link an item to its tag(s).
Most of the data-models use a tripartite model of tagging as the relationship between a User, a Resource and a Tag.
There has been a long history of tagging vocabularies, (TagOntology, SCOT, MOAT). The most recent effort in the area is the CommonTag vocabulary [CTAG] that solves ambiguity ('apple') and heterogeneity ('socialweb', 'social_web', 'socweb') by means of an additional link to a resource in order to represent the tag's meaning, such as URIs from the Linking Open Data project to represent that meaning. NiceTag [NICT] explicitly puts each tagging act inside a named graph that receives its own URI to make it easier to add context such as where it was performed and license information. All of these vocabularies are easily extensible, and CommonTag is supported by various players in the Social Web area, including Yahoo!.
Microformats
Microformats are a simple way to embed semantics in ordinary HTML by re-using established HTML attributes such as 'rel', 'class', and 'rev' with a set of string values given definition by a number of vocabularies [MICROF]. These vocabularies are meant to standardize common information (like contact information hcard) on the Social Web. For example, social sites often allow users to rate online content using some simple integer (like "1-5 stars"). The hReview microformat allow to represent this ratings in a structured way. Overall, the approach to using microformats has been massively successful in deployment, with over two billion web-pages marked up in microformats, about 5 percent of web-sites.
While easy-to-use, microformats specializes in a finite number of vocabularies, with these being done via a centralized and informal process based around Microformats.org. Alternative decentralized approaches like RDFa aim at the "long-tail" of vocabularies, which allow arbitrary RDF data to be put inside HTML. The microdata propoal of HTML5 also lets arbitrary attribute-value pairs to be put inside HTML. However, alternative approaches to microformats have not reached wide-scale deployment, although RDFa is now used in Drupal and all three kinds of semantic markup are consumed by Google Rich Snippets. 94 percent of Google Rich Snippets data indexed by Google Rich Snippets is based on microformats rather than RDFa or microdata. It should be noted that this statistic is somewhat misleading, as it does not compare Microformats against RDFa and Microdata; it compares microformats against the use of Google's own vocabulary in RDFa and Microformats. i.e. commonly used vocabularies such as FOAF, SIOC, vCard, iCalendar, Dublin Core are not included.
Open Graph Protocol
Facebook's Open Graph Protocol is a metadata vocabulary for describing documents and (indirectly) their topics, not that dissimilar from Dublin Core. It is typically serialized in RDFa in <meta> elements in HTML pages. An application of the the Open Graph Protocol is the Javascript enabled Facebook "Like" button. This allows developers to add a "Like" button to an item described in a webpage by adding only a small amount of simplified RDFa to the header of a web-site [OGP]. When users click the "Like" button, the fact that the user "likes" this item is added to the activity stream and Facebook profile of the user. The Facebook Like button has been enormously popular and is deployed across a number of high traffic websites such as IMDB, Rotten Tomatoes, CNN, and Microsoft, allowing it to be the largest metadata deployment of RDFa on the Web.
Although it is licensed under a OWF license, the Facebook Like button is itself hosted on facebook.com, and as a result Facebook have the ability to read any Facebook cookies a user has in their browser, regardless of whether or not the Facebook Like button is actually pressed. However, attempts to create an OpenLike [OLIKE] alternative to the "Like" button via OpenLike have yet to see much deployment.
Payswarm
The PaySwarm [PAYS] specification supports Web-based payments ranging from hundred-thousandths of a cent to pennies to thousands of dollars, and can be deployed for paying micropayments for social media . The technology is designed to be integrated directly into Web sites and builds on the OAuth protocol. A transaction has two participants - a buyer and a website. With PaySwarm, the buyer assigns a Payment Token to a website using the OAuth protocol. The Payment Token is much like a debit card with a pre-set spending limit. Once the buyer issues the Payment Token to the website, the website can use the Payment Token to charge the buyer for services rendered. The website is prevented from abuse of the Payment Token via spending limits, usage limits and an expiration date set by the buyer.
PaySwarm establishes a standard for Web Payments. While the W3C has had a micropayment activity in the past, but that attempt may have been too immature. With the wide-scale nature of user-contributed social media and the desire by many to make a living off of such media, making wide-spread digital content sales easily possible could allow - if the timing is right - a more decentralized approach to Web payments that would empower ordinary users to buy and sell over the Web with the mediators of their choosing. However, the security aspects of this proposal are incredibly dangerous, and require further review.
OExchange
OExchange [OEX] is a OWF-licensed specification for users sharing rich content over the Web using URIs between social sites. While this problem may seem trivial, one of the major issues facing the Social Web is the use of URI-shorteners, which then can redirect a user unwittingly towards a malicious site. Also, increasingly social media is shared by embedded "buttons" rather than URI linking. OExchange addresses this by defining a OExchange protocol that supports the offering of URIs to other services in a standardized way (with the possibility of identity authentication) and then allows sites to advertise using XRD their ability to receive data. This proposal is backed by Google but has not yet seen wide-scale deployment.
The Semantic Web
The Semantic Web is a set of languages for describing machine-readable data in an extensible manner and making links between data. The basic language of the Semantic Web is RDF (Resource Description Format), a language that lets data be connected between links and nodes, as in the hypertext Web [RDF]. As RDF can link any kind of data together and does not constrain the descriptions, it would be an ideal language for describing interactions on the Social Web. However, while it has had some use for profile data via the deployment of FOAF, the use of the Semantic Web to describe social media in general has not taken off. This is likely because of three factors. First, while groups like microformats centralize their formats, due to the decentralized nature of the Semantic Web, it is difficult if not impossible to discover vocabularies relevant for the Social Web, but this is a but a trivial concern and will be forgotten come maturity search engines' ability to process RDF data. Second, the RDF specification itself is rather difficult for developers to understand, and at times there are complaints of immature tooling. Lastly, unlike formats like Atom, RDF does not track provenance of data, such as the time it was created, by who, and the changes. Although Atom provides some simple provenance, RDF could be extended to support the more nuanced provenance needed for the Social Web. This topic is being explored by the W3C Provenance Incubator Group, who have been working on use-cases for the Social Web.
Privacy
In this report, we take a policy-centric view towards privacy. Policies are rules that can capture the permissions (access control), obligations (such as terms-of-service and licensing) and other data-handling settings that allow a user to control their interactions with social media and other users. By combining social media and a policy-centric view towards privacy, portable and distributed social graphs enhance privacy. Specifically, policies apply privacy settings to the profile and social media frameworks to consistently manage the user expectations of privacy and other obligations. A social platform that manages privacy on behalf of a user over multiple social applications and other platforms is a privacy provider. A privacy provider allows the user to select a set of policies, which can then be expressed in a machine-readable manner via policy languages. A policy language is a mechanism to declare a set of rules or statements that capture and express social obligations. These obligations may come from a legal (only allow Creative Commons work to be used), best practices (do not let children under a specified age befriend adults outside of their family), corporate or social perspective (don't mix "work" and "friend" profiles). Currently, existing individual policy languages have barely been put to use in understanding privacy and terms-of-service on social networking sites. However, a standardized policy language for privacy should provide an accountable, enforceable, flexible and trusted experience of the Social Web for users. A platform or application that implements the privacy settings of a user are privacy-aware and so a social platform should be able to automatically detect policy conflicts. Policy breaches should be detected so that some modicum of accountability can be instilled in the Social Web. This is a departure from the current approach of attempting to provide policy enforcement. Most attempts to provide enforcement on the Web (for example, traditional digital rights management for multimedia content) have ended in failure, and are not well accepted by the Web community.
Problem: Violation of Privacy
People are increasingly finding their social media spread across multiple platforms and accessed by all sorts of people, many of whom they did not originally intend. As social media is central to everything from job recruiting to personal relationships, the ability to grant and restrict access to one's personal data is becoming a critical component of many social applications. Furthermore, as the social media is shared and aggregated across various sites, this problem becomes even more critical as usually such access control is not "sticky", i.e. following the data wherever it goes. For an example of how this can go wrong, one could look at the infamous "drop your pen friend" case, where a young woman had her picture taken in what was an embarrassing photo, this photo was then posted without her knowledge to another site that gave anyone the ability to re-use the photo, so it ended up being used in a national advertising campaign in an embarrassing manner. Is it acceptable for someone to wake up one day and find a photo of them plastered across billboards. If she could have been tagged with her identity in the photo and notified of the photo, she would have avoided a vast violation of her privacy. Even more simply, the website could have made the terms of re-use and its totally open access policy more known to the friend who uploaded the photo, who could have then let the photo only be accessible to friends and not allowed re-use.
Use-case: Your Own Terms of Service
When Alice uploaded her penguin photos, she only wanted them exposed to certain groups of her friends, in particular, those who are also photographers and penguin enthusiasts. Luckily, due to the profile management which she does both locally on her browser and via SocialAggregator, she is able to transform her friends in groups of photographers and penguin enthusiasts via a mixture of manual work and automatic suggestion via their profiles, and she shares the photos with these users. However, since she is able to phrase the licensing (Creative Commons with attribution) with she discovers that Twitbook has extremely draconian terms of service that mean that her photo, if uploaded to Twitbook, then becomes property of Twitbook. Thanks to the fact that Twitbook's policy is also phrased using a common policy language, her social platform discovers the policy conflict and warns her not to upload her pictures to Twitbook. Furthermore, after uploading them to her personal blog and propagating them via Bizlink (which has a more sensible terms of service Alice agrees with), SocialAggregator informs her that a large private company CSO is using her photos without her permission in an advertising campaign, which can detected via its accountability mechanism that checks on usages of her data and her privacy policy. Alice is informed, and she demands her photos be removed. As the company refuses, she orders an automatic take-down of the penguin photo and blocks any further social communication with the CSO company. Later in the day, a friend uploads a photo of her to Twitbook at a fancy-dress party that she wants only her friends to know about, and SocialAggregator warns her again, and automatically sends a message to her friend and Twitbook to restrict views of that photo from her business colleagues.
Privacy and Privacy Standards
New technologies, the ubiquity of the internet, and the amount of time people spend interacting with the digital world are both advancing our freedoms, whilst at the same time are enabling novel invasions of privacy. This concept of how far-reaching services and technologies are affecting privacy in the modern world, has been pushed into the mainstream in spring 2010 by Facebook. A recent Wired article entitled Facebook’s Gone Rogue It’s Time for an Open Alternative highlights the frustration regarding how a once exclusive and private social networking tool, developed for Harvard University has now become one of the least private high volume sites on the Web. The following links present some of the privacy issues that have highlighted the need for a decentralized privacy aware social networking platform:
- News articles have highlighted how confusing Facebook’s privacy settings are and convoluted their privacy policy actually is. This is illustrated by the Terms of Service Tracker which shows a change history of popular sites on the Web. The following visualization shows how Facebook’s privacy policy has changed over time. This change in policy, is the main reason why there has been a sudden desire for the development of a decentralized social network, removing the need for a central service that accumulates personal information.
- Facebook’s Opengraph The following blog post highlights the privacy implications of Facebook’s Open Graph Protocol. Illustrated by the web-service zesty.ca
In order for any decentralized social networking service to be a success, the service's privacy policy with respect to the information it holds regarding its users must appeal to the privacy aware masses. A report undertaken by Joseph Bonneau, Sören Preibusch from the University of Cambridge entitled The Privacy Jungle: On the Market for Data Protection in Social Networks details the findings of a study of privacy policies for popular social networking sites, and presents best practices when it comes to creation of privacy policies, such as communication of "privacy practices in a non-textual format to help users make more informed privacy choices" and "requiring sites to provide clear, Web-integrated interfaces for users to see exactly what personal data of theirs is held, and exactly which parties have access to it", in order to increase privacy awareness.
The SWXG has looked a number of technologies / initiatives that may provide insight into methods of developing machine-readable policy languages. Such machine-readable policies would help empower users to set policies on their data, stating how they intend to have their data used and shared on the Social Web. Such machine-readable policies should be tide up to users' online identities. Below are some of the initiatives that could help inform the design of user centric privacy and data sharing policies.
P3P
Expressing privacy via machine-readable languages began with the W3C P3P (Platform for Privacy Preferences) Recommendation, which allows Web site operators to express their data collection, use, sharing, and retention practices in a machine-readable format. While at first glance this may seem well-suited to phrasing terms of service, P3P has not been widely adopted. While Internet Explorer has exposed a P3P-enabled feature since version 6, it only allows cooking-blocking. The Firefox/Mozilla browser discontinued its built-in support for P3P; those wishing to use P3P can use plug-ins like PrivacyBird developed by researchers. The primary criticism that it suffers from is that it is too complex and offers no legally or technical bindings for privacy agreements, and this has led P3P to fail to have significant deployment.
POWDER
The W3C POWDER (Protocol for Web Description Resources) language provides a mechanism for describing groups of resources by essentially providing a "glob" operator over URIs and linking these groups of URIs to a group of common XML statements regarding topics like authentication and RDF statements [POWDER]. While more generic than P3P, it was aimed at the same use-cases such as privacy descriptions for child protection. While interesting for allowing RDF to describe groups of URIs rather than single URIs, it is seen as complex and has failed to gain deployment for the same reasons as P3P.
AIR
Despite the lack of deployment of P3P, research still continues on languages to express policies for privacy and data-handling. AIR(AMORD in RDF) is a policy language that is represented in Turtle and features a basic proof-level, as well as special-purpose classes and properties that can be used to define policies in a machine-readable manner. However, AIR is limited by its ability to only handle RDF data and features no defined mapping to RIF. Although AIR is a potentially-useful research project, it has no deployment outside a research context.
XACML
XACML (eXtensible Access Control Markup Language) is a OASIS specification for a declarative policy language for access control [XACML]. XACML allows for rules, specifically access control rules, to be expressed in a machine-readable manner. Attempts have been made to extend the XACML access control language to support privacy on the Social Web use cases by the PrimeLife Project. However, XACML only operates over XML-based data and is viewed as too heavy-weight, in addition to still succumbing to the enforcement and complexity problems that caused P3P to not take-off. Unlike other standardized rule languages, XACML has some limited use in industry, including an Apache module, as was primarily backed by SUN Microsystems, now Oracle.
Rule Interchange Format
The W3C RIF (Rule Interchange Format) Recommendation is a format to exchange rules between rule engines that operates over both XML and RDF data [RIF]. Due to its extension mechanisms, it would been an ideal language to investigate machine-readable first-order logic rules, and existing languages like AIR should attempt to map to it. However, it suffers from the same problems as P3P of being overly-complex and not having any legal binding, and despite being a W3C Recommendation with support from major vendors like IBM and Oracle, has little deployment as of yet.
Device APIs and Policy Working Group
Although the Device APIs and Policy Working Group's (DAP WG) primary mission is create client-side APIs that enable the development of Web Applications that interact with one's devices and their applications, such as Calendars, Contacts, Cameras, and the like, the Working Group has also been chartered to produce a framework for the expression of privacy policies that govern access to these APIs. At its last workshop in 2010, the primary output has been Privacy Ruleset [RULESET].
The Privacy Ruleset describes "bundles" of privacy preferences in a way that should be understandable to the typical user and developer. The Privacy Ruleset allows users to describe their privacy preferences over three categories: Sharing, Secondary Use, and Retention. These have a number of different possible values. An example of the least permissive privacy preference "bundle" is called "sharing=internal". This least permissive ruleset bundle states that the user wants her data shared only internally by the data collector and organizations that help the data collector deliver the service, only used for contextual purposes (which includes contextual advertising), and not retained beyond the baseline period. An example of the most permissive ruleset is one that allows sharing to everyone (included 'unrelated-companies'), secondary use for 'marketing or profiling' as well as just contextual and contextual use, and indefinite retention. For simplicity, the rulesets only apply to identified data -- information that can reasonably be tied to an individual. While considerably simpler than P3P and privacy ruleset is based on first-order logic, allowing for the necessary reasoning to be performed. Furthermore, as with P3P there is still no model to legally bind the enforcement of these policies.
Mozilla Privacy Icons
Mozilla Privacy Icons takes a simple icon-based approach inspired Creative Commons [PRIVICON]. Instead of specifying every possible type of privacy and data-handling scenario, they specify only a few common privacy scenarios that users can encounter. The icons are designed to be easy-to-use and understand by ordinary end-users. As there is a no incentive for sites that violate user privacy to label themselves as such, it would be up to the browser to automatically label such sites. Also, users do not ordinarily notice an icon by its absence but only by its presence, the browser would automatically use the icon to notify users they have entered a site where their privacy could be violated.
This approach manages to defeat the complexity barrier of rule-based approaches, although it does not address every possible scenario. While it does not address legally-binding enforcement, by alerting end-users to possible privacy violations, informed user choice about privacy risks can serve as a de-facto way to get sites to respect privacy. However, currently Mozilla Privacy Icons are available as an plug-in to Firefox, so the pool of users that are aware of this work and deploy it is still quite limited.
ODRL
The Open Digital Rights Language (ODRL) Initiative is an international effort aimed at developing and promoting an open standard for policy expressions in a machine readable format, currently in its second version of the ODRL language, namely ODRL 2.0 [ODRL2]. The motivation for this revision of the ODRL language was to try and abstract away from expressing rights and towards a general policy language. ODRL 2.0 is currently expressed in XML, with a RDF version in the works. ODRL is meant to express access control (what content is available after authentication), permission control (how an agent should re-use such data), and privacy control (obligations of personal data). In order to illustrate that ODRL 2.0 can be used as a general policy language the initiative has been looking at modeling some use cases based around social networking. This work is said to ensure that the ODRL initiative capture all of the requirements needed for describing policies for the Social Web. Furthermore, the ODRL initiative has also looked at the use-case developed by the Privacy Ruleset work undertaken on the W3C DAP WG and have subsequently expressed the use cases in the ODRL language, ODRL are working with OneSocialWeb to help development a solution for policy expression on the Social Web. This collaboration with OneSocialWeb aims to output XMPP bindings for ODRL. Furthermore the ODRL initiative are tracking the work of the PLUS Coalition (for images) and the work being undertaken at the ACAP (Automated Content Access Protocol) to ensure that ODRL 2.0 is a general web-based policy language.
Activity
The most distinguishing feature of the Social Web over the previous hypertext Web is the increasing focus on sharing information in real-time. As opposed to pulling information on an as-needed basis, users desire to have information that may be of interest pushed to them immediately. The social interactions of user and resources, including other users, are the activities of the user. Each activity, such as changing status, making new connections, creating a blog post, and attending events can be considered an update in an activity. The total of all activities of a user is the stream of the user. Social media, like a conventional blog post, can have its own stream of activities such as comments, microblogs, tags, and ratings. In a privacy-aware manner the various streams can be shared with social connections, and so constantly bring together shared items of interest and status updates to a user. Social application can "assemble" context in real-time by combining information from the profile, connections, and policies the user has stipulated in order to bring the relevant information to the user. Furthermore, the content of these streams can have access control policies set on them, and they can also be signed by the authoring user allowing for the information to verified upon receipt. Through this shift we can see the Web is evolving from a graph of linked hypertext web-pages to a dynamic universal stream of social information that every user contributes to and actively sifts through using their own trusted connections.
Problem: Can not Integrate Conversations
Currently, users are being forced to not only "silo" their profile information and social media, but also all the time-sensitive updating of this information. As more and more updates - ranging from location changes to blog comments to "liking" social media - are circulated across multiple social platforms information is being fragmented over the Web. There is no standard way to update and integrate back further comments attached to an update to their original source. This can lead to dangerous privacy violations, as some conversations may want to switch to more private modes, like e-mail and even public-key encryption, and there is no easy way to signal to other users that the conversation should "move" to a more or less private medium or what groups or people should be allowed to see a message. To make things even worse, users want updates about their friends and social media increasingly in real-time, which is difficult using the "pull" architecture of the Web. This leads possible crucial information not to reach its intended audience in time.
Use-Case: Real-time Collaboration
As Alice starts using more social applications, she increasingly finds her behavior on the Web moving from searching for new relevant social media to being in near-real time updated about the activities of her friends and the social media they have created or discovered. These streams of updates are not just new information, but chances to help collaborate with others. She also finds herself using e-mail less and less, as she can now use her social Web-enabled platform to directly communicate in both asynchronous messaging and near real-time video and audio-enhanced chat with her friends, and authoring new social media collectively with them. One of the major drawbacks of e-mail was that it is mostly insecure (i.e. delivered in plaintext) and unauthenticated (and so easy to send spam with faked e-mail addresses). Thanks to the identity technology of the Social Web, she is now able to verify whether or not she is communicating with another user or not, and thanks to the identity and profile management in her browser, she is even by default uses public key encryption to encrypt her messages and social media she sends to her friends if needed. So she can be updated of the activities of all her friends constantly and share her work with them, all while keeping her communications and identity secure in a way that was unimaginable to her earlier.
Activity Standards
We will note the ability of social network messaging (ranging from blog comments to chat) to be implemented, both asynchronous and near real-time, to be co-ordinated via Atom, Pubsubhubbub, and XMPP, giving special attention to activity stream updates.
In contrast to fractured landscape of portable profiles, the standards used to describe activities are at this point new and rapidly being deployed. The core architecture presumes an ability to send content (status updates, messages, and other content) in as near to real-time as possible. This is currently accomplished through two distinct architectures. The first based on XMPP, where the XMPP messaging framework natively provides an XML "envelope" for data to be sent in real-time with updates (as demonstrated by Vodafone's OneSocialWeb). The second architecture is based on HTTP, but overriding its traditional "pull" architecture with a "push" architecture based on Pubsubhubbub (which could sensibly be abbreviated as PUSH). This architecture allows Atom clients to "sign" up to a server that they poll to receive notifications of content changing. While the underlying architecture may differ, the core functionality remains the same, the creation and updating activity streams.
XMPP
XMPP (Extensible Messaging and Presence Protocol) is an IETF RFC for the near real-time transfer of XML data [XMPP][XMPP2]. XMPP was developed by the Jabber community, and in its simplest form can be regarded as a protocol for passing XML fragments between machines, but features its own methodology for identity authentication and extensibility, with many of its extensions being hosted by the XMPP Foundation. The XMPP technology stack is both mature and widely deployed by Google GTalk and open-source projects like Pidgin to provide chat.
One of the main concerns the Social Web is to provide status updates and messages in near-real time, XMPP is a natural fit for federated social networks. One advantage that XMPP that XMPP provides is for devices to connect to the federated social network without the need to bypass standard firewall setups. However, it does so insofar as XMPP is not directly built on top of HTTP and so provides a whole parallel level of complexity. A number of federated Social Web solutions like OneSocialWeb have been built on XMPP.
Atom and Pubsubhub
The main problem with building a specification on top of HTTP is the "pull" architecture of the Web. This "pull" architecture is not suited to status updates, messaging, and other kinds of activity streams in general. However, the draft Pubsubhubbub (PUSH) specification provides a "push" architecture for the HTTP-based Web that can provide activity stream updates in near real-time, built on top of a simple distributed publish-and-subscribe architecture. In particular, PUSH allows publishers to publish data via the XML-based IETF RFC Atom as usual, but contain a pointer to a PUSH-aware hub [ATOM]. When subscribers subscribe to an Atom feed, they can discover the hub and subscribe to the feed via the hub as well. Then when the feed has been updated, subscribers are updated in near real-time by running a PUSH-aware server that the hub will update.
Overall, this approach has the advantage of building on top of widely deployed and mature software that is part of the HTTP web, the already largely deployed Atom infrastructure. Also, PUSH allows the full content to be delivered (unlike earlier "push" alternatives such as RSSCloud). While XMPP Pubsub gives updates in closer to real time via persistent connections (i.e. like chat) [PUBSUBXMPP], for scenarios where the updates are not needed in as close to real-time and persistent connections may be more unreasonable, PUSH and Atom are suitable. As such, this approach has been taken up by a number of federated Social Web architectures, in particular status.net.
ActivityStreams
ActivityStreams is an Atom serialization for activity streams such as status updates in popular social networking sites. While Atom is easy to work with, it doesn't capture the semantics of the original activity in a cross-platform way. Social applications dependent on cross-site Atom aggregation, becomes increasingly costly to support. Each new social networking site, as the semantics of each new site has to be added manually (Facebook lets users "like" items, Twitter sends "tweets" to friends), would require a change to the ActivityStreams specification, which in turn would result in developer resource across the board. ActivityStreams standardizes the way of embedding status update semantics by dividing the activity into an action that was performed (verb) by an actor on another person, place, or thing (the object). An additional target (like a photo album) could be involved. Each activity is by virtue of being in a stream given an explicit date in time, so the stream itself is a feed of activities for a person or social media object.
ActivityStreams features an experimental API and JSON serialization, and it does not currently have a RDF serialization. Although ActivityStreams has a "subject-verb-object" in a similar fashion to RDF, it uses Atom rather than RDF because the Atom tool-set is more mature and developers are more aware of Atom than RDF. Currently ActivityStreams maintains a [1] schema of activities. These activities could become open and exentensible if any URI were used instead of a string. ActivityStreams has widespread deployment, including Facebook, MySpace, Google Buzz, Opera, and BBC.
Salmon Protocol
As content starts moving around outside of its original social platform: How would comments, ratings, and annotations that happen on another social platform besides the original somehow be sent back to the original post? The draft Salmon Protocol addresses this problem of "unifying the conversations" [SALM]. It assumes there will be spam, but uses digital signatures to assure content comes from a legitimate identity, so that any content whose creator's identity is not authenticated simply disappears. Salmon Protocol works by adding a new link relation to Atom-serialized content that identifiers the original Salmon-enabled content provider. After that content has be annotated "downstream", a Salmon-enabled social platform could then send the annotations back to the original content provider back "upstream." The annotations are signed via the draft Magic Signatures specification and OAuth can provide additional verification of the identity of the signer [MAGIC]. Then, the "upstream" content provider can re-aggregate the content's "conversation."
While Salmon, or something similar in nature, is definitely needed by a federated Social Web, currently Salmon works only on public annotations and content, and so should be expanded to deal with various levels of privacy. Salmon completely forbids anonymous and untraceable messages. While useful for preventing abuse, this approach may also prevent legitimate use of content by, for example, activists living under oppressive governments or others with a legitimate desire to protect their privacy. Therefore, one interesting extension could be some kind of "spammer" identification that propagates identified spammers but allows anonymous users to register at authorized anonymous identity providers or "prove" themselves. There are also debates around the use of Magic Signatures's encoding rather than the use of the RSAPublicKey ASN.1 structure specified by RFC 3447 and used by OpenSSL. The secure retrieval of XRD requires SSL or can be performed by implementing the W3C XML Digital Signatures Recommendation, but in a decentralized environment this interaction model of trusted roots might not be all that is necessary.
OStatus
The draft OStatus specification is a a "meta-specification" for sending status updates to people in a federated Social Web [OSTAT]. OStatus weaves together a number of previously mentioned specifications (PubSubHubbub, ActivityStreams, Salmon, Portable Contacts, and Webfinger) in a straightforward way. It does this by adding two "link" extensions to ActivityStreams, one that stores a URI for a user when a user is mentioned or directed at an activity, and the other that tracks the URI of a distributed "conversation" described in Salmon. Then the XRD and Portable Contacts methodologies can be used to retrieve data from the user given a URI, and the Salmon Protocol and re-aggregate any activities, using PubSubHubbub to deliver these back in near real time for the user.
Overall, this specification provides a service to the Social Web community by providing an HTTP-based meta-architecture that defines the baseline functionality needed in a distributed social application based on activities. So, people who desire to create their own software for federated social networking can then follow the instructions here to begin becoming interoperable with other networks. However, this specification begins to explore the requirements and functionality needed for federated social networks (i.e. it does not take into account distributed widgets like OpenSocial and private communication). Also, a competing architecture could easily be specified using an XMPP base.
Emerging Frameworks
Of utmost importance is the fact that any framework should lead to a core set of functionality that allows developers to easily interrelate their existing technologies while encouraging new uses and hence leading innovation rather than holding it back by premature optimization. The framework we are also proposing is modular, so that new emerging social applications and frameworks can be added. For example, it is possible to envisage an e-Commerce framework encompassing an assortment of billing, product tracking, fulfillment protocols which are already in use in e-commerce applications and that can build on top of the social media and policy frameworks. Shockingly enough, users are already sharing this kind of information through platforms such as Blippy. Another possible framework is an analytics framework that enables users to benefit from active social application participation by providing the dynamic analysis of the users behavior's and feeding this back into the user's profile via automatically creating and updating a user's profile information based on an analysis of their activity. This could enable the formation of communities-of-interest as the profiles of individuals reach a threshold of similarity if the privacy settings of a person's profile allow such connections to be made. Lastly, one could imagine a trust framework that is highly dependent on identity, context, and the provenance of social media. The level of trust necessary between a merchant and a user, for the purpose of fulfilling a transaction is a different scale than that of sharing a blog post and trust will likely vary wildly across individuals and contexts, and so not easily be reducible to overly-simplistic metrics.
Accessibility Concerns
Accessibility concerns cuts across all aspects of the Social Web. With regards to identity, having the user be able to specify their accessibility requirements as part of identification and authentication with an identity provider is of utmost concern. In the world of social media, authoring tools should support accessibility, e.g., prompting users for alt text for uploaded formats, and interchange formats need to support accessibility, e.g., including text alternatives when photos shared. This is not currently uniformly addressed by current Social Web networking sites. For example, Facebook suffers from many standard dynamic HTML accessibility issues: the "Hide" pop-up link not keyboard accessible, lack of landmarks, there is considerable confusion over what keyboard access in widgets should be, lack of pop-up text on image links, and issues with simultaneous updates. Accessibility specific issues of Social Web user interfaces are in general addressed by ARIA in HTML, so the W3C should encourage further use of ARIA by existing Social networking sites.
Many social sites provide APIs in addition to the primary Web interface. This leads to a possibility to create alternate accessible interfaces, but depends on the API exposing all of the features. Many users and communities would work on creating these if the APIs produced the necessary for information. For example, due to invalid markup and a lack of consistent use of "alt" text and other accessibility problems encountered with Twitter's default web-based interface, persons with a disability usually use Twitter via a third-party social application such as AccessibleTwitter (a web based interface which uses ARIA, platform agnostic), Echofon(iPhone), or Qwitter (Windows). Note that this is just an incomplete sampling that does not imply endorsement. The W3C should encourage sites to release full-fledged APIs that let communities create their own alternate accessible interface to the Social Web.
Decentralized Social Networking Projects
2010 has seen a lot of work undertaken towards making federated social networking real. To describe in more detail, in order to overcome the need for users to hand over their data to a third-party social networking site, a number of concrete coding projects have started to build federated Social Web platforms, which allow users to run their own social web provider, allowing users to keep their data where they want - even on their own server - while still interacting with the rest of the Social Web. These projects met at the Federated Social Web Summit 2010. One of the results of the summit was the definition of the test-case named Social Web Acid Test 0 (SWAT0). Below is a non-exhaustive list of projects currently in development for a federated Social Web (A more complete list by the GNUSocial Project) participating in SWAT0 . SWAT0 details a use case where a user running a "node" of their own social network wishes to tag a photo of a friend running a node of another social networking codebase.
Status.net
Status.net is a free software microblogging platform to help people in a community, company or group to exchange short (140 characters, by default) messages over the Web. Users can choose which people to "follow" and receive only their friends' or colleagues' status messages. Status.net used to be based on the Open Micro-blogging specification but is now based on OStatus, and runs on PHP and MySQL. It is currently deployed by identi.ca.
GNU Social
GNU Social is a project championed by the Free Software Foundation (FSF). A decision by the GNU Social steering committee has been made to built on top of the OStatus protocol and the Status.net codebase. It's main goal is to able to be ran from a minimal hosting configuration. As it is based on Status.Net, it is ran from MySQL and PHP.
OneSocialWeb
Vodafone's OneSocialWeb open source decentralized federated social web platform built on XMPP, which OneSocialWeb has extended using a number of draft specifications, for ActivityStreams over XMPP, vCard4 over XMPP, Social Relationships, and Personal Eventing Protocol (to allow events to be stored offline in an "inbox"). OneSocialWeb has a Java-based plug-in for servers, Web-clients, and an Android Application.
Higgin’s Project
Eclipse's Higgin’s Project is one of the earliest open-source efforts to create a decentralized social network. It is based on the Personal Data Store model and its own RDF/OWL Persona Data Model (details). It also includes support for active clients and OASIS IMI infocards to deal with issues related to identity provisioning, multiple identities, multiple personae, and multiple levels of assurance.
Diaspora
The Diaspora project to "leave Facebook" was greeted with much fanfare by the New York Times in May, as it was founded by four students students from New York University have managed to collect 200,000 US dollars using online donations. Their main focus is security, with all communications encrypted and signed. Their alpha code in Ruby has been released.
Diso Project
The Diso project is an umbrella-group to build the Social Web into open-source software, focussing first on enabling OpenID, OAuth, and Microformats for WordPress and Movable Type in PHP.
SMOB
Semantic MicroBlogging (SMOB) is a framework for distributed microblogging based on Semantic Web technologies. Each "hub" of SMOB exposes its data in RDFa and as a SPARQL end-point. Updates are then down using SPARQL Update, so that interaction consists of exchanging RDF data such as FOAF and SIOC, but augmented, with a special focus on tags vocabularies like CommonTag and MOAT, making microblogging part of the Linked Open Data effort.
Appleseed
Appleseed is another decentralized social networking project who participated in the Federated Social Web Submit in 2010. Appleseed claim to be the first fully decentralized social networking software, emphasizes privacy, the ability to move around without losing your friends, and advocates open standards.
OpenLink Data Spaces
OpenLink Data Spaces (ODS) is an open source project on the OpenLink Virtuoso Server with several pre-built subsidiary user-focused applications. In addition to OpenID and WebID, It supports Semantic Web technologies, Atom variants, oData, and gData (communicating via "semantic pingback"). Its focus is on data-space virtualization and ACLs for Web storage.
Project Nori
Project Nori is an example of a Personal Data Store (PDS) (aka Personal Data Locker), a fourth party service that works on user's behalf from the as put forward by the VRM (Vendor Relationship Management) community. The intent is to centralize control for the user, and to provide them with a central dashboard of all for decentralized and federated data. Project Nori is an XDI-based implementation of a Personal Data store and participates in the Federated Social Web effort, having a working OStatus implementation.
Business Considerations
The purpose of a distributed and decentralized Social Web is not to propose or promote solutions which reduce or erode existing and viable businesses. It seeks to explore the introduction of an entirely new Social Web architecture that new and existing businesses can take advantage of in the future. By combining existing business models that let existing large social networking sites leverage their huge amounts data with a lower transaction cost, new businesses can be built downstream from these data silos and whole new models emerge.
Size of Social Networking in 2010
How large is the Social Web? This brings up immediately the question of metrics: What are the appropriate measures of the size of existing the Social Web and how could a move to a decentralized and federated approach increase its size? While a number of metrics were explored, the metric which matters most for businesses is money. Observers have speculated that Facebook, the undisputed leader in most markets, received between $600 and $900 million in advertising sales in 2009, so that Facebook declared that it had reached break even and was running profitably. Tencent, the operator of the Chinese social platform QQ, announced in May 2010 that it generated $1.8B in revenues in 2009, and judging from the rate of increase in the past year, Tencent can be expected to generate double the 2009 revenues in 2010. According to an independent analysis in March 2010 , Facebook is on track to exceed $1B in 2010 InsideFacebook blog. There are also steadily increasing revenues across the entire ecosystem:
- Mobile network operators up-sell smartphones and a greater number of higher margin data plans to people who are avid users of social networks
- Social platform application developers generate revenues and a wide variety of publishers which want to be available on social networks
- Social games, a phenomenon which was already wildly popular in China, Japan and Korea, expanded rapidly on MySpace and Facebook in 2009-2010, creating high valuations and recurring revenues from users who acquire digital goods and services within games.
Current business models for social networks
Currently, revenues can be generated from the Social Web by:
- users paying from their own pockets
- Corporations purchasing advertising which they can convert into future business revenues and
- Commissions on transactions (a case in which the end user paying for a digital or physical good and the vendor selling that good provide a small percentage of the total cost to the provider of social applications where the transaction happens, like a purchase on eBay.
Some of the largest social networks today are only using advertising to generate revenues. Others only have user premium service fees. Some companies are combining two or three business models. For example, mobile social networks such as MeetMoi, Flirtomatic, FunkySexyCool are reliant on both. Facebook continues to offer its service at no cost to end users and generating its revenues entirely on advertising, although transactions in the platform are enabled and expected to generate increasing revenues in the future. In Japan, Gree, Mixi and Mobagetown provide their social networking for free and generate revenues from sales of advertisement to brands, sale of premium options to members of the community (e.g., extra storage for photos, a larger virtual 'room' for their avatar, a new template for a blog with professional graphics), as well as the sale of digital goods ( games, wallpaper, accessories for avatars). We expect the trend towards combining current business models to continue, leading to the desire for secure Web-centric identity and Web payments.
New business models
In the future, revenues can be generated from the Social Web by:
- New kinds social applications that enable new kinds of collaboration to take place that take advantage of social data-mash-ups from multiple services.
- Software sales, maintenance or tuning of new identity-aware and privacy-aware Social Web applications that offer strong guarantees to users.
- A more flexible and open market of low-cost social media paid for by Web payments
- Increased liquidity of social data with strong assurances of a lack of legal liability.
- Integrating social features into all aspects of existing applications and computing in general.
The Social Web will affect every area of activity, and each area has very specialized requirements and sources of revenue. For example, an identity provide for Social Web might also generate revenues by way of providing a highly robust authentication mechanism that would be considered a value add due to its prevention of identity theft or the enabling of Web-based e-commerce based on micropayments. Such identity and privacy providers will be able to generate revenues by way of users choosing and paying a one time (fixed cost), a monthly subscription cost (flat recurring), a pay as you use (variable cost) for one or more of the above applications, or even agreed up advertising. An open Social Web would cater for entirely new innovations, such as a provider or even user making revenues by selling (as controlled by the user), bundles of privacy-protected data about the user that it puts up for auction on personal data exchanges (similar to stock markets) wherein other providers can bid and acquire these data in order to provide new and valuable services back to the user. Notice in particular that government agencies that interact with the public require much more clearly defined and formalized rules over privacy and identity, while e-commerce will require the ability to describe rights and identity to a high extent. Research will need better social tools for relating people, data-sets, and results. Each of these areas will have very different value propositions and so different places to monetize the service.
Conclusions: A Strategy for the Social Web
The Social Web architecture detailed in this report strives to keep the Web universal by allowing the various components of the Social Web to each be treated as a "first-class" citizen of Web architecture. In order to do this, this Social Web architecture necessary separates the underlying social platforms like social networking sites from the social applications that leverage the profile information these social platforms provide. If the frameworks described can be implemented, the distinction between social platforms and the social applications will become more and more blurry. Far from disappearing, the importance of the social platform as a central identity and privacy provider in the "cloud" that can provide access to ever-more social applications will become even more paramount. These open-ended and evolving social frameworks are the leap in allowing current social platforms to share their data with applications and other platforms in manner that allows them to gain maximum value from their user-base while avoiding liability of both content and privacy. With such a Social Web architecture in place, social application developers will be able to focus on their value proposition to users in terms of improved interfaces and services, and not low-level data management or be concerned about privacy.
Investigate Identity in the Browser
The increasing pressure from identity theft combined with movements by governments like the USA to establish national identity schemes gives special urgency for a secure and widely-used digital identity to be part of the Web. As mentioned earlier, the OpenID simplifications proposed by approaches like WebFinger (e-mails as identifiers) and OpenID Connect (building OpenID on top of OAuth) are likely help facilitate deployment of these technologies. All of these approaches rely on a common general pattern: a client authenticates with a trusted server using some client-side authentication mechanism (commonly a user-name and a password), and then the server then can access social services on behalf of the authenticated user. The weak spot of any single username-password login is the authentication of the user to the server. As noted by Ben Laurie, the user could be redirected to a malicious site that spoofed an identity provider and hence intercepting a user's credentials without the user noticing. This is currently tackled by secondary authentication such as SMS texting, but another approach that would be would be to look for Web for secondary authentication. Web-based client-side approaches, like using certificates, could help server-side identity providers like with secure user authentication. Furthermore, any approach should allow the user to easily setup their own server or use their browser as an identity provider, and provide a higher-level of security assurance as needed for government and e-commerce interactions. However, client-side approaches to identity have poor user experiences at the moment, partially because of lack of support within the browser and proposals in this space such as Infocard or WebID still are in need of more work. Lastly, the Web lacks Javascript APIs around identity, which limit deployment of even the best technical solutions. The W3C should use its role within the browser community to support the development of client-side approaches to identity to help browsers become full-fledged social agents while maintaining a decentralized approach to user-centric identity that fulfills the security requirements e-commerce, governments, and ordinary users.
The W3C should participate in Identity Commons and liaison with the OpenID Foundation, Infocard Foundations, and the Kantara Initiative on this front. User requirements should be gathered from governments and e-Commerce, and future W3C workshop(s) on client-oriented approaches should identify technical work and standardization that compliments the ongoing work in the digital identity community. The W3C should also incubate specific technical proposals for standardization that are simple enough to be widely deployed while taking security and privacy requirements on board.
Co-ordinate the Core of Profile Data
Users should be able to describe themselves in their profile without any technical restrictions imposed on them by social networking sites. Equally so, developers should be able to access the commonly-used core of profile data in an easy-to-use manner across different social networking sites and social platforms. For example, OpenID Connect reuses the same core, but makes a variation by using underscore instead of "camelCase". The core of vCard 4.0, PortableContacts, OpenSocial and FOAF should all be mappable to each other and use the same design pattern, regardless of the debates around underscore and "CamelCase". Also, the common core of names should be the same across XML, RDFa, and JSON serializations, and be the same across social APIs. The W3C DAP Working Group is already pursuing this coordination. At the same point, the common core must be extensible and not make arbitrary limits on how users identify themselves and must be able to handle international differences, such as internationalized names. Therefore, we also suggest that this core be reviewed for internationalization by the W3C. Also, we suggest that a common and decentralized extension mechanism be chosen based on a combination of a registry of strings and encouraging the use of URIs for decentralized extensibility. Developers should be able to access profile data across various social APIs in a consistent manner for the core, but in a way that is extensible and internationalized.
Combining Social Media and the Semantic Web
Social media on the Web is one of the most under-developed areas as regards functionality and standards. Social media should be portable, and allow licensing and usage information to "move" with social data that is cut and pasted across media. The general trend towards portable metadata for social media is a golden opportunity for the Semantic Web. However, the Semantic Web overall has a number of problems that are leading to its lack of uptake by developers to use. RDF currently has no standard way of inter-operating with Atom and JSON, the primary dataformats of the Social Web. The core architecture of RDF also does not support provenance and the expression of rules in RDF, which are crucial for Social Web use-cases. There is also a practical issue with the Semantic Web, namely that it is impossible to locate URIs and vocabularies for kinds of social media that users want to find. Microformats and the Open Graph Protocol have succeed to the point because not only are they easy to use, but also specify in a easy-to-find way the kinds of semantics, at this point it should be noted that the Open Graph Protocol makes use of RDFa to add markup to webpages. While vocabulary hosting services are already available, Semantic Web users need easy ways to identify and build vocabularies. That can be done for instance through a central vocabulary hosting hosting and management site, possibly managed by the W3C or some other neutral body, that allows users to register and create new vocabularies with a well-defined process, or at least through a vocabulary listing website, used to identify vocabularies available on the Web, with their core characteristics (last activity date, etc.). Lastly, the issue of expressing licensing information for social media and Web-based micropayments for social media should be investigated. In order for these approaches to take off and to enable "cut-and-paste" of social media, browser vendors should be involved as early as possible. The W3C community should explore incubator groups around ODRL and Webpayments.
Re-engage Privacy Activity Focusing on the Social Web
As the privacy crisis of 2010 (over Google Buzz and the Facebook privacy settings) and various empirical studies have shown, the users want to have control of their privacy, and the W3C needs to take a position of leadership in this area. Previous attempts by the W3C in this area such as P3P and POWDER have not been successful. The three main issues were complexity, lack of enforcement, and lack of economic incentives for Web site operators.
There is no clear technical approach to privacy that is technically agreed upon, although elements such as public-key encryption do exist. However, users should at least be able to express their privacy preferences and be alerted to possible violations. No simple logic and proof-based system by itself will be usable, simply because it will be far too complicated (even more so than P3P) for ordinary users and developers. Work on simplified sets of common privacy settings - as exemplified by Mozilla Privacy Icons and Privacy rule-sets - are a way forward to reduce complexity to a level that users and developers can use. The second issue however, is one of enforcement. While embedding privacy icons in a browser may help, it is not enough, and technical approaches can only work with existing social approaches. For example, a consortium of government officials and lawyers with an specialized in privacy could map out how the use of these common privacy settings can be legally enforced and then set up a "preserve privacy" initiative (similar to the "Stop Badware" initiative Stop Badware) to crowd-source privacy violations. The main objection to this could be commercial, namely that it would discourage the use of data by sites, although by letting such a scheme be opt-in, it would provide new markets for privacy-aware users and also let companies have a healthier relationship with legal privacy regulations by providing them basic protection around issues of privacy and rights to data. Such combinations of technical and social mechanisms should be actively investigated by the W3C.
Despite the complexity of the issue of privacy on the Social Web, the time for action is now. User privacy is of utmost importance, and the W3C should invest in full-time resources to create an over-arching privacy activity to inspect all W3C Recommendations and Web technologies in general for privacy violations.
Support the Federated Social Web
One of the most inspiring developments was the creation of a test-driven approach towards creating a federated Social Web over the last year. If successful, this very practical approach will create interoperability among code-bases. It recognizes that many of the Social Web specifications are still experimental and the code-bases are mostly still a work in development, but is nonetheless it could be the crucial element to getting a decentralized and privacy-enhanced Social Web working. At the Federated Social Web Summit, the first Social Web Acid Test (SWAT0) of sharing a tagged photo across multiple social networking sites was produced. However, as many of the core individuals that have supported a decentralized Social Web based on open standards are now quite busy with other work, it would be important for the W3C to offer its resources to the Federated Social Web effort in order to help this effort succeed. Ideally, W3.org itself should become a node in a federated social network, allowing social features (blog-comments, tweets, status-updates) to improve the social interactions around specification development itself. So while the W3C should not favor any one particular technology or standard in this space, but at this early stage should a Federated Social Web Incubator Group would be the next step.
Open the World Wide Web Consortium
The World Wide Web originally became successful as the Web was build on standards that were given to the world on a royalty-free basis, allowing the Web to be implemented over different underlying systems. There is no reason to believe that the Social Web will be any different. In this regard, assuring that the standards that can serve as the foundation of the Social Web can be genuinely open, which means that they can implemented on a royalty-free basis guaranteed by patent non-assertion agreements. Simply branding something "open" is no longer enough. The progress of the Open Web Foundation License in allowing individual authors and organizations to sign patent non-assertions is a vital key to allow specifications to be written in a more "open-source" process. In order to allow the decentralized Social Web to reach maturity, the World Wide Web Consortium should offer its resources to the wider Social Web community. However, the World Wide Web Consortium has a number of structural issues with its current standardization process. While to a large extent the value proposition on the World Wide Web Consortium consists not only in its resources and well-defined process, but also in the fact that it can get the consortium members, often large companies, to agree to a royalty-free patent policy. The Social Web Incubator Group supports the creation of the Community Group process that lets individuals participate in the experimental stage of a standards process and supports the existence of a clear path from individuals giving Open Web Foundation licenses to their specifications to these specifications becoming W3C Royalty-Free Recommendations. This should decentralize the standardization process of the W3C to allow more standards to emerge from the grassroots and harness the collective intelligence of the Web in a more effective manner. The Web is increasingly the Social Web, and together with wider eco-system of the Web itself, the W3C can help lead the Social Web to its full potential.
Acknowledgements
This document is the product of the Social Web (SWXG) Incubator Group. At the time of publication, the active members of the Social Web Incubator Group included Tim Anglade, Daniel Appelquist, Dan Brickley, Melvin Carvalho, Venezia Claudio, Harry Halpin, Renato Iannella, Toby Inkster, Alexandre Passant, Christine Perey, Ronald Reck, Ted Thibodeau, Mischa Tuffield, Oshani Seneviratne, Henry Story, Fabien Gandon, and Paul Trevithick. This report is dedicated to the memory of Peter Ferne, who participated in the Social Web Incubator Group. The group would like to thank the following people who we consulted with over the lifetime of the Social Web Incubator Group in order to make this final report: Robin Berjon, Tim Berners-Lee (MIT), Joseph Bonneau (Cambridge), Marcos Caceres (Opera), Michael Cooper (W3C), Sam Critchley (Gypsii), Anita Doehler (Vodafone), Nathan Eagle (MIT), Kaliya Hamlin (Identity Commons), Michael Hanson (Mozilla), Dick Hardt (OpenID Foundation), Eran Hammer-Lahav (Yahoo!), Yolanda Gil (USc), Paul Groth (Vrije University Amsterdam ), Lalana Kagal (MIT), Ros Lawler (Random House), Matt Lee (Free Software Foundation), Chris Messina (Google), Alexandre Monnin (Sorbonne), Soren Preibusch (Cambridge), Evan Prodromou (Status.Net), David Raggett (W3C), Aza Raskin (Mozilla), David Recordon (Facebook), Gregory Rosmaita, Janina Sajka (Web Accessibility Initiative), Luke Shepard (Facebook), Joseph Smarr (Google), Manu Sporny (Digital Bazaar), Peter St. Andre (Cisco), Simon Tenant, and Slim Trabelsi (SAP). We also gratefully received and incorporated comments from J. Trent Adams (ISOC), Jon Bradley (OpenID Foundation), Joni Brennan (Kantara Initiative), John Bradley (OpenID Foundation), and Brian Kissel (OpenID Foundation). Finally, the W3C would like to thank Eduserv for providing a W3C Fellowship for Harry Halpin.
References
- [BAD]
- Stop Badware 26th October 2010. Available at http://stopbadware.org/
- [PRIVICON]
- Pirvacy Icons 26th October 2010. Available at https://wiki.mozilla.org/Drumbeat/Challenges/Privacy_Icons
- [GRDDL]
- GRDDL 26th October 2010. Available at http://www.w3.org/2004/01/rdxh/spec
- [OPENSOCIAL]
- GRDDL 26th October 2010. Available at https://code.google.com/apis/opensocial/
- [CLASS]
- Classmates.com 26th October 2010. Available at http://www.classmates.com/
- [COMM]
- Community Group 26th October 2010. Available at http://www.w3.org/2010/07/community
- [FED]
- Federated Social Web Summit 26th October 2010. Available at http://federatedsocialweb.net/
- [FOAF]
- Friend-of-a-Friend project Dan Brickley & Libby Miller 26th October 2010. Available at http://www.foaf-project.org/
- [GERMANLAW]
- Germany Goes After Facebook Over Privacy Law, Deutsche Presse Agentur. July 2010. Available at http://www.monstersandcritics.com/news/europe/news/article_1569169.php/Facebook-faces-inquiry-fine-by-German-privacy-official
- [IDLEXICON]
- Identity Commons Lexicon, Identity Commons. Updated continuously. Available at http://wiki.idcommons.net/Lexicon.
- [MAP]
- Map of Geolocations 26th October 2010. Available at http://www.vincos.it/wp-content/uploads/2009/06/wmsn-06-09.png
- [MSNWS]
- W3C Workshop on the Future of the Social Networking 26th October 2010. Available at http://www.w3.org/2008/09/msnws/
- [OGP]
- Facebook OpenGraphProtocol 26th October 2010. Available at http://opengraphprotocol.org/
- [OPENGRAPH]
- Thoughts on the Social Graph, Brad Fitzpatrick, David Recordon. August 2007. Available at http://bradfitz.com/social-graph-problem/.
- [OSLO]
- the OSLO alliance 26th October 2010. Available at http://groups.google.com/group/locallies
- [P3P]
- The Platform for Privacy Preferences 1.1 (P3P1.1) Specification, W3C Working Group Note, 13 November 2006. Available at http://www.w3.org/TR/P3P11/
- [PEW]
- Teens, Privacy and Online Social Networks , 2010. Available at http://www.pewinternet.org/Reports/2007/Teens-Privacy-and-Online-Social-Networks.aspx
- [ODRL]
- ODRL Version 2.0 Working Group - Model, Vocabulary, Encoding Documents, 2010. Available at http://odrl.net/2.0/
- [RFC-3987]
- RFC 3987 - Internationalized Resource Identifiers (IRIs), M. Duerst and M. Suignard, IETF, January 2005. This document is http://www.ietf.org/rfc/rfc3987.txt.
- [RIF-RDF+OWL]
- RIF RDF and OWL Compatibility, de Bruijn, J. (Editor), W3C Rule Interchange Format Working Group Draft. Latest Version available at http://www.w3.org/2005/rules/wiki/SWC.
- [THEWELL]
- The Epic Saga of The Well, Katie Hafner, Wired Magazine 5.05, May 1997. Available at http://www.wired.com/wired/archive/5.05/ff_well.html
- [XML-SCHEMA2]
- XML Schema Part 2: Datatypes, W3C Recommendation, World Wide Web Consortium, 2 May 2001. This version is http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/. The latest version is available at http://www.w3.org/TR/xmlschema-2/.
- [SCOBLE]
- Facebook Disabled My Account, Robert Scoble. January 2008. Available at http://scobleizer.com/2008/01/03/ive-been-kicked-off-of-facebook/.
- [sgapi]
- Thoughts on the Social Graph Brad Fitzpatrick 26th October 2010. Available at http://bradfitz.com/social-graph-problem/
- [TBL1989]
- Tim Berners-Lee in his original 1989 proposal to create the World Wide Web Tim Berners-Lee 26th October 2010. Available at http://www.w3.org/History/1989/proposal.html
- [tbl2010]
- Socially Aware Cloud Computing Tim Berners-Lee 26th October 2010. Available at http://www.w3.org/DesignIssues/CloudStorage.html
- [TRIG]
- TriG 26th October 2010. Available at http://www4.wiwiss.fu-berlin.de/bizer/TriG/
- [URI]
- URIs IETF 26th October 2010. Available at http://www.ietf.org/rfc/rfc3986.txt
- [USA]
- US national identity scheme 26th October 2010. Available at http://www.nstic.ideascale.com/
- [VCARD4]
- vCard Format Specification, S. Perreault & P. Resnick, 2 August 2010. Available at http://tools.ietf.org/html/draft-ietf-vcarddav-vcardrev-13
- [VCARD3]
- vCard version 3.0, 26 Oct 2010. Available at http://hypercontent.sourceforge.net/docs/manual/develop/vcard.html
- [VCARD4XML]
- vCard XML Representation, S. Perreault, 2 August 2010. Available at http://www.ietf.org/id/draft-ietf-vcarddav-vcardxml-05.txt
- [VCARDRDF]
- Representing vCard Objects in RDF, Harry Halpin & Renato Iannella & Brian Suda & Norman Walsh, 20 January 2010. Available at http://www.w3.org/Submission/vcard-rdf/
- [W3CACWORKSHOP]
- W3C Workshop on Access Control Application Scenarios - Position Papers, 17 - 18 November 2009, Luxembourg. Available at http://www.w3.org/2009/policy-ws/papers/
- [FF]
- FriendFeed 26th October 2010. Available at http://friendfeed.com/
- [PLAXO]
- Plaxo 26th October 2010. Available at http://www.plaxo.com/
- [DAPPRIVACY]
- DAP Privacy 26th October 2010. Available at http://www.w3.org/2010/api-privacy-ws/papers/privacy-ws-1.pdf
- [FBML]
- Facebook and FBML 26th October 2010. Available at http://developers.facebook.com/docs/reference/fbml/
- [CAM]
- technical and economic drawbacks 26th October 2010. Available at http://preibusch.de/publ/password_market/
- [WEAVE]
- Weave project 26th October 2010. Available at http://mozillalabs.com/sync/how-do-i-get-started-using-weave/
- [OAUTH]
- OAuth 26th October 2010. Available at http://oauth.net/core/1.0a
- [OAUTH2]
- OAuth 2.0 26th October 2010. Available at http://tools.ietf.org/html/draft-ietf-oauth-v2-10
- [OPENID]
- OpenID 26th October 2010. Available at http://openid.net/developers/specs/
- [PHISH]
- Phishing 26th October 2010. Available at http://www.links.org/?p=187
- [OPENID-CONNECT]
- OpenID Connect 26th October 2010. Available at http://openidconnect.com/
- [WEBID]
- WebID 26th October 2010. Available at http://webid.info/spec/
- [NIGORI]
- Nigori 26th October 2010. Available at http://www.links.org/files/nigori-protocol.html
- [INFOCARD]
- Infocard 26th October 2010. Available at http://informationcard.net/.
- [HIGGINS]
- Higgins Project 26th October 2010. Available at http://higgins-project.org/
- [XAUTH]
- XAuth 26th October 2010. Available at http://xauth.org/spec/
- [XRD]
- XRD 26th October 2010. Available at http://docs.oasis-open.org/xri/xrd/v1.0/xrd-1.0.html
- [RDDL]
- RDDL 26th October 2010. Available at http://www.rddl.org/
- [HCARD]
- hCard microformat 26th October 2010. Available at http://microformats.org/wiki/hcard
- [FOAF]
- FOAF project 26th October 2010. Available at http://foaf-project.org
- [SIOC]
- SIOC 26th October 2010. Available at http://sioc-project.org
- [PORT]
- PortableContacts 26th October 2010. Available at http://portablecontacts.net/draft-spec.html
- [CFC]
- shows 26th October 2010. Available at http://www.w3.org/2009/dap/wiki/ContactFormatsComparison
- [SHIN]
- Shindig 26th October 2010. Available at http://shindig.apache.org/
- [WIDGETS]
- W3C Widgets from the Web App WG 26th October 2010. Available at http://www.w3.org/2008/webapps/
- [DELI]
- Delicious 26th October 2010. Available at http://del.icio.us
- [TAGONT]
- TagOntology 26th October 2010. Available at http://www.holygoat.co.uk/projects/tags/
- [MICROF]
- Microformats 26th October 2010. Available at http://microformats.org/
- [OPEN]
- Open Graph Protocol 26th October 2010. Available at http://opengraphprotocol.org/
- [LIKEB]
- Blocking the Facebook Like Button 26th October 2010. Available at http://mmt.me.uk/blog/2010/07/30/the-facebook-like-button/
- [PAYS]
- PaySwarm 26th October 2010. Available at http://payswarm.com/
- [MICROP]
- micropayment activity 26th October 2010. Available at http://www.w3.org/ECommerce/Micropayments/
- [OEX]
- OExchange 26th October 2010. Available at http://www.oexchange.org/
- [W3CPROV]
- W3C Provenance Incubator Group 26th October 2010. Available at http://www.w3.org/2005/Incubator/prov/
- [FACEBW]
- Facebook‚Äö Its Gone Rogue It's Time for an Open Alternative 26th October 2010. Available at http://www.wired.com/epicenter/2010/05/facebook-rogue/
- [FBPRIV]
- News articles 26th October 2010. Available at http://www.nytimes.com/interactive/2010/05/12/business/facebook-privacy.html
- [FBOG]
- Facebook's Opengraph 26th October 2010. Available at http://zestyping.livejournal.com/257224.html
- [JUNG]
- The Privacy Jungle: On the Market for Data Protection in Social Networks 26th October 2010. Available at http://preibusch.de/publications/Bonneau_Preibusch__Privacy_Jungle__2009-05-26.pdf
- [P3P]
- P3P 26th October 2010. Available at http://www.w3.org/P3P/
- [POWDER]
- POWDER 26th October 2010. Available at http://www.w3.org/TR/powder-primer/
- [AIR]
- AIR 26th October 2010. Available at http://dig.csail.mit.edu/2009/AIR/
- [XACML]
- XACML 26th October 2010. Available at http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=xacml
- [RIF]
- RIF 26th October 2010. Available at http://www.w3.org/TR/rif-overview/
- [W3PRIVWORK]
- workshop in 2010 26th October 2010. Available at http://www.w3.org/2010/api-privacy-ws/report.html
- [ODRL]
- The Open Digital Rights Language (ODRL) Initiative 26th October 2010. Available at http://odrl.net/
- [XMPP]
- XMPP 26th October 2010. Available at http://www.ietf.org/rfc/rfc3920.txt
- [OSW]
- OneSocialWeb 26th October 2010. Available at http://onesocialweb.org/
- [ATOM]
- Atom 26th October 2010. Available at http://www.ietf.org/rfc/rfc4287.txt
- [RSSC]
- RSSCloud 26th October 2010. Available at http://rsscloud.org/
- [ACTS]
- API 26th October 2010. Available at http://activitystrea.ms/head/activity-api.html
- [SALM]
- Salmon Protocol 26th October 2010. Available at http://salmon-protocol.googlecode.com/svn/trunk/draft-panzer-salmon-00.html
- [GSTD]
- Google and the use of open standards 26th October 2010. Available at http://blog.jclark.com/2010/02/tour-of-open-standards-used-by-google.html
- [OSTAT]
- OStatus 26th October 2010. Available at http://ostatus.org/specification
- [ARIA]
- ARIA 26th October 2010. Available at http://www.w3.org/TR/wai-aria/
- [ACCTW]
- AccessibleTwitter 26th October 2010. Available at http://www.accessibletwitter.com
- [STATNET]
- Status.net 26th October 2010. Available at http://status.net/
- [GNUS]
- GNU Social 26th October 2010. Available at http://www.gnu.org/software/social/
- [HIGGP]
- Higgins Project 26th October 2010. Available at http://eclipse.org/higgins/
- [DIAS]
- Diaspora project 26th October 2010. Available at http://www.joindiaspora.com/
- [DISO]
- Diso project 26th October 2010. Available at http://diso-project.org/
- [SMOB]
- Semantic MicroBlogging 26th October 2010. Available at http://smob.me/
- [APPLES]
- Appleseed 26th October 2010. Available at http://opensource.appleseedproject.org/
- [OPENLDS]
- OpenLink Data Spaces 26th October 2010. Available at http://ods.openlinksw.com/wiki/ODS/
- [VRM]
- VRM 26th October 2010. Available at http://www.vrm.org
- [METR]
- metrics 26th October 2010. Available at http://www.w3.org/2005/Incubator/socialweb/wiki/images/f/f2/Social_networking_metrics_July_2009.pdf
- [EBAY]
- eBay 26th October 2010. Available at http://www/ebay.com
- [MEETM]
- MeetMoi 26th October 2010. Available at http://www.meetmoi.com/
- [SIXD]
- SixDegrees 26th October 2010. Available at http://www.sixdegrees.com/
- [LG]
- LiveJournal 26th October 2010. Available at http://www.livejournal.com/
- [INDY]
- Indymedia 26th October 2010. Available at http://www.indymedia.org/
- [FFST]
- Friendster 26th October 2010. Available at http://www.friendster.com/
- [LKDIN]
- LinkedIn 26th October 2010. Available at http://www.linkedin.com/
- [MYSPACE]
- MySpace 26th October 2010. Available at http://www.myspace.com/
- [ORK]
- Orkut 26th October 2010. Available at http://www.orkut.com/
- [FB]
- Facebook 26th October 2010. Available at http://www.facebook.com
- [FLR]
- Flickr 26th October 2010. Available at http://www.flickr.com/
- [YOU]
- Youtube 26th October 2010. Available at http://www.youtube.com/
- [TWT]
- Twitter 26th October 2010. Available at http://twitter.com
- [HI5]
- Hi5 26th October 2010. Available at http://hi5.com/
- [QQ]
- QQ 26th October 2010. Available at http://www.qq.com/
- [GOOG]
- Google 26th October 2010. Available at http://www.google.com/
- [YAH]
- Yahoo! 26th October 2010. Available at http://www.yahoo.com
- [YTHREE]
- Yahoo! 360 26th October 2010. Available at http://pulse.yahoo.com/
- [SW]
- Semantic Web 26th October 2010. Available at http://www.w3.org/2001/sw/
- [OPENI]
- OpenID 26th October 2010. Available at http://openid.net/
- [DP]
- DataPortability 26th October 2010. Available at http://www.dataportability.org/
- [DLF]
- Data Liberation Front 26th October 2010. Available at http://www.dataliberation.org/
- [FBTOS]
- Facebook's Terms of Service 26th October 2010. Available at http://www.tosback.org/diff.php?vid=1636
- [GOOGFC]
- Google FriendConnect 26th October 2010. Available at http://www.google.com/friendconnect/
- [GMAIL]
- Gmail 26th October 2010. Available at http://gmail.com
- [HTML]
- HTML 26th October 2010. Available at http://www.w3.org/html/wg/
- [TWAUTH]
- Twitter and Twitter OAuth 26th October 2010. Available at http://apiwiki.twitter.com/
- [PASSW]
- How to implement good password schemes 26th October 2010. Available at http://www.lightbluetouchpaper.org/2010/07/29/web-password-standards-2/
- [MOSSYNC]
- Sync plugin 26th October 2010. Available at http://mozillalabs.com/sync/
- [SESS]
- session-fixation 26th October 2010. Available at http://oauth.net/advisories/2009-1/
- [OUATH1]
- OAuth 1.0a 26th October 2010. Available at http://oauth.net/core/1.0a
- [WEBF]
- Webfinger 26th October 2010. Available at http://code.google.com/p/webfinger/wiki/WebFingerProtocol
- [MS]
- Microsoft 26th October 2010. Available at http://www.microsoft.com/
- [WORDP]
- WordPress 26th October 2010. Available at http://wordpress.org/
- [FOAFS]
- foaf+ssl 26th October 2010. Available at http://esw.w3.org/foaf+ssl
- [INFOCARD]
- INFOCARD 26th October 2010. Available at http://www.w3.org/2005/Incubator/socialweb/wiki/FinalReport#infocard
- [IMI]
- IMI protocol 26th October 2010. Available at http://docs.oasis-open.org/imi/identity/v1.0/identity.html
- [CARDS]
- Cardspace 26th October 2010. Available at http://www.microsoft.com/windows/products/winfamily/cardspace/default.mspx
- [DIGIM]
- Digital Me 26th October 2010. Available at http://code.bandit-project.org
- [OINFO]
- OpenInfocard 26th October 2010. Available at http://code.google.com/p/openinfocard/
- [XAUTHC]
- XAuth is heavily centralized 26th October 2010. Available at http://hueniverse.com/2010/06/xauth-a-terrible-horrible-no-good-very-bad-idea/
- [XAUTHD]
- XAUTH Centralized 26th October 2010. Available at http://www.abstractioneer.org/2010/06/xauth-is-lot-like-democracy.html
- [MALI]
- Malicious Sites 26th October 2010. Available at http://www.links.org/?p=938
- [WELLKNOWN]
- .well-known 26th October 2010. Available at http://tools.ietf.org/html/draft-nottingham-site-meta-05
- [LRDD]
- LRDD 26th October 2010. Available at http://tools.ietf.org/html/draft-hammer-discovery-06#section-5
- [HOSTM]
- host-meta draft specification 26th October 2010. Available at http://tools.ietf.org/html/draft-hammer-hostmeta-13#appendix-B
- [IETFWL]
- IETF Web Linking specification 26th October 2010. Available at http://tools.ietf.org/html/draft-nottingham-http-link-header-10
- [CONC]
- Technical concerns presented on W3C Mailing list 26th October 2010. Available at http://lists.w3.org/Archives/Public/www-tag/2008May/0078.html
- [PT]
- Patent Policy, and patented technologies 26th October 2010. Available at http://danbri.org/words/2008/01/29/266
- [JRD]
- JRD 26th October 2010. Available at http://hueniverse.com/2010/05/jrd-the-other-resource-descriptor/
- [XHTMLF]
- XHTML Friends Microformat 26th October 2010. Available at http://gmpg.org/xfn/
- [XFN]
- XFN 26th October 2010. Available at http://gmpg.org/xfn/11
- [LNKD]
- Linked Data 26th October 2010. Available at http://www.w3.org/DesignIssues/LinkedData.html
- [DRUP]
- Drupal7 26th October 2010. Available at http://drupal.org
- [SMOB]
- SMOB 26th October 2010. Available at http://smob.me
- [LASTF]
- last.fm 26th October 2010. Available at http://http://dbtune.org/last-fm/
- [PRESO]
- Online Presence Ontology 26th October 2010. Available at http://online-presence.net
- [RELVO]
- Relationship vocabulary 26th October 2010. Available at http://vocab.org/relationship
- [WOOKIE]
- Apache Wookie project 26th October 2010. Available at http://incubator.apache.org/wookie/
- [webapps]
- WebApps 26th October 2010. Available at http://www.w3.org/2008/webapps/
- [RELTAG]
- rel:tag microformat 26th October 2010. Available at http://microformats.org/wiki/rel-tag
- [SCOT]
- SCOT 26th October 2010. Available at http://scot-project.org
- [MOAT]
- MOAT 26th October 2010. Available at http://moat-project.org
- [NICT]
- NiceTag 26th October 2010. Available at http://ns.inria.fr/nicetag/2010/09/09/voc#
- [HREV]
- hReview 26th October 2010. Available at http://microformats.org/wiki/hreview
- [MICRODATA]
- microdata 26th October 2010. Available at http://dev.w3.org/html5/md/
- [GOOGRS]
- Google Rich Snippets 26th October 2010. Available at http://www.google.com/webmasters/tools/richsnippets
- [GOOGS]
- Statistics regarding rich snippets 26th October 2010. Available at http://www.readwriteweb.com/archives/google_semantic_web_push_rich_snippets_usage_grow.php
- [IMDB]
- IMDB 26th October 2010. Available at http://www.imdb.com/
- [ROTT]
- Rotten Tomatoes 26th October 2010. Available at http://www.rottentomatoes.com/
- [CNN]
- CNN 26th October 2010. Available at http://www.cnn.com/
- [OLIKE]
- OpenLike 26th October 2010. Available at http://openlike.org/
- [OWF]
- OWF 26th October 2010. Available at http://www.openwebfoundation.org/
- [USEC]
- use-cases 26th October 2010. Available at http://www.w3.org/2005/Incubator/prov/wiki/Social_Web
- [TOSB]
- Terms of Service Tracker 26th October 2010. Available at http://www.tosback.org/timeline.php
- [BIRD]
- PrivacyBird 26th October 2010. Available at http://www.privacybird.com/
- [PRIME]
- PrimeLife Project 26th October 2010. Available at http://www.primelife.eu/
- [ODRL2]
- ODRL 2.0 26th October 2010. Available at http://odrl.net/2.0/DS-ODRL-Model.html
- [ODRLXML]
- ODRL XML 26th October 2010. Available at http://odrl.net/2.0/WD-ODRL-XML.html.
- [RULESET]
- Privacy Ruleset 26th October 2010. Available at http://dev.w3.org/2009/dap/privacy-rulesets/
- [DAPWG]
- W3C DAP WG 26th October 2010. Available at http://dev.w3.org/2009/dap/
- [ODRLU]
- The use cases in the ODRL language 26th October 2010. Available at http://odrl.net/wiki/tiki-index.php?page=W3C+Privacy+Rulesets
- [PLUS]
- PLUS Coalition 26th October 2010. Available at http://www.useplus.com/
- [ACAP]
- ACAP (Automated Content Access Protocol) 26th October 2010. Available at http://www.the-acap.org/
- [JABBER]
- Jabber community 26th October 2010. Available at http://www.jabber.org
- [XMPP2]
- XMPP technology stack 26th October 2010. Available at http://xmpp.org/xsf/
- [GTALK]
- GTalk 26th October 2010. Available at http://www.google.com/talk/
- [PIDGIN]
- Pidgin 26th October 2010. Available at http://www.pidgin.im/
- [PUBSUBXMPP]
- XMPP Pubsub 26th October 2010. Available at http://xmpp.org/extensions/xep-0060.html
- [STATUS]
- status.net 26th October 2010. Available at http://status.net/
- [JSON]
- JSON serialization 26th October 2010. Available at http://activitystrea.ms/head/json-activity.html
- [OPERA]
- Opera 26th October 2010. Available at http://www.opera.com/
- [BBC]
- BBC 26th October 2010. Available at http://www.bbc.co.uk/
- [MAGIC]
- Magic Signatures 26th October 2010. Available at http://salmon-protocol.googlecode.com/svn/trunk/draft-panzer-magicsig-00.html
- [RFC3447]
- RFC 3447 26th October 2010. Available at http://tools.ietf.org/html/rfc3447
- [XMLDS]
- XML Digital Signatures 26th October 2010. Available at http://www.w3.org/TR/xmldsig-core/
- [ECHO]
- Echofon 26th October 2010. Available at http://www.echofon.com/
- [QT]
- Qwitter 26th October 2010. Available at http://qwitter-client.net/
- [GNULIST]
- List of Project on the GNUSocial Site 26th October 2010. Available at http://gitorious.org/social/pages/ProjectComparison
- [IDENTICA]
- identi.ca 26th October 2010. Available at http://identi.ca
- [FSF]
- Free Software Foundation (FSF) 26th October 2010. Available at http://www.fsf.org/
- [XMPP]
- XMPP 26th October 2010. Available at http://xmpp.org/
- [ASXMPP]
- ActivityStreams over XMPP 26th October 2010. Available at http://onesocialweb.org/spec/1.0/osw-activities.html
- [VCARDXMPP]
- vCard4 over XMPP 26th October 2010. Available at http://onesocialweb.org/spec/1.0/osw-vcard4.html
- [SR]
- Social Relationships 26th October 2010. Available at http://onesocialweb.org/spec/1.0/osw-relations.html
- [PEP]
- Personal Eventing Protocol 26th October 2010. Available at http://onesocialweb.org/spec/1.0/osw-inbox.html
- [PDM]
- Personal Data Model Details 26th October 2010. Available at http://wiki.eclipse.org/Persona_Data_Model_2.0
- [WP]
- WordPress 26th October 2010. Available at http://wordpress.org/
- [MOVET]
- Movable Type 26th October 2010. Available at http://www.movabletype.org/
- [RDF]
- RDF 26th October 2010. Available at http://www.w3.org/RDF/
- [CTAG]
- CommonTag 26th October 2010. Available at http://www.commontag.org/Home
- [FEBSUMMIT]
- Federated Social Web Submit in 2010 26th October 2010. Available at http://federatedsocialweb.net/wiki/Federated_Social_Web_Summit_2010
- [UMA]
- UMA 26th October 2010. Available at http://kantarainitiative.org/confluence/display/uma/Home
- [NORI]
- project Nori 26th October 2010. Available at http://www.projectnori.org/
- [FBPROFIT]
- Facebook declared that it had reached break even and was running profitably 26th October 2010. Available at http://techcrunch.com/2009/09/15/facebook-crosses-300-million-users-oh-yeah-and-their-cash-flow-just-went-positive/
- [INSIDEFB]
- InsideFacebook blog 26th October 2010. Available at http://www.insidefacebook.com/2010/03/02/facebook-made-up-to-700-million-in-2009-on-track-towards-1-1-billion-in-2010/
- [FLIRT]
- Flirtomatic 26th October 2010. Available at http://www.flirtomatic.com/
- [FSC]
- FunkySexyCool 26th October 2010. Available at http://www.funkysexycool.com/
- [GREE]
- Gree 26th October 2010. Available at http://gree.jp/
- [MIXI]
- Mixi 26th October 2010. Available at http://mixi.jp/
- [MOBAGE]
- Mobagetown 26th October 2010. Available at http://www.mbga.jp/
- [LAURIE]
- Ben Laurie 26th October 2010. Available at http://www.links.org/?p=187
- [NQUADS]
- N-Quads 26th October 2010. Available at http://sw.deri.org/2008/07/n-quads/
- [VOCHOST]
- Vocabulary Hosting 26th October 2010. Available at http://www.aaai.org/ocs/index.php/SSS/SSS10/paper/download/1140/1450
- [ACID]
- Social Web Acid Test 26th October 2010. Available at http://federatedsocialweb.net/wiki/SWAT0